
卷积神经网络的引入3 —— MLP 与 CNN 在更大数据集上的性能对比实验
卷积神经网络的引入3 —— MLP 与 CNN 在更大数据集上的性能对比实验
在前两篇文章中,我们分别验证了:
- MLP 对平移等扰动非常敏感,而 CNN 具备更好的鲁棒性
- 在 Fashion-MNIST(低维灰度图)下,MLP 与 CNN 的表现差距不算巨大
为了进一步理解 CNN 的结构优势是否会随 数据集复杂度的提升 而真正显现,本篇将进入本系列的第三个验证点:
一、实验目标
本篇旨在验证:
MLP 与 CNN 在更大、更复杂的图像数据集上是否会出现明显性能差异?
更具体地说,我们希望回答以下问题:
🧪 1. 当图片不再是低维灰度图(如 CIFAR10、STL10),MLP 的表达能力是否明显不足?
🧪 2. CNN 由于卷积与池化机制,是否在更大数据集上展现出更强的泛化能力?
🧪 3. 随着训练轮次提升,两者的收敛速度与最终精度差异是否会逐步拉大?
二、数据集选择与对比策略
本次实验选择 三个不同复杂度的数据集:
| 数据集 | 通道数 | 尺寸 | 难度 | 说明 |
|---|---|---|---|---|
| Fashion-MNIST | 1 | 28×28 | 低 | 上一章实验基准 |
| CIFAR-10 | 3 | 32×32 | 中 | 彩色图片,分类更复杂 |
| STL-10 | 3 | 96×96 | 高 | 图片分辨率大、类别难度高 |
本篇重点展示 CIFAR-10 实验(也是最经典的数据集)。
三、实验步骤
-
构建 MLP 与 CNN 两种模型基线
- MLP:输入直接 Flatten → 全连接层
- CNN:多层卷积 + 池化 + 全局池化
-
在同一数据集上训练 10 个 Epoch
- 优化器:Adam
- 学习率:1e-3
- 批次大小:64
-
对比训练集精度与验证集精度
- 用折线图对比两种模型的收敛过程
- 观察最终的测试集表现
四、实验代码
以下代码可完整复现本章实验,结构与上一篇保持一致。
# -*- coding: utf-8 -*-
# 卷积神经网络的引入3 —— 不同数据集规模下的 MLP 与 CNN 对比实验
# Author: 方子敬
# Date: 2025-11-11
import torch, torchvision
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
device = 'mps' if torch.backends.mps.is_available() else 'cpu'
# =============================
# 1️⃣ 数据集选择(可修改)
# =============================
DATASET = 'CIFAR10' # FashionMNIST / CIFAR10 / STL10
# =============================
# 2️⃣ 数据加载
# =============================
if DATASET == 'FashionMNIST':
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = datasets.FashionMNIST('./data', train=True, download=True, transform=transform)
testset = datasets.FashionMNIST('./data', train=False, download=True, transform=transform)
input_channels = 1
input_dim = 28 * 28
elif DATASET == 'CIFAR10':
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
])
trainset = datasets.CIFAR10('./data', train=True, download=True, transform=transform)
testset = datasets.CIFAR10('./data', train=False, download=True, transform=transform)
input_channels = 3
input_dim = 32 * 32 * 3
