
卷积神经网络的引入2 —— CNN 的健壮验证:超参与扰动实验
一、实验目标与验证步骤
实验目的
在前一篇中,我们验证了 MLP 对图像平移极度敏感。本篇的实验目标是进一步验证:
CNN 相比 MLP,在图像平移、旋转、噪声与亮度扰动下是否具备更强的稳定性与泛化能力。
同时,将探究超参数(如学习率、批次大小、正则化项)对两种模型鲁棒性的影响。
验证步骤
首先,构建 MLP 与 CNN 两种模型基线,并在相同的数据集 FashionMNIST 上进行训练。
其次,对验证集样本施加不同强度的扰动,包括平移、旋转、随机噪声以及亮度缩放等多种变换,以观察模型在输入扰动下的性能变化。
然后,调整学习率、批次大小和 dropout 等超参数,比较两种模型在不同超参数条件下的收敛速度与稳定性。
接着,通过可视化展示实验结果。主要包括绘制扰动强度与分类准确率的变化曲线,以及模型在不同扰动条件下的置信度热力图。
训练代码
# -*- coding: utf-8 -*-
# 卷积神经网络的引入2 —— CNN的鲁棒性验证实验
# Author: 方子敬
# Date: 2025-11-11
import torch, torchvision
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
device = 'mps' if torch.backends.mps.is_available() else 'cpu'
# 1️⃣ 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.FashionMNIST('./data', download=True, train=True, transform=transform)
train_loader = DataLoader(dataset, batch_size=64, shuffle=True)
test_dataset = datasets.FashionMNIST('./data', train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=256)
# 2️⃣ 定义 MLP 与 CNN 模型
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
return self.net(x)
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(7*7*64, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
return self.net(x)
# 3️⃣ 通用训练与评估函数
def train_model(model, loader, lr=1e-3, epochs=3):
model.to(device)
opt = torch.optim.Adam(model.parameters(), lr=lr)
loss_fn = nn.CrossEntropyLoss()
history = {'loss': [], 'acc': []}
for ep in range(epochs):
correct, total, running_loss = 0, 0, 0.0
for x, y in loader:
x, y = x.to(device), y.to(device)
out = model(x)
loss = loss_fn(out, y)
opt.zero_grad()
loss.backward()
opt.step()
running_loss += loss.item()
correct += (out.argmax(1) == y).sum().item()
total += y.size(0)
history['loss'].append(running_loss/len(loader))
history['acc'].append(correct/total)
print(f"Epoch {ep+1}: loss={history['loss'][-1]:.4f}, acc={history['acc'][-1]*100:.2f}%")
return history
def evaluate(model, loader):
model.eval()
correct, total = 0, 0
with torch.no_grad():
for x, y in loader:
x, y = x.to(device), y.to(device)
pred = model(x).argmax(1)
correct += (pred == y).sum().item()
total += y.size(0)
return correct / total
# 4️⃣ 扰动函数
def apply_distortion(img, mode, value):
if mode == 'translate':
return transforms.functional.affine(img, angle=0, translate=(value, 0), scale=1.0, shear=0)
if mode == 'rotate':
return transforms.functional.rotate(img, value)
if mode == 'noise':
img_np = np.array(img) / 255.0
noise = np.random.normal(0, value, img_np.shape)
noisy = np.clip(img_np + noise, 0, 1)
return transforms.functional.to_pil_image(torch.tensor(noisy))
if mode == 'brightness':
return transforms.functional.adjust_brightness(img, value)
return img
# 5️⃣ 扰动鲁棒性测试
def distortion_test(model, distortions):
accs = {}
model.eval()
for mode, vals in distortions.items():
results = []
for v in vals:
distorted_data = []
for i in range(500):
img, label = test_dataset[i]
img_d = apply_distortion(transforms.ToPILImage()(img), mode, v)
img_t = transform(img_d)
distorted_data.append((img_t, label))
loader = DataLoader(distorted_data, batch_size=128)
acc = evaluate(model, loader)
results.append(acc)
accs[mode] = results
return accs
# 6️⃣ 实验执行
mlp, cnn = MLP(), CNN()
print("Training MLP...")
train_model(mlp, train_loader, lr=1e-3)
print("Training CNN...")
