

hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录:
Hadoop三种安装模式
搭建伪分布式集群准备条件
第一部分 安装前部署
1.查看虚拟机版本
2.查看IP地址
3.修改主机名为hadoop
4.修改 /etc/hosts
5.关闭防火墙
6.关闭SELINUX
7.安装yum源并安装基础包
8.关闭不必要的服务
9.安装Java环境
第二部分 Hadoop正式安装
1.安装Hadoop
2.修改hadoop的5个配置文件
3.解决互信问题
第三部分 启动Hadoop集群
1.格式化NameNode
2.启动Hadoop集群
3.验证集群是否启动成功
4.关闭hadoop集群
5.登录HDFS管理界面:http://ip:50070
6.登录MR管理界面: http://ip:8088
第四部分 一些问题?
1.启动Hadoop集群报错:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2.启动Hadoop集群报错:Attempting to operate on hdfs namenode as root but there is no HDFS_NAMENODE_USER defined. Aborting operation.
3.启动hadoop后无法访问50070端口
4.Hadoop集群启动后,使用jps查看没有DataNode进程?
Hadoop三种安装模式
1.Hadoop单机模式
单机模式是Hadoop默认的安装模式,这种安装模式主要就是并不配置更多的配置文件,只是保守的去设置默认的几个配置文件中的初始化参数,他并不与其他节点进行交互,并且也不使用HDFS文件系统,它主要就是为了调试MapReduce程序而生。
2.Hadoop伪分布式安装模式
Hadoop伪分布式安装,需要配置5个常规的配置文件(XML),并且这里涉及到了NameNode和DataNode节点交互问题,而且NameNode和DataNode在同一个节点上,还需要配置互信。其实从严格意义上来讲,我们的伪分布式集群,就已经可以称之为真正意义上的集群了,而且这里也包含了hdfs和MapReduce所有组件,只不过就是所有组件在同一个节点上而已。
3.Hadoop完全分布式安装模式
Hadoop完全分布式集群主要分为:常规Hadoop完全分布式集群和Hadoop HA集群(这里我们主要针对的是NameNode个数和NameNode的高可用保障机制而言)。由此可知较伪分布式集群而言,我们的完全分布式集群,所有处理节点并不在同一个节点上,而是在多个节点上。
那么我们如何搭建一个伪分布式集群呢?
我们要准备好以下条件:
1.我们的机器上需要安装VM虚拟软件
我安装的是VMware Workstation 11,安装方式大家可自行百度。
2.在虚拟软件上安装Linux(RHEL CENTOS UBUNTU...)
我安装的是Centos 7,安装方式可参考这里
3.配置好我们的java环境
Hadoop毕竟是Java程序的集合,所以在安装Hadoop软件之前,我们必须配置好Java环境。我安装的的是jdk1.8版本。
4.安装HADOOP并做相应配置
我安装的是hadoop-3.1.0.tar.gz
这真是我踩过的一个大坑,当我好不容易安装了hadoop-3.1.0之后,再安装hbase时,发现竟然hadoop-3.1.0不支持任何版本的hbase。。。。好心塞啊,所以大家如果想要后期学习hbase的话,还是建议不要安装这个版本的hadoop了,最好安装hadoop-2.7.1+版本,因为它支持所有的hbase版本。具体看这里。
当然下面的步骤同样适应于hadoop-2.7.7版本的安装,其中有些微小的区别我也已经作了说明。
第一部分 安装前部署
首先,我们使用xshell远程连接我们的虚拟机,最好用root用户登录。
1.可以通过如下三个命令查看我们安装的虚拟机版本
[root@localhost ~]# cat /etc/issue #不知为什么我的虚拟机显示\S,正常情况下应该显示版本信息。 \S Kernel \r on an \m [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core) [root@localhost ~]# cat /etc/system-release CentOS Linux release 7.5.1804 (Core)
2.通过 ip addr 可以查看虚拟机的IP地址。注意:centos 7换了查看IP地址的命令【ifconfig==>ip】
这里推荐2篇参考博文:
(1)ifconfig: command not found(CentOS专版,其他的可以参考)
(2)Centos 7 系统安装完毕修改网卡名为eth0
[root@hadoop ~]# ifconfig -bash: ifconfig: command not found [root@hadoop ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:bd:97:52 brd ff:ff:ff:ff:ff:ff inet 192.168.42.134/24 brd 192.168.42.255 scope global noprefixroute dynamic eth0 valid_lft 1506sec preferred_lft 1506sec inet6 fe80::b46e:fbba:4f30:8322/64 scope link noprefixroute valid_lft forever preferred_lft forever