elif DATASET == 'STL10':
transform = transforms.Compose([
transforms.Resize((96,96)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
])
trainset = datasets.STL10('./data', split='train', download=True, transform=transform)
testset = datasets.STL10('./data', split='test', download=True, transform=transform)
input_channels = 3
input_dim = 96 * 96 * 3
train_loader = DataLoader(trainset, batch_size=64, shuffle=True)
test_loader = DataLoader(testset, batch_size=256)
# =============================
# 3️⃣ 定义模型
# =============================
class MLP(nn.Module):
def __init__(self, input_dim, hidden=1024):
super().__init__()
self.net = nn.Sequential(
nn.Flatten(),
nn.Linear(input_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, 10)
)
def forward(self, x):
return self.net(x)
class CNN(nn.Module):
def __init__(self, in_ch):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_ch, 32, 3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(128, 10)
)
def forward(self, x):
return self.net(x)
# =============================
# 4️⃣ 训练与验证
# =============================
loss_fn = nn.CrossEntropyLoss()
def train_one_epoch(model, loader, opt):
model.train()
total_loss, total_correct = 0, 0
for x, y in loader:
x, y = x.to(device), y.to(device)
out = model(x)
loss = loss_fn(out, y)
opt.zero_grad()
loss.backward()
opt.step()
total_loss += loss.item()
total_correct += (out.argmax(1) == y).sum().item()
return total_loss / len(loader), total_correct / len(loader.dataset)
def evaluate(model, loader):
model.eval()
total_correct = 0
with torch.no_grad():
for x, y in loader:
x, y = x.to(device), y.to(device)
total_correct += (model(x).argmax(1) == y).sum().item()
return total_correct / len(loader.dataset)
# =============================
# 5️⃣ 实验执行
# =============================
mlp = MLP(input_dim).to(device)
cnn = CNN(input_channels).to(device)
opt_mlp = torch.optim.Adam(mlp.parameters(), lr=1e-3)