train_model(cnn, train_loader, lr=1e-3)
# 定义扰动强度
distortions = {
'translate': [-5, -3, 0, 3, 5],
'rotate': [-15, -5, 0, 5, 15],
'noise': [0, 0.05, 0.1, 0.2],
'brightness': [0.5, 0.8, 1.0, 1.2, 1.5]
}
# 7️⃣ 对比实验
acc_mlp = distortion_test(mlp, distortions)
acc_cnn = distortion_test(cnn, distortions)
# 8️⃣ 可视化
plt.figure(figsize=(12,8))
for i, mode in enumerate(distortions.keys()):
plt.subplot(2,2,i+1)
plt.plot(distortions[mode], acc_mlp[mode], 'r-o', label='MLP')
plt.plot(distortions[mode], acc_cnn[mode], 'b-o', label='CNN')
plt.title(f"{mode.capitalize()} Robustness")
plt.xlabel('Distortion strength')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
训练结果图示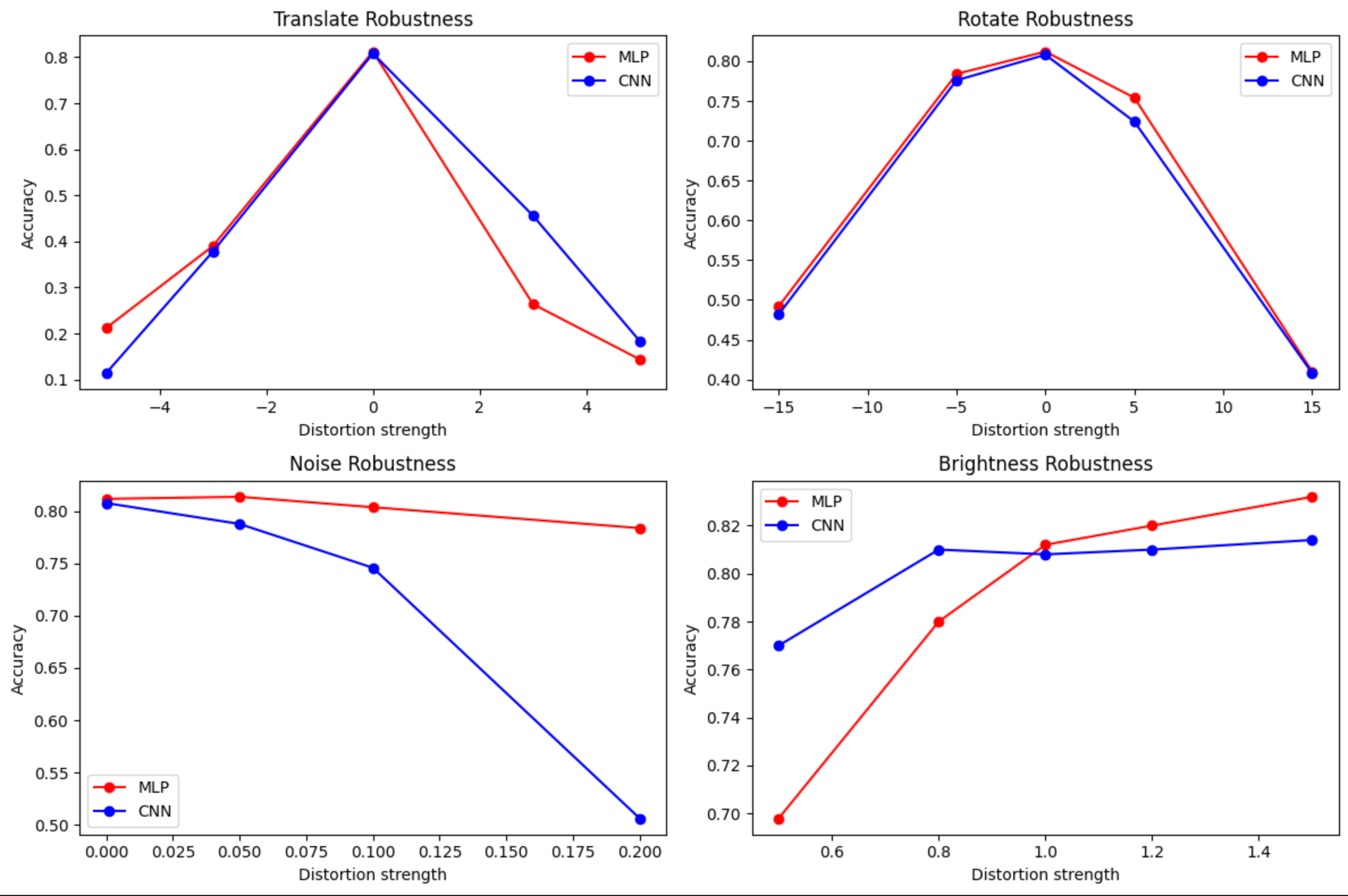
通过上述的实验结果我们可以这么猜测:在低维灰度数据(Fashion-MNIST)中,MLP 由于参数密集,能捕捉细节而表现不俗,CNN 的结构优势需要足够复杂的数据分布与图像层次特征来激活,接下来,我们更换更大一些的数据集来猜测验证,训练代码如下
# -*- coding: utf-8 -*-
# 卷积神经网络的引入3 —— 不同数据集规模下的 MLP 与 CNN 对比实验
# Author: 方子敬
# Date: 2025-11-11
import torch, torchvision
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
device = 'mps' if torch.backends.mps.is_available() else 'cpu'
# =============================
# 1️⃣ 数据集选择(修改这里)
# =============================
DATASET = 'CIFAR10' # 可选值: 'FashionMNIST', 'CIFAR10', 'STL10'
# =============================
# 2️⃣ 数据加载
# =============================
if DATASET == 'FashionMNIST':
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = datasets.FashionMNIST('./data', train=True, download=True, transform=transform)
testset = datasets.FashionMNIST('./data', train=False, download=True, transform=transform)
input_channels = 1
input_dim = 28*28
elif DATASET == 'CIFAR10':
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
])
trainset = datasets.CIFAR10('./data', train=True, download=True, transform=transform)