3.修改主机名为hadoop。方法:修改配置文件 /etc/hostname 保存退出
[root@localhost ~]# hostname localhost.localdomain [root@localhost ~]# cat /etc/hostname localhost.localdomain [root@localhost ~]# vi /etc/hostname [root@localhost ~]# cat /etc/hostname hadoop [root@localhost ~]# reboot ----------重启后---------- [root@hadoop ~]# hostname hadoop
注意:网上还有一种普遍的方式修改Linux主机名(点这里),但是测试之后发现在centos 7根本不生效,我估计这种方式可能是仅适用于低版本的Linux。


[root@localhost ~]# hostname localhost.localdomain [root@localhost ~]# cat /etc/sysconfig/network # Created by anaconda [root@localhost ~]# vi /etc/sysconfig/network [root@localhost ~]# cat /etc/sysconfig/network # Created by anaconda NETWORKING=yes HOSTNAME=hadoop [root@localhost ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 [root@localhost ~]# vi /etc/hosts [root@localhost ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost hadoop localhost6 localhost6.localdomain6 [root@localhost ~]# reboot -------重启后---------- [root@localhost ~]# hostname localhost.localdomain 这种方法在centos 7完全没用!!!!!!!!!
4.修改 /etc/hosts。
先vi /etc/hosts打开文件,再在最后一行加入:IP地址 主机名
如果不知道自己虚拟机的IP地址,可以ip addr查看。注意:CentOS后来换指令了【ifconfig==>ip】
如果不知道自己的主机名,可以hostname查看。
[root@hadoop ~]# ip addr #查看IP地址 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:bd:97:52 brd ff:ff:ff:ff:ff:ff inet 192.168.42.134/24 brd 192.168.42.255 scope global noprefixroute dynamic eth0 valid_lft 1542sec preferred_lft 1542sec inet6 fe80::b46e:fbba:4f30:8322/64 scope link noprefixroute valid_lft forever preferred_lft forever [root@hadoop ~]# hostname #查看主机名 hadoop
[root@hadoop ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 [root@hadoop ~]# vi /etc/hosts [root@hadoop ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.42.134 hadoop
5.关闭防火墙(参考这里)。
首先安装iptables服务:yum install iptables-services
关闭防火墙:/bin/systemctl stop iptables.service && /bin/systemctl stop ip6tables.service
永久关闭防火墙:systemctl disable iptables.service && systemctl disable ip6tables.service
查看防火墙是否关闭:firewall-cmd --state
[root@hadoop ~]# yum install iptables-services [root@hadoop ~]# /bin/systemctl stop iptables.service [root@hadoop ~]# /bin/systemctl stop ip6tables.service [root@hadoop ~]# systemctl disable iptables.service [root@hadoop ~]# systemctl disable ip6tables.service [root@hadoop ~]# firewall-cmd --state not running
6.关闭SELINUX(参考这里)。
