
深入理解“字符编码模型”
 最近踩坑了后端的文档生成,本想写篇相关的实践总结,忽然感悟到电子文档的魅力,尤其以“字符编码模型”为最,特此进行研究并写下此文。
不了解Unicode、UTF-8、UTF-16、GBK,搞不清楚码位、码元等概念,或者经常遇到乱码问题的小伙伴都可以在本文找到答案。
最近踩坑了后端的文档生成,本想写篇相关的实践总结,忽然感悟到电子文档的魅力,尤其以“字符编码模型”为最,特此进行研究并写下此文。
不了解Unicode、UTF-8、UTF-16、GBK,搞不清楚码位、码元等概念,或者经常遇到乱码问题的小伙伴都可以在本文找到答案。
深入理解“字符编码模型”
作者:哲思
时间:2022.8.28
邮箱:zhe__si@163.com
GitHub:zhe-si (哲思) (github.com)
前言
最近踩坑了后端的文档生成,本想写篇相关的实践总结,忽然感悟到电子文档的魅力,尤其以“字符编码模型”为最,特此进行研究并写下此文。
不了解Unicode、UTF-8、UTF-16、GBK,搞不清楚码位、码元等概念,或者经常遇到乱码问题的小伙伴都可以在本文找到答案。
简述字符编码

相信大家一定对上面的场景不陌生(„ಡωಡ„),这是一个经典的字符编码错误导致的乱码问题。而解决的方法也很简单,在打开文件的时候指定正确的编码方式即可。如图中的文本文件 a.txt 采用 utf-8 编码,指定该编码方式打开并读取文本内容如下图。
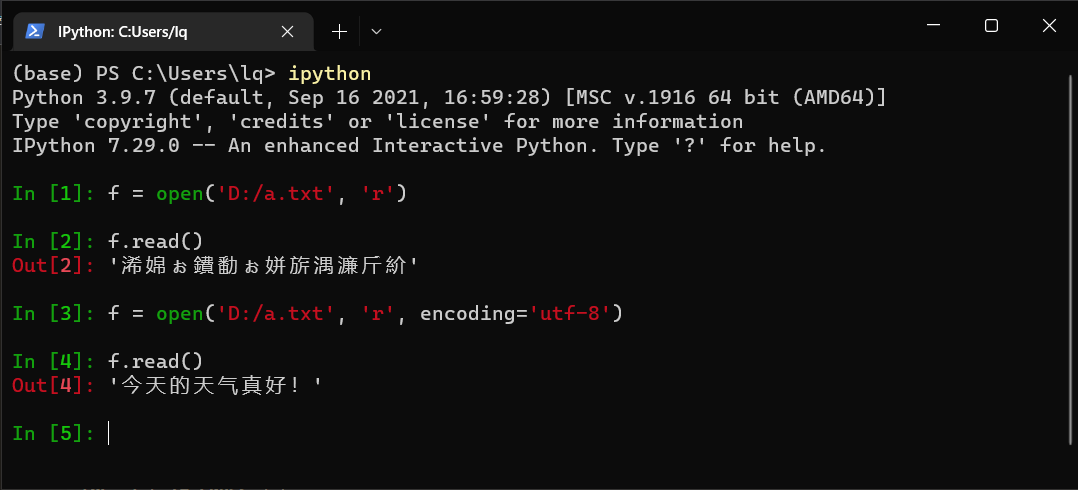
解决方案很简单,但方案背后所蕴含的知识可不简单,这就是“字符编码”。众所周知,一个字符类型(char)长度为 1 字节,由多个 char 组成的数组(约定以 \0 结尾)就是字符串。问题来了,一个字节只能表示 \(2^8\) (256)个数字,如何表示百倍于它的汉字呢?上面用到的 utf-8 又是什么?为什么不指定它就会乱码呢?