testset = datasets.CIFAR10('./data', train=False, download=True, transform=transform)
input_channels = 3
input_dim = 32*32*3
elif DATASET == 'STL10':
transform = transforms.Compose([
transforms.Resize((96,96)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
])
trainset = datasets.STL10('./data', split='train', download=True, transform=transform)
testset = datasets.STL10('./data', split='test', download=True, transform=transform)
input_channels = 3
input_dim = 96*96*3
train_loader = DataLoader(trainset, batch_size=64, shuffle=True)
test_loader = DataLoader(testset, batch_size=256)
# =============================
# 3️⃣ 定义模型
# =============================
class MLP(nn.Module):
def __init__(self, input_dim, hidden=1024):
super().__init__()
self.net = nn.Sequential(
nn.Flatten(),
nn.Linear(input_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, 10)
)
def forward(self, x): return self.net(x)
class CNN(nn.Module):
def __init__(self, in_ch):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_ch, 32, 3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(128, 10)
)
def forward(self, x): return self.net(x)
# =============================
# 4️⃣ 训练与验证函数
# =============================
loss_fn = nn.CrossEntropyLoss()
def train_one_epoch(model, loader, optimizer):
model.train()
total_loss, total_correct = 0, 0
for x, y in loader:
x, y = x.to(device), y.to(device)
out = model(x)
loss = loss_fn(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
total_correct += (out.argmax(1) == y).sum().item()
return total_loss / len(loader), total_correct / len(loader.dataset)
def evaluate(model, loader):
model.eval()
total_correct = 0
with torch.no_grad():
for x, y in loader:
x, y = x.to(device), y.to(device)