使用vi /etc/selinux/config编辑文件,将SELINUX=enfocing修改为disabled
[root@hadoop ~]# vi /etc/selinux/config [root@hadoop ~]# cat /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of three two values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted [root@hadoop ~]# getenforce #查看SELinux状态 Enforcing [root@localhost ~]# reboot ----------重启后---------- [root@hadoop ~]# getenforce Disabled
7.安装yum源(参考这里)并安装基础包。
以下软件我们未来做hadoop开发基本上都能用上,作为一个严谨的开发人员,一定要保证它们均被安装,使我们的系统可靠、安全。
yum -y install openssh* yum -y install man* yum -y install compat-libstdc++-33* yum -y install libaio-0.* yum -y install libaio-devel* yum -y install sysstat-9.* #没装上 yum -y install glibc-2.* #没装上 yum -y install glibc-devl-2.* glibc-headers-2.* #第一个没装上 yum -y install ksh-2* yum -y install libgcc-4.* yum -y install libstdc++-4.* yum -y install libstdc++-4.*.i686* yum -y install libstdc++-devel-4.* yum -y install gcc-4.*x86_64* yum -y install gcc-c++-4.*x86_64* yum -y install elfutils-libelf-0*x86_64* elfutils-libelf-devel-0*x86_64* yum -y install elfutils-libelf-0*i686* elfutils-libelf-devel-0*i686* yum -y install libtool-ltdl*686* yum -y install ncurses*i686* yum -y install ncurses* yum -y install readline* yum -y install unixODBC* yum -y install zlib yum -y install zlib* yum -y install openssl* yum -y install patch yum -y install git yum -y install lzo-devel zlib-devel gcc autoconf automake libtool #autoconf没装上 yum -y install lzop yum -y install lrzsz yum -y install nc yum -y install glibc yum -y install gzip yum -y install zlib yum -y install gcc yum -y install gcc-c++ yum -y install make yum -y install protobuf yum -y install protoc #没装上 yum -y install cmake yum -y install openssl-devel yum -y install ncurses-devel yum -y install unzip yum -y install telnet yum -y install telnet-server yum -y install wget yum -y install svn yum -y install ntpdate
8.关闭不必要的服务。
chkconfig autofs off chkconfig acpid off chkconfig sendmail off chkconfig cups-config-daemon off chkconfig cpus off chkconfig xfs off chkconfig lm_sensors off chkconfig gpm off chkconfig openibd off chkconfig pcmcia off chkconfig cpuspeed off chkconfig nfslock off chkconfig iptables off chkconfig ip6tables off chkconfig rpcidmapd off chkconfig apmd off chkconfig sendmail off chkconfig arptables_jf off chkconfig microcode_ctl off chkconfig rpcgssd off
9.安装Java环境。
rpm -qa|grep java命令查看是否系统已安装jdk包,如果有的话需要使用 rmp -e 软件包名称 命令先卸载(我的centos7 默认没有java)。