想要表示汉字很简单,一个字节不够,那再来个字节呀。用多个字节表示字符,又涉及具体用几个字节、如何高效利用空间、要表示范围足够大同时灵活可拓展等问题,因此提出了以 utf-8 为代表的字符编码的方法来告诉计算机如何解析字节流并将其转化为字符流。由于大部分字符编码的方法不互相兼容,用与编码时不同的编码方案解析它自然就会出错或者解析成错误的内容。
下面给出维基百科中的定义:字符编码(英语:Character encoding)是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。
概念可能不够具体,狭义来说,字符编码就是将字符(包括英文字母、汉字等)编码为计算机可以存储与解析的字节流形式,同时也支持从字节流解析回字符的形式。这是对现实生活中用到的文字与符号的建模,将它们用一种计算机可以理解的方式表示,来方便计算机处理。
为了标准化字符编码的过程,人们对编码设计的过程进行划分,提出了字符编码的抽象架构模型,共有 5 层,分别解决了字符编码流程中的五个具体细节问题,接下来进行详细介绍。
字符编码模型
设计字符编码,根据先后顺序可以分为以下五个步骤:
- 定义字符集:解决包含的字符范围的问题,声明都有哪些字符
- 编码字符集:解决如何用数字信号唯一的表示字符集中的每个字符
- 设计计算机保存字符编码用哪种数据类型以哪种规则保存:解决如何用某种数据类型描述字符编码后的数字信号
- 确定保存字符编码所用的数据类型如何映射到字节序列:解决数据类型(用来描述字符编码的数字信号)在计算机中(用字节序列)的表示方法
- 选择传输时合适的字节序列编码与压缩方案:解决描述字符串的字节序列在传输过程中的编码与压缩问题
基于上述五个步骤,定义:
五层模型
1. 抽象字符表(Abstract character repertoire)
抽象字符表定义了当前的字符编码所支持的所有抽象字符的集合。
抽象字符是指人从视觉上认为不同而从含义逻辑上认为相同的一组实际字符的集合,可认为该集合中的字符表示的含义相同。一层含义是,一个汉字有楷、行、草、隶等多种形体,但都表示同一个汉字,如下图。另一层含义是,在 Unicode 中西班牙语的 ñ 由 n 和 ~ 两个字符组成,虽然看上去是一个,但是两种不同的含义。

抽象字符表有些标准是封闭性的,抽象字符集合不会改变(包括: ASCII、ISO 8859 系列等);有些标准是开放性的,可以不断将新的字符添加到标准中(比如:Unicode)。
2. 编码字符集(CCS: Coded Character Set)
编码字符集在第一层抽象字符集的基础上,为每一个字符分配一个唯一的数字编码,让抽象的字符通过数字的方式表示出来。
编码字符集是一个映射过程,将抽象字符集中的每一个字符一对一的映射到一个坐标(若是一维就是单个整数)上,而每一个映射到的坐标(也就是数字编码)称为码位(也称码点),每个字符所占的码位称为码位值。所以,也可以称:编码字符集就是把抽象字符集中的每个抽象字符映射为码位值。
用来表示码位的坐标空间的维度称之为编码空间,可用一组数字、存储单元尺寸或者一些特殊形式表示。例如:GB 2312 汉字编码空间可表示为 94 × 94;ISO-8859-1的编码空间可表示为 8 比特或 256;Unicode 采用行、列、面的三维描述表示码位值。
这里特别讲解一下 Unicode(统一码)的编码字符集。每个 Unicode 字符编码可以表示为:U + 6个十六进制数字,比如:'0' 表示为 '\U000030'。Unicode 采用平面 + 16-bit 编码方式,每个平面的编码空间为 2^16(用'\U000030'的后四位表示,使用两个字节),共 17 个平面(用'\U000030'的前两位表示,使用一个字节),理论上能表示的字符数 = 平面数(17) × 平面编码空间大小(2^16) = 1114112。17个平面编号为0-16(0x00-0x10),如下图。

日常中常用的字符都定义在 0 号平面,该平面的码点表示时可以省略前两个十六进制位的平面号。平面中不是每个位置都定义了对应的字符,还有不少空间保留或作特殊用途。
每个抽象字符在 Unicode 中采用唯一且不可变的字符名称来表示,如:拉丁字母 K 在 Unicode 中的字符名称是“Latin Capital Letter K”,码点是 004B。
3. 字符编码表(CEF: Character Encoding Form)
字符编码表将数字表示的码位值转换为整型值序列(由多个固定有限长度的整形数据类型组成)表示。
用来表示码位的有限长度整形,是计算机表达字符编码(码位值)的单位,称为编码单元,简称码元。
