

倒排索引
正排索引:key-value 中,通过 key 去寻找 value。
倒排索引:通过 value(或包含 value)去寻找对应的 key。
正排索引需要首先对全局进行扫描遍历,进而从中做筛选;而倒排索引可以仅抽取符合条件的 value 值,节省大量的资源。
每个被索引的字段都有自己的倒排索引,是否被索引由索引字段主要属性配置中index属性配置决定。
倒排索引数据组织方式由mapping中字段的分析器决定。
ES生成倒排索引和搜索数据机制
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。
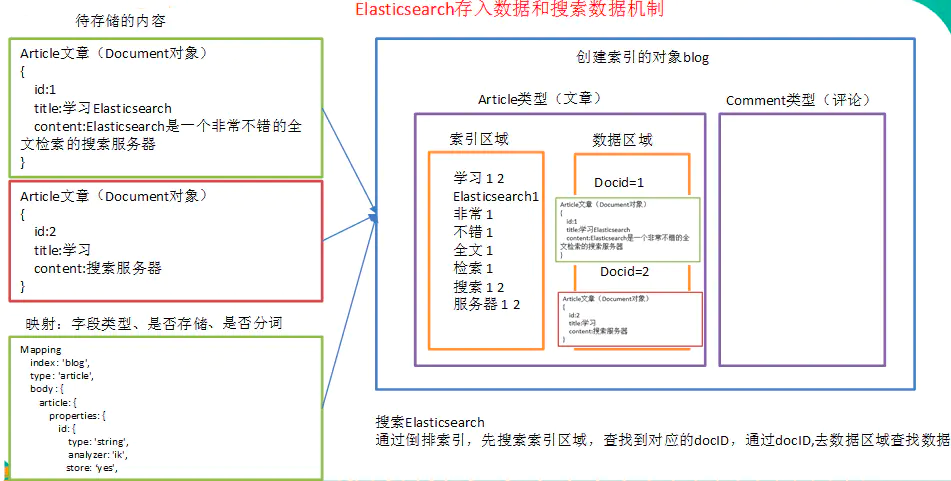
下面给出一个生成title字段倒排索引的例子。
- 索引名:article
- 字段名:title
- 搜索内容:select * from article where title like ‘%搜索引擎%’
【文档】
|
文档ID
|
title
|
|
1
|
ES是最流行的搜索引擎
|
|
2
|
Java是世界上最流行的语言
|
|
3
|
搜索引擎是如何诞生的
|
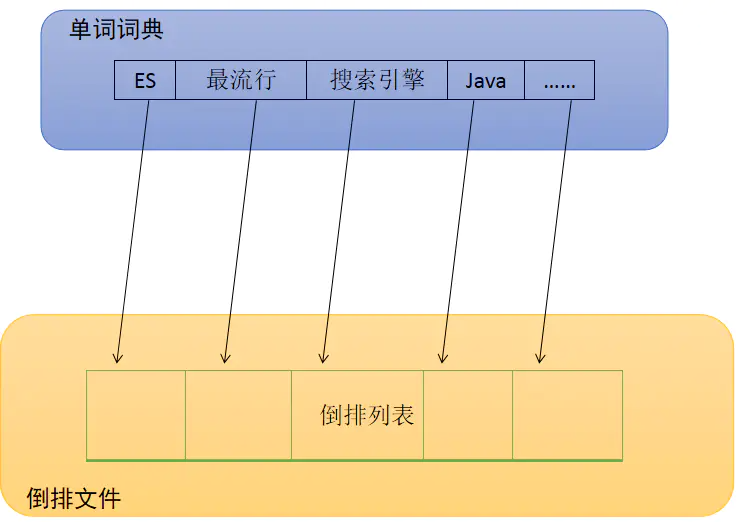
【文档 -> 单词词典】
单词词典:词典是由文档集合中出现过的所有单词构成的字符串集合。单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
|
单词
|
文档ID列表
|
|
ES
|
1
|
|
最流行
|
1,2
|
|
搜索引擎
|
1,3
|
|
Java
|
2
|
|
世界
|
2
|
|
语言
|
2
|
|
如何
|
3
|
|
诞生
|
3
|
【单词词典 -> PostingList】
PostingList:倒排列表记录了单词对应的文档信息集合。每条记录称为一个倒排项。倒排项包括:文档id、单词频率(TF,Term Frequency)、位置(Postion)、偏移(Offset )。
|
DocId
|
TF
|
Postion
|
Offset
|
|
1
|
1
|
2
|
<7,11>
|
|
3
|
1
|
0
|
<0,4>
|
所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件。倒排文件是存储倒排索引的物理文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号