上传jdk包到/usr/目录。然后解压,重命名,配置环境变量
[root@hadoop ~]# cd /usr/ root@hadoop usr]# tar -xzvf jdk-8u11-linux-x64.tar.gz #解压 [root@hadoop usr]# mv jdk1.8.0_11/ java/ 重命名 [root@hadoop usr]# vi /etc/profile #配置环境变量,添加如下4行 export JAVA_HOME=/usr/java export JRE_HOME=/usr/java/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin [root@hadoop usr]# source /etc/profile #使配置的环境变量生效 [root@hadoop usr]# java -version #查看 java version "1.8.0_11" Java(TM) SE Runtime Environment (build 1.8.0_11-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.11-b03, mixed mode)
第二部分 Hadoop正式安装
1.安装Hadoop。上传Hadoop安装包到/usr/local/目录下,然后解压缩,重命名,配置环境变量
[root@hadoop usr]# cd /usr/local/ [root@hadoop local]# ls bin etc games hadoop-3.1.0.tar.gz include lib lib64 libexec sbin share src [root@hadoop local]# tar xzvf hadoop-3.1.0.tar.gz #解压缩 [root@hadoop local]# mv hadoop-3.1.0 hadoop #重命名 [root@hadoop local]# vi /etc/profile #配置环境变量:将以下几行添加到配置文件末尾,保存退出
export HADOOP_HOME=/usr/local/hadoop #export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native" export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native export HADOOP_COMMON_LIB_NATIVE_DIR=/usr/local/hadoop/lib/native export HADOOP_OPTS="-Djava.library.path=/usr/local/hadoop/lib" #export HADOOP_ROOT_LOGGER=DEBUG,console export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin #hadoop-3.1.0必须添加如下5个变量否则启动报错,hadoop-2.x貌似不需要 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root [root@hadoop local]# source /etc/profile #使配置文件生效 [root@hadoop ~]# hadoop version #测试是否配置成功 Hadoop 3.1.0 Source code repository https://github.com/apache/hadoop -r 16b70619a24cdcf5d3b0fcf4b58ca77238ccbe6d Compiled by centos on 2018-03-30T00:00Z Compiled with protoc 2.5.0 From source with checksum 14182d20c972b3e2105580a1ad6990 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.0.jar
2.修改hadoop的5个配置文件。非常重要。。。
现在先看一下hadooped目录。我们可以看到,hadoop下一共有7个目录,bin和sbin是可执行文件的目录,etc是放配置文件的目录,include、lib和libexec均是放一些类库的,share是放一些共享类库和jar包的。
[root@hadoop local]# cd hadoop [root@hadoop hadoop]# ll total 176 drwxr-xr-x 2 1000 1000 183 Mar 29 20:22 bin drwxr-xr-x 3 1000 1000 20 Mar 29 20:01 etc drwxr-xr-x 2 1000 1000 106 Mar 29 20:22 include drwxr-xr-x 3 1000 1000 20 Mar 29 20:22 lib drwxr-xr-x 4 1000 1000 288 Mar 29 20:22 libexec -rw-rw-r-- 1 1000 1000 147145 Mar 21 13:57 LICENSE.txt -rw-rw-r-- 1 1000 1000 21867 Mar 21 13:57 NOTICE.txt -rw-rw-r-- 1 1000 1000 1366 Mar 21 13:57 README.txt drwxr-xr-x 3 1000 1000 4096 Mar 29 20:01 sbin drwxr-xr-x 4 1000 1000 31 Mar 29 20:36 share
