

pyppeteer模块
selenium + chrome 爬取某网站被检测到
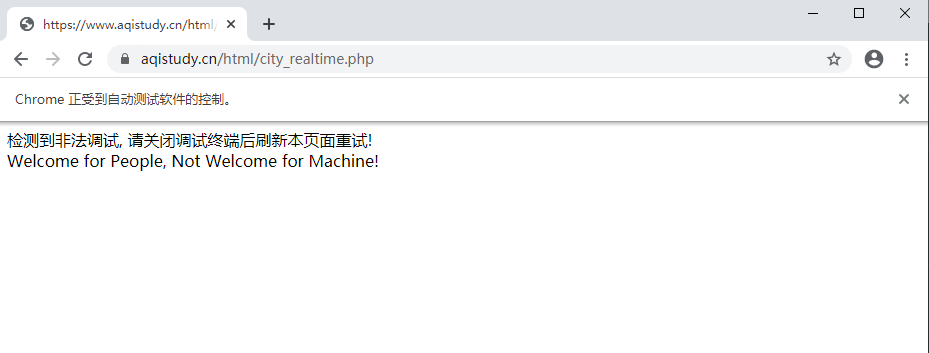
pyppeteer模块使用
启动浏览器 browser = await launch(headless=False) #headless默认为True,即无界面启动。 创建页面 page = await browser.newPage() 设置页面大小 page.setViewport({'width': 1200, 'height': 800}) 访问url page.goto(url) 查询所有页面 browser.pages() 返回页面源代码 page.content() 输入字符串 page.type(selector, text) selector用于确认节点位置。 Type selector 语法: eltname 例子: input对应 Class selector 语法: .classname 例子: .index对应class=index ID selector 语法: #idname 例子: #index对应id=index Universal selector 选择所有元素,或者可以限制到特定的名称空间或所有名称空间。 语法: * ns|* *|* 例子: *会匹配到所有元素 Attribute selector 语法: [attr] [attr=value] [attr~=value] [attr|=value] [attr^=value] [attr$=value] [attr*=value] 例子: [autoplay]将匹配所有设置了autoplay attr对象的元素(任何值)。 鼠标单击 page.click(selector) 截图 page.screenshot({'path': 'example.png'})
import asyncio from pyppeteer import launch async def main(): browser = await launch(headless=False) page = await browser.newPage() await page.goto('https://blog.csdn.net/') # 截图 await page.screenshot({"path": 'cnblogs.png'}) await browser.close() asyncio.get_event_loop().run_until_complete(main())
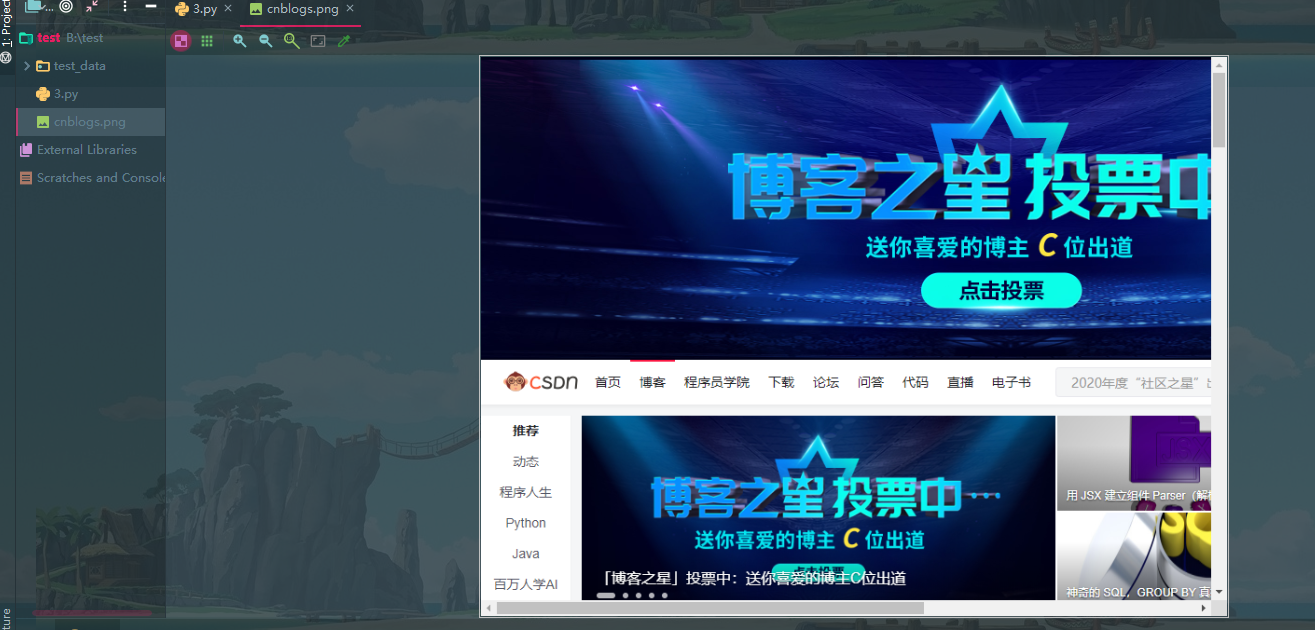
解决办法:pyppeteer模块解决反爬
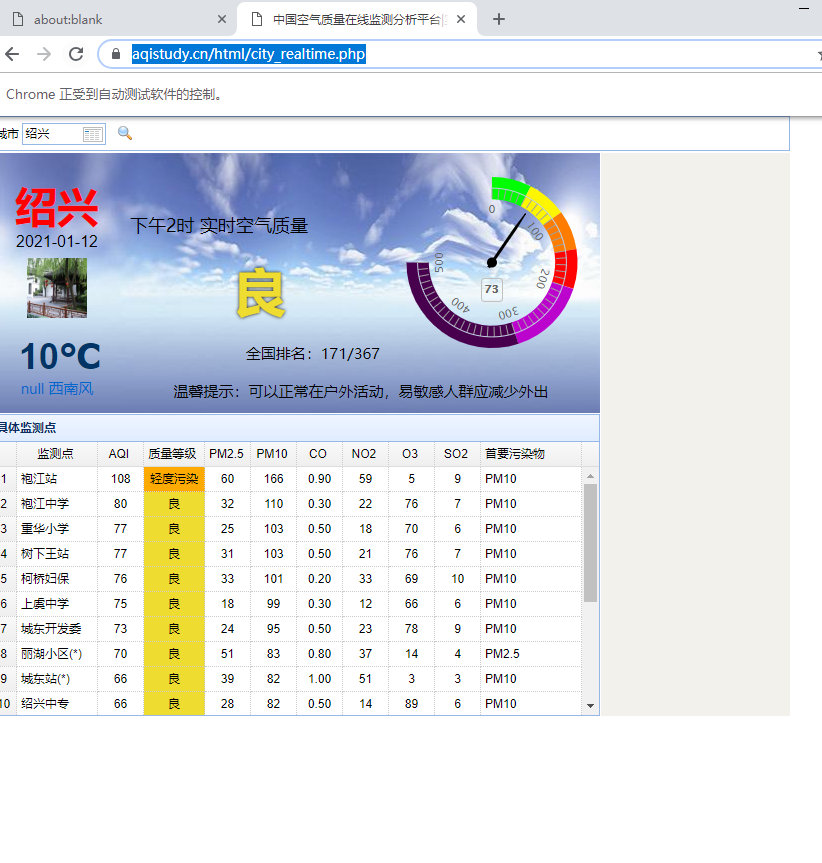


import asyncio from pyppeteer import launch from lxml import etree async def main(): browser = await launch(headless=False) page = await browser.newPage() #网址请求 await page.goto('https://www.aqistudy.cn/html/city_realtime.php') #找到搜索框查找绍兴 await page.type('#city',"绍兴") await page.click('#btnSearch') page_text = await