total_correct += (model(x).argmax(1) == y).sum().item()
return total_correct / len(loader.dataset)
# =============================
# 5️⃣ 实验执行
# =============================
mlp = MLP(input_dim).to(device)
cnn = CNN(input_channels).to(device)
opt_mlp = torch.optim.Adam(mlp.parameters(), lr=1e-3)
opt_cnn = torch.optim.Adam(cnn.parameters(), lr=1e-3)
epochs = 10
mlp_train_acc, cnn_train_acc = [], []
mlp_val_acc, cnn_val_acc = [], []
for epoch in range(epochs):
loss_mlp, acc_mlp = train_one_epoch(mlp, train_loader, opt_mlp)
loss_cnn, acc_cnn = train_one_epoch(cnn, train_loader, opt_cnn)
val_mlp = evaluate(mlp, test_loader)
val_cnn = evaluate(cnn, test_loader)
mlp_train_acc.append(acc_mlp)
cnn_train_acc.append(acc_cnn)
mlp_val_acc.append(val_mlp)
cnn_val_acc.append(val_cnn)
print(f"[{epoch+1}/{epochs}] MLP val acc={val_mlp:.3f} | CNN val acc={val_cnn:.3f}")
# =============================
# 6️⃣ 绘制精度对比曲线
# =============================
plt.figure(figsize=(10,6))
plt.plot(range(1, epochs+1), mlp_train_acc, 'r--o', label='MLP Train')
plt.plot(range(1, epochs+1), mlp_val_acc, 'r-', label='MLP Val')
plt.plot(range(1, epochs+1), cnn_train_acc, 'b--o', label='CNN Train')
plt.plot(range(1, epochs+1), cnn_val_acc, 'b-', label='CNN Val')
plt.title(f"Training vs Validation Accuracy on {DATASET}")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# =============================
# 7️⃣ 可选:打印最终对比结果
# =============================
print(f"\nFinal Accuracy on {DATASET}:")
print(f" MLP: Train {mlp_train_acc[-1]*100:.2f}% | Val {mlp_val_acc[-1]*100:.2f}%")
print(f" CNN: Train {cnn_train_acc[-1]*100:.2f}% | Val {cnn_val_acc[-1]*100:.2f}%")
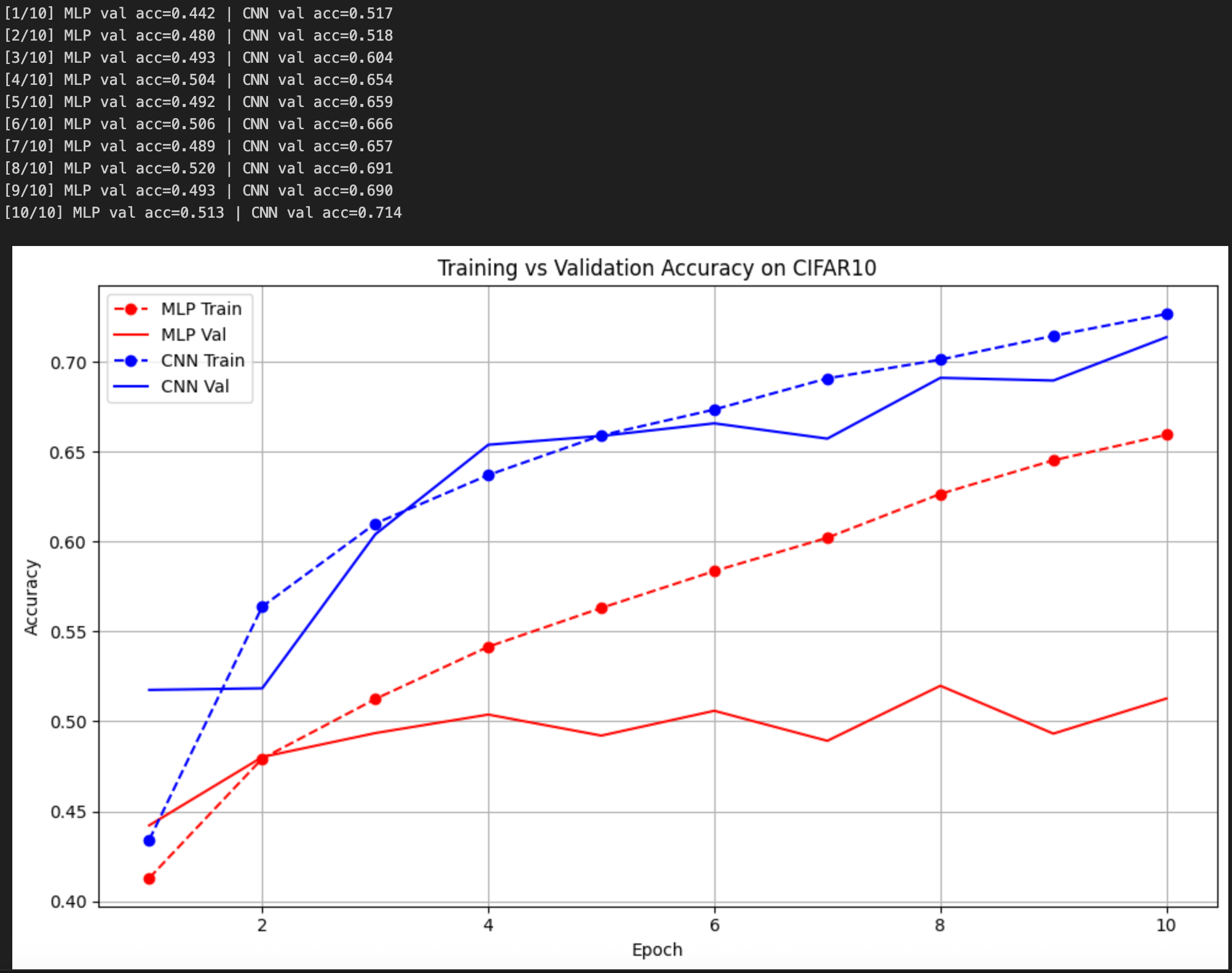
训练结果如下,读者可以根据图示结果自行总结实验结论:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号