首先,进入cd /usr/local/hadoop/etc/hadoop目录,这5个配置文件均在此目录中。
第一个:hadoop-env.sh
[root@hadoop hadoop]# vi hadoop-env.sh #添加如下一行变量 #hadoop-3.1.0是第54行,hadoop-2.7.7是第25行 #可以使用 :set number来显示行数 export JAVA_HOME=/usr/java
第二个:core-site.xml(HADOOP-HDFS系统内核文件)
[root@hadoop hadoop]# vi core-site.xml #添加如下几行 <configuration> <!--指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:9000</value> </property> <!--指定HADOOP运行时产生文件的存储目录-->
<property> <name>hadoop.tmp.dir</name> <value>/var/hadoop/tmp</value> </property> </configuration>
注意:在hadoop安装目录的文档中有所有配置文件的默认参数表,用户可以查看后,根据实际情况进行修改。
比如:在D:/hadoop-3.1.0/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.html文档中可以看到:
hadoop.tmp.dir的默认值是/tmp/hadoop-${user.name}。/tmp/是Linux系统的临时目录,如果我们不重新指定的话,默认Hadoop工作目录在Linux的临时目录,一旦Linux系统重启,所有文件将会清空,包括元数据等信息都丢失了,需要重新进行格式化,非常麻烦。
第三个:hdfs-site.xml
[root@hadoop hadoop]# vi hdfs-site.xml #添加如下几行
<configuration>
<!--指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置默认端口,这段是我后来加的,如果不加上会导致启动hadoop-3.1.0后无法访问50070端口查看HDFS管理界面,hadoop-2.7.7可以不加-->
<property>
<name>dfs.http.address</name>
<value>192.168.42.134:50070</value>
</property>
</configuration>
在D:\hadoop-3.1.0\share\doc\hadoop\hadoop-project-dist\hadoop-hdfs\hdfs-default.xml文档中可以看到:
dfs.replication的默认值是3,由于HDFS的副本数不能大于DataNode数,而我们此时安装的hadoop中只有一个DataNode,所以将dfs.replication值改为1。
dfs.namenode.http-address在hadoop-3.1.0版本上的默认值是 0.0.0.0:9870 ,在hadoop-2.7.7版本上的默认值是0.0.0.0:50070,所以不同版本可以通过不同端口访问NameNode。
第四个:mapred-site.xml
[root@hadoop hadoop]# mv mapred-site.xml.templete mapred-site.xml #重命名,hadoop-3.1.0系统中就是mapred-site.xml不需要改名,hadoop-2.7.7需要改名 [root@hadoop hadoop]# vi mapred-site.xml #添加如下几行,指定hadoop运行在哪种计算框架上,这里指定yarn框架。 <!--指定mr运行在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
第五个:yarn-site.xml
[root@hadoop hadoop]# vi yarn-site.xml #添加如下几行
<configuration>
<!-- 指定YARN的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
其实还有第6个文件slaves,内容为localhost,不需要修改。slaves这个文件指定DataNode在哪台机器上。这个文件在hadoop-2.7.7中存在,但是在hadoop-3.1.0里没有这个文件,我怀疑是该文件改名为workers了。当搭建分布式hadoop集群时,需要修改这个文件,配置DataNode在哪台机器上。
旧版本中貌似有个masters文件用来配置SecondaryNameNode在哪台机器上(最好不要跟NameNode放在同一台机器上),但是我在新版本目录中没找到这个文件,不知道新版本如何配置SecondaryNameNode?
3.解决互信问题。
主要是目的是当hadoop集群有多台机器时,我们可以在任意一台机器上输入start-all.sh命令启动集群中的所有节点,方便快捷。如果不配置免密码登录的话,那么我们需要一台一台机器输入密码登录后分别启动各个节点,非常麻烦。