page.content() tree = etree.HTML(page_text) #查找时间 date_page = tree.xpath('//*[@id="dateSpan"]')[0].text time_page = tree.xpath('//*[@id="timeSpan"]')[0].text #查找全国排名和aqi rank_page = tree.xpath('//*[@id="rankSpan"]')[0].text aqi_level = tree.xpath('//*[@id="aqiSpan"]/span')[0].text #查找城市 city_page = tree.xpath('//*[@id="citySpan"]')[0].text # 绍兴综合处理 sx_dic = {"pubtime": date_page, "city": city_page, "rank": rank_page, "time": time_page, "aqi_level": aqi_level} print(sx_dic) """获取到的数据写入数据库""" await asyncio.sleep(40) await browser.close() asyncio.get_event_loop().run_until_complete(main())
import asyncio from pyppeteer import launch from lxml import etree launch_args = { "headless": False, "args": [ "--headless", #设置生成无界面模式 "--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36", ], } async def main(): browser = await launch(**launch_args) page = await browser.newPage() #网址请求 await page.goto('https://www.aqistudy.cn/html/city_realtime.php') #找到搜索框查找绍兴 await page.type('#city',"绍兴") await page.click('#btnSearch') page_text = await page.content() tree = etree.HTML(page_text) #查找时间 date_page = tree.xpath('//*[@id="dateSpan"]')[0].text time_page = tree.xpath('//*[@id="timeSpan"]')[0].text #查找全国排名和aqi rank_page = tree.xpath('//*[@id="rankSpan"]')[0].text aqi_level = tree.xpath('//*[@id="aqiSpan"]/span')[0].text #查找城市 city_page = tree.xpath('//*[@id="citySpan"]')[0].text # 绍兴综合处理 sx_dic = {"pubtime": date_page, "city": city_page, "rank": rank_page, "time": time_page, "aqi_level": aqi_level} print(sx_dic) """获取到的数据存入数据库""" await asyncio.sleep(40) await browser.close() asyncio.get_event_loop().run_until_complete(main())
