
第3次作业:卷积神经网络
孙哲
学习心得:
卷积神经网络相较于传统神经网络有局部关联、参数共享的特点,因此可以减少参数量。
了解了卷积的基本概念、计算方法和池化、全连接的概念。
代码练习:
https://www.cnblogs.com/zhendehencai/p/15417600.html
夏鸿
视频总结
全连接网络:每一个神经元都跟其它神经元有连接。
全连接网络处理图像的问题:参数太多:权重矩阵的参数太多,易过拟合(过拟合通俗理解,预测时要求过于严格)
卷积神经网络:局部关联,参数共享
卷积层;池化层;全连接层
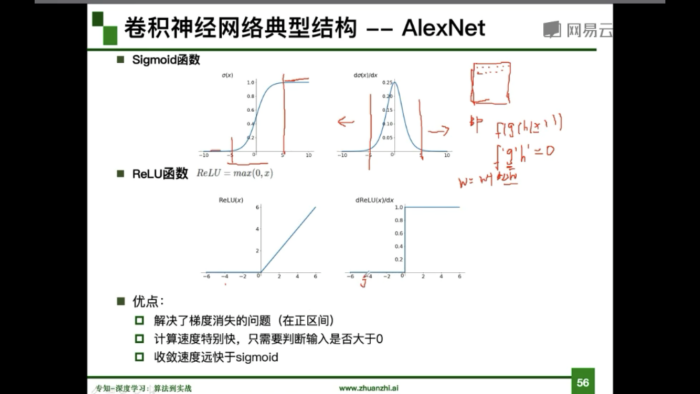
二维卷积:y=WX+b(W:卷积核 )
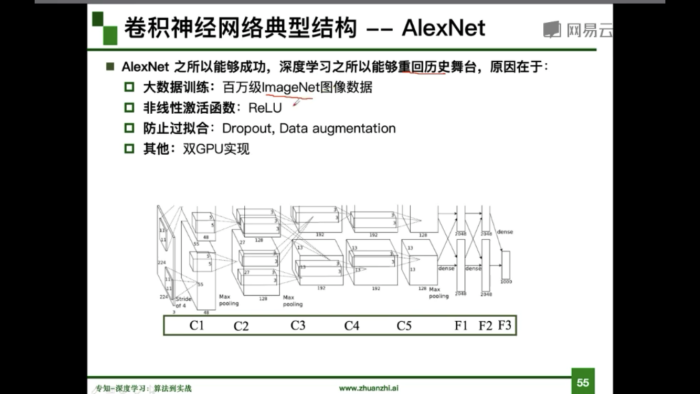
VGG是一个更深的网络 (16/19)
GoogleNet:多卷积核增加特征多样性
ResNet:用了残差的思想 输入x 将F(x)+x 传到下一层
MNIST 数据集分类
1.创建网络
只需 继承nn.Module,并实现它的forward方法
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(FC2Layer, self).__init__()
self.input_size = input_size
# 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出现在model类的forward函数中,用于改变输入或输出的形状
# x.view(-1, self.input_size) 的意思是多维的数据展成二维
# 代码指定二维数据的列数为 input_size=784,行数 -1 表示我们不想算,电脑会自己计算对应的数字
# 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64
# 大家可以加一行代码:print(x.cpu().numpy().shape)
# 训练过程中,就会看到 (64, 784) 的输出,和我们的预期是一致的
# forward 函数的作用是,指定网络的运行过程,这个全连接网络可能看不啥意义,
# 下面的CNN网络可以看出 forward 的作用。
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 执行父类的构造函数,所有的网络都要这么写
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
# 池化、ReLU一类的不用在这里定义
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
2. 在卷积神经网络上训练
# Training settings
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train(model_cnn)
test(model_cnn)