方式一:配置ssh,生成密钥,使ssh可以免密码连接localhost
[root@hadoop rpms_yum]# cd /root [root@hadoop ~]# ssh-keygen -t rsa #生成ssh密钥对 Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): #直接回车 Enter passphrase (empty for no passphrase): #直接回车 Enter same passphrase again: #直接回车 Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:9NevFFklAS5HaUGJtVrfAlbYk82bStTwPvHIWY7as38 root@hadoop The key's randomart image is: +---[RSA 2048]----+ | +*O*=.| | .o=+=o+| | . ..O +=| | . . * *.%o| | S o o %o+| | . + +.| | . + .| | . +E| | o.o| +----[SHA256]-----+ [root@hadoop ~]# cd .ssh/ [root@hadoop .ssh]# ls #id_rsa为私钥,id_rsa.pub为公钥 id_rsa id_rsa.pub known_hosts [root@hadoop .ssh]# cp id_rsa.pub authorized_keys #使主机之间可以免密码登录 [root@hadoop .ssh]# ssh hadoop date #查看(不需要输入密码,直接输出结果,说明免密成功) Mon Jul 16 05:02:27 EDT 2018
方式二:采用sshUserSetup.sh脚本去解决互信问题(sshUserSetup.sh是Oracle自带的一个快速配置互信的脚本程序,我们可以拿来借用一下)
将sshUserSetup.sh上传到/root目录,执行命令搭建本机互信(因为本机有2个节点,NameNode和DataNode)
[root@hadoop ~]# cd /root/ [root@hadoop ~]# ls anaconda-ks.cfg sshUserSetup.sh [root@hadoop ~]# sh sshUserSetup.sh -user root -hosts "hadoop" -advanced -noPromptPassphrase #这个文件我是从网上找的,执行命令后总是报错:syntax error near unexpected token `else'
第三部分 启动Hadoop集群
1.首先格式化NameNode
注意:如果格式化NameNode之后运行过hadoop,然后又想再格式化一次NameNode,那么需要先删除第一次运行Hadoop后产生的VERSION文件,否则会出错,详情见第四部分问题4。
[root@hadoop ~]# hdfs namenode -format #中间没有报错并且最后显示如下信息表示格式化成功 ... /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop/192.168.42.134 ************************************************************/
格式化完成后,系统会在dfs.data.dir目录下生成元数据信息。
2.输入 start-all.sh 启动
[root@hadoop hadoop]# start-all.sh Starting namenodes on [hadoop] Last login: Mon Jul 16 05:02:39 EDT 2018 from hadoop on pts/1 Last failed login: Mon Jul 16 05:51:35 EDT 2018 from 192.168.42.131 on ssh:notty There was 1 failed login attempt since the last successful login. Starting datanodes Last login: Mon Jul 16 05:57:58 EDT 2018 on pts/1 localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Starting secondary namenodes [hadoop] Last login: Mon Jul 16 05:58:01 EDT 2018 on pts/1 2018-07-16 05:58:41,527 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting resourcemanager Last login: Mon Jul 16 05:58:20 EDT 2018 on pts/1 Starting nodemanagers Last login: Mon Jul 16 05:58:44 EDT 2018 on pts/1
3.执行 jps 验证集群是否启动成功
[root@hadoop hadoop]# jps #显示以下几个进程说明启动成功 96662 Jps 95273 DataNode #可有可无 95465 SecondaryNameNode #重要 95144 NameNode #重要 95900 NodeManager #可有可无 95775 ResourceManager #非常重要