中间有一个小问题 真气网页面有检测 所以当搜索框搜索字段 获取当前页面的源码信息时是获取不到当前页面的 只能一直是获取到最开始的页面
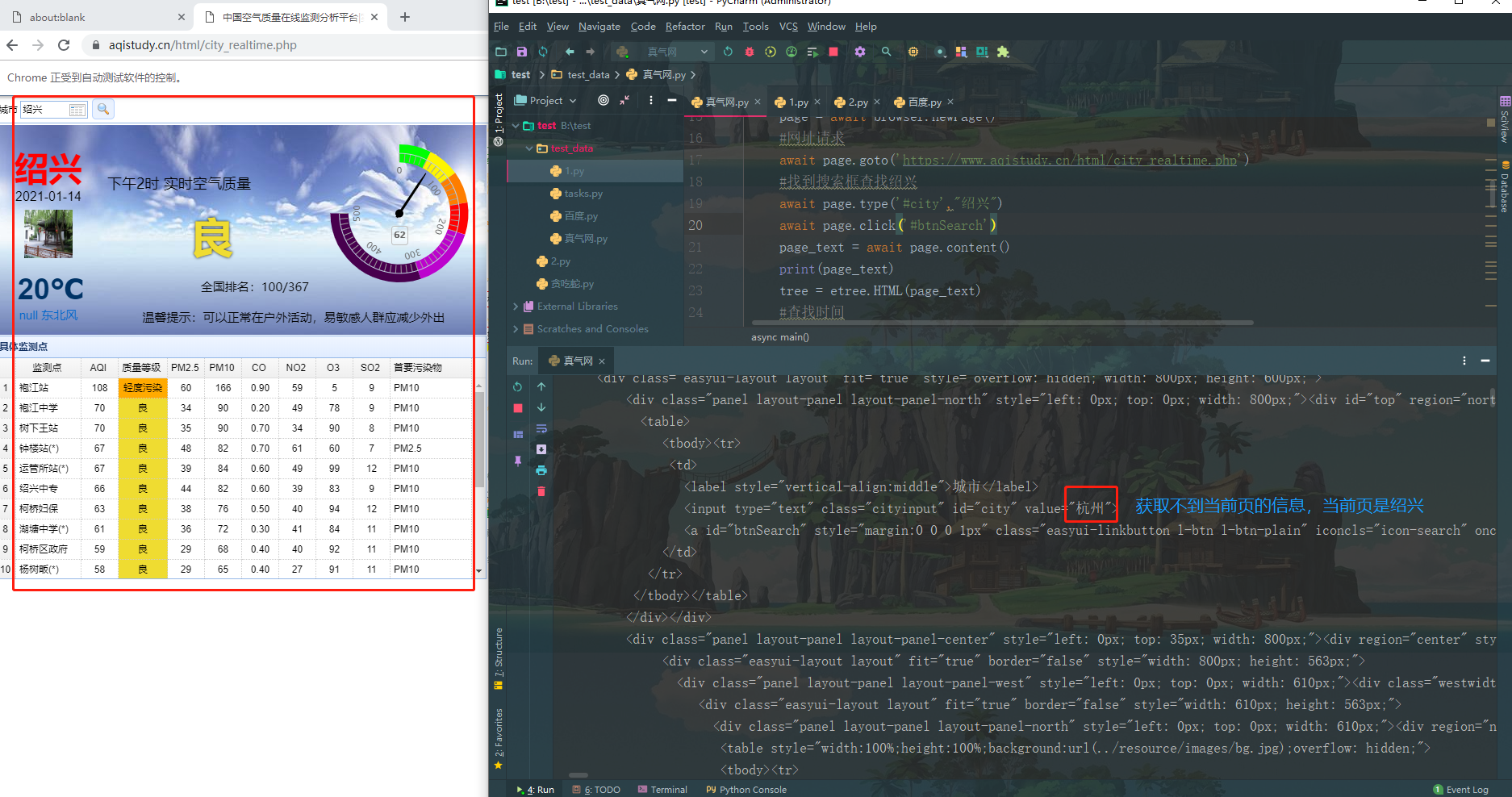
# 运行Javascript,避免WebDriver被检测
await page.evaluateOnNewDocument('Object.defineProperty(navigator,"webdriver",{get:() => false})')
import asyncio from pyppeteer import launch from lxml import etree pointname_list=[] aqi_list=[] quality_list=[] pm2_5_list=[] pm10_list=[] co_list=[] no2_list=[] o3_list=[] so2_list=[] primary_pollutant_list=[] launch_args = { "headless": False, "args": [ "--headless", "--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36", ], } async def main(): browser = await launch(**launch_args) page = await browser.newPage() # 运行Javascript,避免WebDriver被检测 await page.evaluateOnNewDocument('Object.defineProperty(navigator,"webdriver",{get:() => false})') #网址请求 await page.goto('https://www.aqistudy.cn/html/city_realtime.php') #找到搜索框查找绍兴 await page.type('#city',"绍兴") await page.click('#btnSearch') await asyncio.sleep(2) await page.reload() #页面加载完毕 page_source = await page.content() tree = etree.HTML(page_source) pointname = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-pointname"]') for name in pointname: pointname_list.append(name[0].text) aqi = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-aqi"]') for aqi_num in aqi: aqi_list.append(aqi_num.text) quality = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-quality"]') #轻度污染 for quality_name in quality: quality_list.append(quality_name.text) pm2_5 = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-pm2_5"]') for pm2_5_num in pm2_5: pm2_5_list.append(pm2_5_num.text) pm10 = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-pm10"]') for pm10_num in pm10: pm10_list.append(pm10_num.text) co = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-co"]') for co_num in co: co_list.append(co_num.text) no2 = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-no2"]') for no2_num in no2: no2_list.append(no2_num.text) o3 = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-o3"]') for o3_num in o3: o3_list.append(o3_num.text) so2 = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-so2"]') for so2_num in so2: so2_list.append(so2_num.text) primary_pollutant = tree.xpath('//*[@class="datagrid-cell datagrid-cell-c1-primary_pollutant"]') #PM10 for primary_pollutant_name in primary_pollutant: primary_pollutant_list.append( primary_pollutant_name.text) print(pointname_list,aqi_list,quality_list,pm2_5_list,pm10_list,co_list,no2_list,o3_list,so2_list,primary_pollutant_list) for pointname,aqi,quality,pm2_5,pm10,co,no2,o3,so2,primary_pollutant in zip(pointname_list,aqi_list,quality_list,pm2_5_list,pm10_list,co_list,no2_list,o3_list,so2_list,primary_pollutant_list): print({"pointname": pointname, "aqi": aqi, "quality": quality, "pm2_5": pm2_5, "pm10": pm10, "co": co, "no2": no2, "o3": o3, "so2": so2, "primary_pollutant": primary_pollutant }) await asyncio.sleep(40) await browser.close() asyncio.get_event_loop().run_until_complete(main())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号