

python正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re模块使Python语言拥有全部的正则表达式功能。
二、Python字匹配
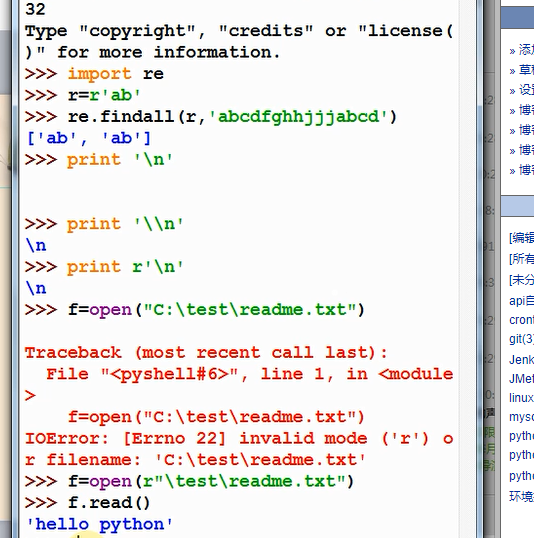
import re
r = r'ab' #定义匹配规则
print(re.findall(r,'abcdefgabcd'))
匹配规则r前面加了一个r,这样就不需要转义,比如遇到/n或者‘\t’或者‘\r’
输出:
['ab', 'ab']
注意:如果有元字符,使用转义符‘\’
eg:
r = r'1\*2' # *是元字符,所以这边需要加转义字符'\'
re.findall(r,'01*234501*23')
输出:
['1*2', '1*2']
三、Python元字符介绍
^ 匹配行首
$ 匹配行尾
. 匹配单字符
[] 匹配指定的一个字符集
[^] 补集匹配不在区间范围内的字符,注意^放在前面

四、Python特殊意义字符
\d 代表数字[0-9]
\D 非数字
\s 空白字符
\S 非空白字符

\w 单词字符[a-zA-Z0-9_]
\W 非单词字符
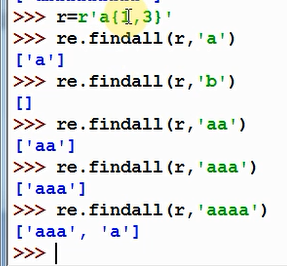
{} 前一个字符的重复次数
前一个字符在一个范围内的重复次数

* 将前一字符匹配大于等于0次,{0,}效果等价于*
+ 将前一个字符匹配大于等于1次,{1,}效果等价于+
? 将前一个字符匹配0次或1次,表示是否出现,{0,1}效果等价于?
*? 尽可能少的匹配
() 分组
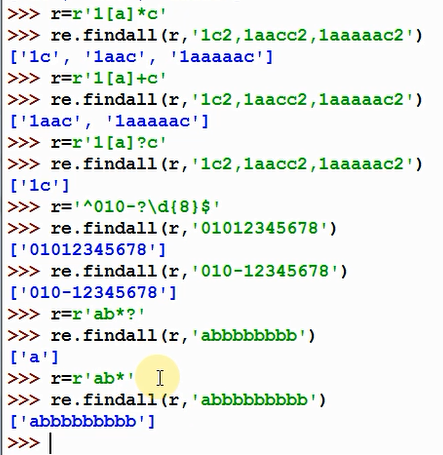
{m,n} 至少有m个重复,至多有n个重复,忽略m即为m=0,忽略n即为上边界无穷大
() 分组
eg:
r = r'\.com\.cn|\.com|\.cn'
re.findall(r,'zz@qq.com.cn')
结果:
['.com.cn']
注意:.是元字符,所以要转义
练习:利用分组和特殊字符匹配邮箱,注意'\.com\.cn'放在前面,整体加上括号作为一个大的分组处理,方便看出来匹配的是哪个

五、Python正则常用函数
compile 编译后执行速度更快,findall返回匹配列表
match 匹配字符串开头,返回第一个匹配的内容
search 匹配字符串全文,返回第一个匹配的内容
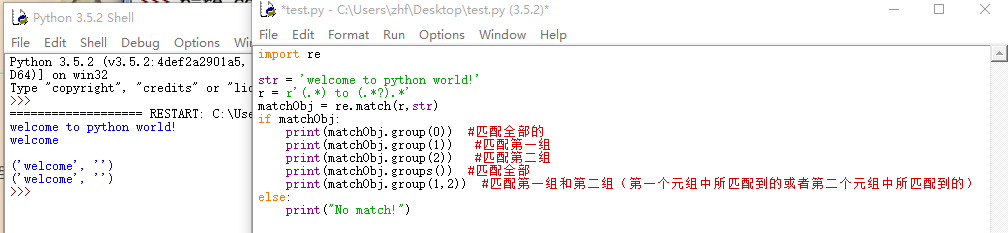
注意:使用match和search必须要用到分组
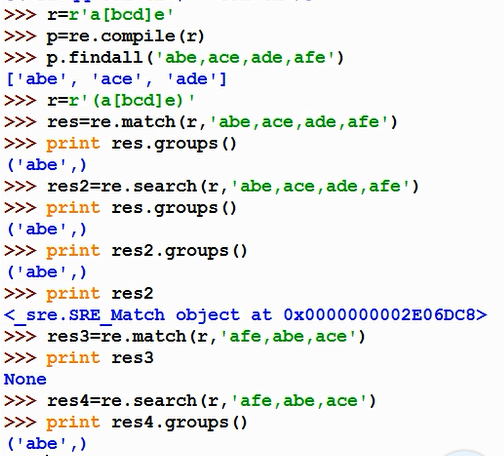
我们可以使用group(num)或groups()匹配对象函数来获取匹配表达式。
group(num=0)匹配的整个表达式的字符串;
group()可以一次输入多个组号,在这种情况下它将返回一个包含哪些组所对应值的元组。
groups()返回一个包含所有小组字符串的元组,从1到所含的小组号。
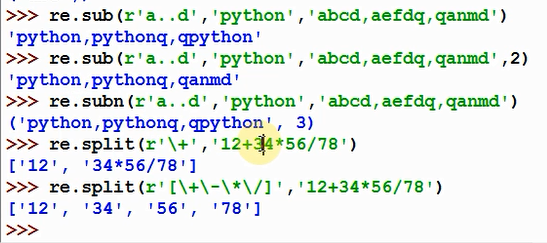
sub 字符串正则替换,返回替换字符串
subn 字符串正则替换,返回元组(替换字符串,替换次数)
split 返回切割后的列表
实例:
1、匹配身份证号

没有匹配到结果,缺少括号

posted on 2017-08-16 16:37 sunshine_zhf 阅读(124) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号