4.关闭hadoop集群
[root@hadoop hadoop]# stop-all.sh Stopping namenodes on [hadoop] Last login: Mon Jul 16 05:58:46 EDT 2018 on pts/1 Stopping datanodes Last login: Mon Jul 16 06:19:41 EDT 2018 on pts/1 Stopping secondary namenodes [hadoop] Last login: Mon Jul 16 06:19:49 EDT 2018 on pts/1 2018-07-16 06:20:25,023 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Stopping nodemanagers Last login: Mon Jul 16 06:20:13 EDT 2018 on pts/1 Stopping resourcemanager Last login: Mon Jul 16 06:20:25 EDT 2018 on pts/1
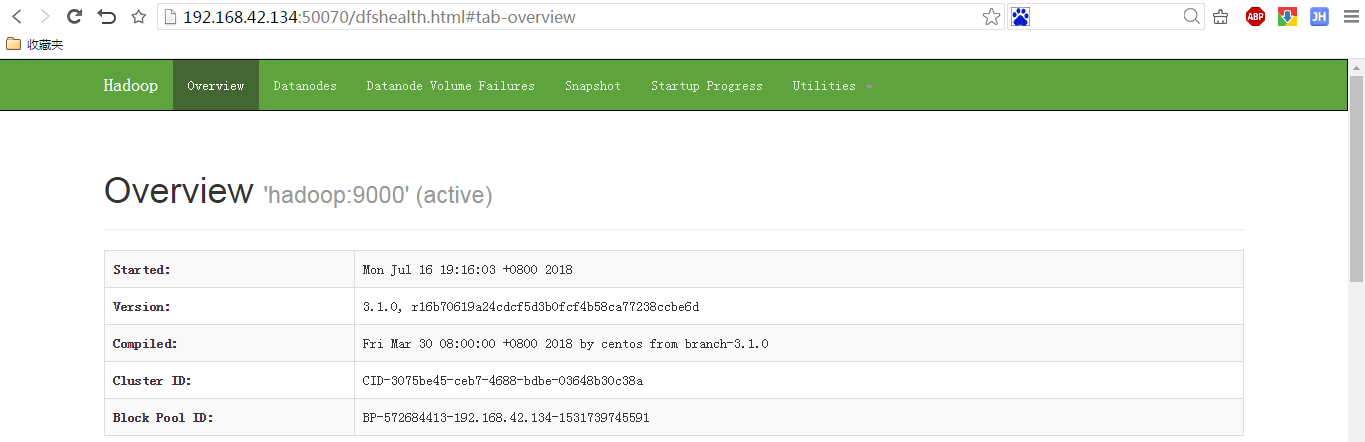
5.登录HDFS管理界面(NameNode):http://ip:50070
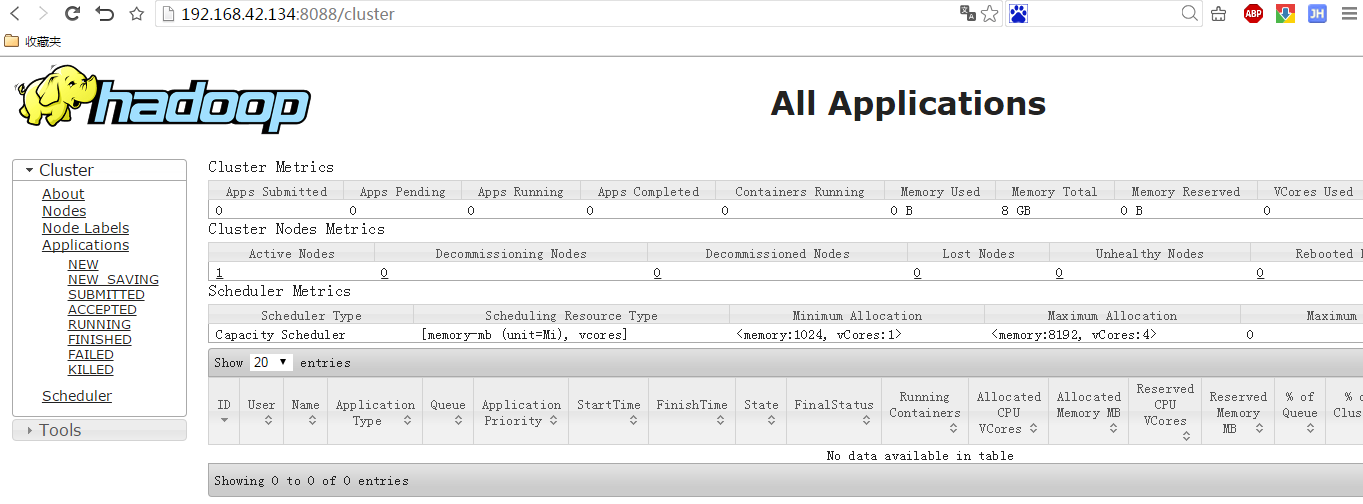
6.登录MR管理界面: http://ip:8088
第四部分 一些问题?
1.我们可以看到不管是启动还是关闭hadoop集群,系统都会报如下错误:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方式:先看看我们安装的hadoop是否是64位的
[root@hadoop hadoop]# file /usr/local/hadoop/lib/native/libhadoop.so.1.0.0 #出现以下信息表示我们的hadoop是64位的 /usr/local/hadoop/lib/native/libhadoop.so.1.0.0: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=8d84d1f56b8c218d2a33512179fabffbf237816a, not stripped
永久解决方式:
[root@hadoop hadoop]# vi /usr/local/hadoop/etc/hadoop/log4j.properties #在文件末尾添加如下一句,保存退出
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=Error
2.hadoop-3.1.0启动hadoop集群时还有可能可能会报如下错误信息:
[root@hadoop ~]# start-all.sh Starting namenodes on [hadoop] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [hadoop] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation. 2018-07-16 05:45:04,628 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting resourcemanager ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation. Starting nodemanagers ERROR: Attempting to operate on yarn nodemanager as root ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
解决方式:
[root@hadoop hadoop]# vi /etc/profile #添加如下几行 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root [root@hadoop hadoop]# source /etc/profile
3.启动hadoop后发现无法访问50070端口?
解决方式参考这里
4.Hadoop集群启动后,使用jps查看没有DataNode进程?
原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。因此就会造成datanode与namenode之间的id不一致。
解决方法:删除dfs.data.dir(在core-site.xml中配置了此目录位置)目录里面的所有文件,重新格式化,最后重启。
[root@hadoop ~]# stop-all.sh ... [root@hadoop ~]# rm -rf /var/hadoop/tmp/ [root@hadoop ~]# hdfs namenode -format ... [root@hadoop ~]# start-all.sh ...
另,找到一篇很好的hadoop搭建伪分布式集群的博文,推荐给大家。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号