3.打乱像素顺序 训练
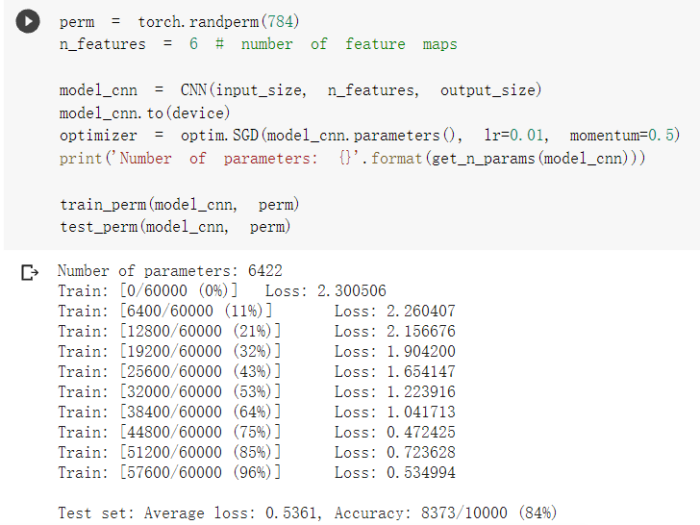
从结果来看卷积网络的性能下降明显。原因:卷积神经网络利用像素的局部关系
使用CNN对 CIFAR10数据集进行分类
1.定义网络 损失函数 优化器
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
2.训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')

3.结果
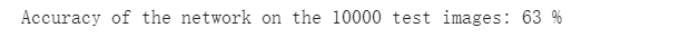
使用VGG16网络对CIFAR10数据集分类

1.VGG网络定义
这里做了简化
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(cfg)
self.classifier = nn.Linear(2048, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
2.结果
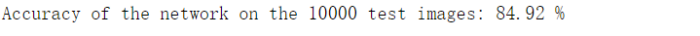
通过与之前相同的训练,准确率明显提升。
庞杰
学习总结:
首先回顾了深度学习的三个步骤:
1、搭建神经网络
2、找到合适的损失函数:交叉熵损失、均方误差
3、找到合适的优化函数,更新参数:反向传播、随机梯度下降
了解了传统神经网络的弊端:传统神经网络通过全连接来分析问题,当参数过多时,会产生过拟合问题,导致在训练集误差很小,测试集误差却很大,而且全连接的方式会在数据过多时,导致参数量过大。
而卷积神经网络通过局部关联,参数共享,不但需要的参数数目减少,还不会产生过拟合问题。
学习了卷积神经网络的基本结构:
1.卷积:
卷积是对两个实变函数的一种数学操作。
了解了卷积涉及到的基本概念:input 输入, kernel/filter 卷积核/滤波器, weights 权重,receptive field 感受野, activation map/ feature map 特征图 , padding , depth/channel 深度, output 输出,以及相关内容的计算公式
2.池化:
池化就是在保留主要特征的同时减少参数量和计算量,也就是输入压缩,主要的两种池化方法是最大值池化和平均值池化。
3.全连接:
两层之间所有神经元都有权重连接
最后认识了一些卷积神经网络的典型结构:AlexNet, ZFNet, VGG, GooleNet, ResNet
问题:
- 卷积运算中设计偏置项的作用
- 卷积核的大小如何设计
- 对代码的实现不了解
代码练习:
https://www.cnblogs.com/xbjek/p/15417592.html
李龙祥:
https://www.cnblogs.com/h3r3/p/15416906.html
罗漫:
视频学习心得:
在学习卷积神经网络的过程中,我发现大部分资料集中在什么是卷积层,什么是Pooling层,怎么计算每层的输出尺寸,卷积层和Pooling层以什么形式叠加。CNN之前的图片分类算法性能受制于特征的提取以及庞大参数数量导致的计算困难。
使用卷积来模拟人类视觉系统的工作方式,而这种方式极大的降低了神经网络的待训练参数数量。
为了获得平移不变性,使用了权重共享技术,该技术进一步降低了待训练参数数量。
卷积层实际上是在自动提取图片特征,解决了图像特征提取这一难题。
使用池化层的根本原因是降低计算量,而其带来的不变性并不是我们需要的。不过在以模型准确率为纲的大背景下,继续使用无可厚非。
全连接层实质上就是一个分类器。
问题总结:
损失函数对神经网络的影响不太明白。如何选定线性激活函数和非线性激活函数
代码练习:
https://www.cnblogs.com/1429597254q/p/15416869.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号