opt_cnn = torch.optim.Adam(cnn.parameters(), lr=1e-3)
epochs = 10
mlp_train_acc, cnn_train_acc = [], []
mlp_val_acc, cnn_val_acc = [], []
for ep in range(epochs):
_, acc_m = train_one_epoch(mlp, train_loader, opt_mlp)
_, acc_c = train_one_epoch(cnn, train_loader, opt_cnn)
val_m = evaluate(mlp, test_loader)
val_c = evaluate(cnn, test_loader)
mlp_train_acc.append(acc_m)
cnn_train_acc.append(acc_c)
mlp_val_acc.append(val_m)
cnn_val_acc.append(val_c)
print(f"[{ep+1}/{epochs}] MLP val acc={val_m:.3f} | CNN val acc={val_c:.3f}")
# =============================
# 6️⃣ 精度曲线对比
# =============================
plt.figure(figsize=(10,6))
plt.plot(range(1, epochs+1), mlp_train_acc, 'r--o', label='MLP Train')
plt.plot(range(1, epochs+1), mlp_val_acc, 'r-', label='MLP Val')
plt.plot(range(1, epochs+1), cnn_train_acc, 'b--o', label='CNN Train')
plt.plot(range(1, epochs+1), cnn_val_acc, 'b-', label='CNN Val')
plt.title(f"Training vs Validation Accuracy on {DATASET}")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
五、训练结果(图示)
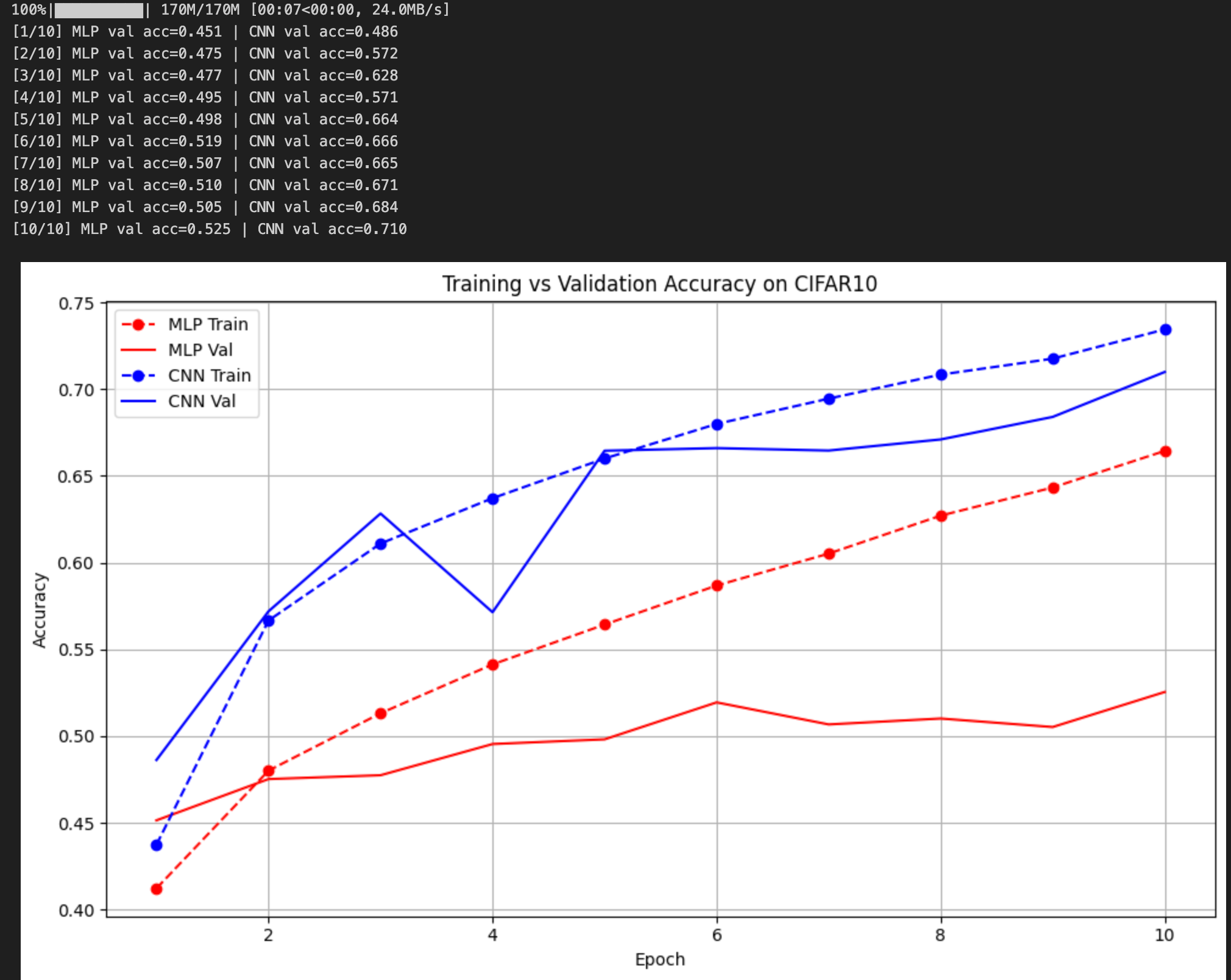
六、实验结论(可根据图示补充)
从图中可以明显观察到:
- MLP 的学习能力在 CIFAR10 上严重受限
训练集精度 从 42% → 66%,虽然逐步上升,但速度较慢。
验证集精度 长期停留在 48% ~ 53% 区间波动,几乎没有随训练改善。
出现典型的:
高维输入导致参数量巨大(32×32×3=3072维)
特征表达能力不足 → 难以捕捉局部图像结构
过拟合风险不断加剧 → 训练精度升,验证精度停滞
简而言之:
MLP 在 CIFAR10 这种复杂多类彩色图片上已经力不从心。
- CNN 从早期阶段就展现出显著优势
训练集精度 第一轮就达到了 ~49%,明显高于 MLP 的 42%。
验证集精度 随 epoch 持续提升,从 48% → 最终 71.0%。
并且 CNN 的训练线和验证线之间差距较小,说明泛化性良好。
这验证了 CNN 的结构优势:
卷积核能捕捉 局部空间信息
池化 & 步长提升模型的 平移不变性
BN 提升收敛速度与稳定性
参数量远小于 MLP,过拟合风险更低
- CNN 的提升速度明显更快
曲线中可以看到:
CNN 在 第 2 ~ 3 个 epoch 就已经达到 MLP 第 10 个 epoch 都无法达到的验证精度
随着迭代继续进行,两者差距持续被拉大
CNN 不仅最终精度更高,而且学习速度显著快于 MLP。
- 数据集复杂度越高,MLP 和 CNN 的差距会越大
Fashion-MNIST:两者差距有限
CIFAR10:差距明显
STL10:差距会进一步扩大(会在下一篇验证)
最终总结
通过 CIFAR10 的实验我们能够非常明确地得出:
随着数据维度和视觉复杂度的提升,MLP 的能力呈现下降趋势,而 CNN 的结构优势将快速显现。
CNN 在高维彩色图片上的泛化性能、特征提取能力与收敛速度均远胜于 MLP。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号