定义字符编码表有两步:
- 定义码元
- 定义如何使用多个码元表示码点值的规则
定义码元通常采用 8 bit(字节)的倍数。码元的存在,规整了表示不同字符的存储方式,避免在一串字符中用各种长度的整形混合表示。在计算机中采用字节的倍数存储与处理也匹配其存储、传输和处理的单位,对应计算机中的数据类型。
定义用码元表示码位值的规则,分为定长编码和变长编码。定长编码就是自身到自身的映射,如 ASCII 的编码 0-127,对应 7 bit,直接用 1 字节表示。UTF-32是 Unicode 对应的定长编码方案,字节内容一一对应码点。
变长编码基于某种规则将码位值根据需要映射到不同个数的码元序列上。
UTF-8
此处以 Unicode 最通用的字符编码表 UTF-8 进行说明。UTF-8 是 Unicode 的一种边长编码,码元为 8 bit,采用 1 - 4 个码元(字节)表示一个字符,根据字符码位值的不同变换表示长度。编码规则如下:
| Unicode 十六进制码点范围 | UTF-8 二进制 |
|---|---|
| 0000 0000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
- 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 UTF-8 完全兼容过去用 ASCII 编码的文档。
- 对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为 0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
UTF-16
UTF-16 则采用 16bit(两个字节) 码元,编码规则为:基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。而确定是用一个码元还是两个码元是通过基本平面中 U+D800 - U+DFFF 的编码留白实现的。
辅助平面的字符位共有 2^20 个,因此表示这些字符至少需要 20 个二进制位。UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF(空间大小 2^10),称为高位(H),后 10 位映射在 U+DC00 到 U+DFFF(空间大小 2^10),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。
第二层的编码字符集和该层字符编码表是多对多关系,一种编码方式也可应用多种字符集,如:EUC 编码方式可以用于 GB 2312,也可以用于 JIS X 0208(一种日语字符集编码标准);一种字符集何以对应多种编码方式,如:Unicode 对应UTF-8、UTF-16、UTF-32等编码方法,如下图所示。

例如,“汉字”这两个中文字符的 Unicode 码位值是 0x6C49 和 0x5B57,可用码元对应整数类型的数组表示为

4. 字符编码方案(CES: Character Encoding Scheme)
字符编码方案将码元映射到字节序列。
抽象字符的码位值可以通过具体数据类型的码元表示了,但由于这些数据类型可能需要多个字节才能表示,我们还没有解决码元如何用字节序列表示。码元映射为字节序列,也就是将特定的整数类型映射到对应的字节序列。一般讲的就是字节序,也就是大端和小端(当然,还有一些更复杂的)。
大端:低位地址存放高位数据,高位地址存放低位数据。与人的一般书写习惯一致,网络字节序要求使用大端。
小端:低位地址存放低位数据,高位地址存放高位数据。
如:数字 0x0102,大端存储为 [0x01, 0x02],小端存储为 [0x02, 0x01]。
在编程中,我们大多时候无需关系字节序,而是直接使用具体的数据类型,字节序作为操作系统或硬件的内部实现对用户透明。但是文本不仅需要在本地内存中读写,还要再磁盘中存储并在多个异构系统中传阅,这就需要保证字节序一致或者读取到文本所使用的字节序。因此,为了表示码元的字节序列在读写时的一致性,需要定义字符编码方案。
解决字节序问题,一般有两种方案:
- 强制规定使用某种字节序。如网络传输强制要求网络字节序使用大端序。
- 使用字节序标记说明当前使用的字节序。字符集编码一般采用这种方案。Unicode 编码方案中有个叫 BOM(Byte Order Mark)的东西,就是用来做这事的。
当然,对于码元为单字节的情况下,不存在字节序问题,如 UTF-8,这也是 UTF-8 广泛使用的原因之一。但一些 UTF-8 文件也存在 BOM 头,但这不是必须的,只是用来标识该文件采用 UTF-8 编码。
5. 传输编码语法(transfer encoding syntax)
传输编码语法用于处理第四层字符编码方案提供的字节序列,主要包括变换传输形式和压缩字节序列。
变换传输形式指将字节序列的值映射到一套更受限制的值域内,来满足传输环境限制。如:Email传输采用Base64或者quoted-printable,都是把8位的字节编码为7位长的数据。
压缩字节序列就是指一些无损字节序列压缩技术。如:LZW或者行程长度编码。
模型综述
从整体上看,字符编码模型是对人类理解的抽象字符到计算机实际表示、存储和传输字符的数据形式的建模过程。
第一层抽象字符表是对人类理解的抽象字符的总结,明确了抽象字符范围。每个抽象字符可能字形不同(写法不同),在不同语境下字符表示的含义不同,但从字符本身的角度逻辑相同,并采用字符名称等方式唯一的标识该字符。
第二层编码字符集则为抽象字符编号,将抽象字符表示成数学形式,类似模电和数电的关系,因为只有数字才能进一步保存到计算机。但注意,这一层并不涉及计算机,数学编号也是人类意义上的编号,但将形式上的符号抽象为数学编号表示,是用计算机建模现实事务的关键一步。
第三层字符编码形式是真正用计算机表示字符的第一步,这里采用计算机的抽象数据类型(码元)来表示人类对字符的抽象描述(数学编码)。
第四层字符编码方案则进一步将用计算机的抽象数据类型表示的字符映射到计算机真正的底层表示——字节流上。到这一层,字符已经完全转化为计算机的表示方式,计算机可以基于上述模型栈(其顺序处理的形式可以理解为栈)对字符进行读写或其他操作,并在计算机底层表示和人类的抽象字符间相互转化。
第五层传输编码语法是对计算机底层数据流额外的附加处理,来提升传输效率或满足传输要求。
上述字符编码模型可以进一步总结为一种计算机建模的通用思想:明确现实事物、建模事物、用计算机数据类型表示、用计算机底层字节序列表示、对字节序列的优化处理。
字符与字形
在前面的学习中,我们已经知道了通过字符编码模型将抽象字符转换为计算机底层数据结构的过程,好像已经圆满了。但请你重新审视你正在读的文字中的字符,并回忆刚刚所学,字符编码模型是否是完整的一条从你所见的字符到计算机底层表示的链路?
没错,缺少了字形。在抽象字符集中我们强调,字符集中的字符是逻辑上的抽象字符,而不是我们直接看到的字符,每个字符在不同的书写方式下都有多种字形表示。那么,现在是如何表示字形的呢?
字形描述,就是字体。字体描述了字符的形状,告诉了计算机如何“画出”某个字符,描述方式一般有散点和矢量。
由于本文重点在字符编码模型,所以在此不进行更详细的介绍,好奇的小伙伴可以看笔者的另一篇文章以TrueType为例谈字形描述。
举个实践例子
s := "hi你好 "
fmt.Println("runes: ")
for _, r := range s {
fmt.Printf("%v ", r)
}
fmt.Println("\nbytes: ")
for i := 0; i < len(s); i++ {
fmt.Printf("%v ", s[i])
}
fmt.Println("\n\nlen(s): ", len(s))
提问,上述 go 代码的输出结果是什么?
runes:
104 105 20320 22909 32
bytes:
104 105 228 189 160 229 165 189 32
len(s): 9
你猜对了吗?😏
这就是一个字符的码位(rune)和字节序列的对比使用场景。for-range 遍历的是字符串中每一个字符的码位值。而字符串实际采用 byte 数组存储,通过 len 函数获取长度已经根据下标的索引都是读取字符底层的字节序列表示。也就是说,go 中字符串本质上就是个 byte 数组,正好存储字符的底层字节表示,但提供了一个解析 byte 数组为字符的视图,让我们可以遍历读取字符串中的字符。
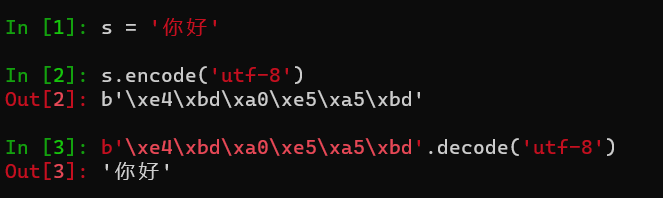
python 中,也可以通过编码和解码,在字符串和 bytes(字节数组)间转换。
后记
字符编码是电子文档的基础,也是编程的基础。只有了解了字符编码,才能对最常用的数据类型之一——字符串使用的游刃有余。
之后会继续研究电子文档,并写两篇 pdf、word、xlsx 等场景文档的生成、修改和底层格式设计的文章。
本文来自博客园,作者:_哲思,转载请注明原文链接:https://www.cnblogs.com/zhe-si/p/16631919.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号