
CNN 发展历程的下一站 —— VGG
VGG 模型的关键改进点
(2014, Very Deep Convolutional Networks for Large-Scale Image Recognition)
| 改进点 | AlexNet | VGG | 意义 |
|---|---|---|---|
| 卷积核设计 | 大卷积核(11×11, 5×5)+ 少量层 | 小卷积核(3×3)堆叠,网络更深(11-19 层) | 小卷积核参数更少,叠加后等效大感受野,能捕捉更丰富特征 |
| 网络深度 | 5 个卷积层 + 3 个全连接层 | 16/19 层卷积层 + 3 个全连接层 | 更深的层次结构,显著提升特征提取能力 |
| 池化方式 | 每隔几层使用 MaxPooling | 同样采用 MaxPooling(2×2, stride=2) | 保持空间降采样一致性 |
| 通道数设计 | Conv1: 96 → Conv5: 256 | Conv1: 64 → Conv5: 512 | 通道数逐层翻倍,容量更大 |
| 激活函数 | ReLU | ReLU | 保持一致,VGG 没有替换 |
| 归一化 | LRN(局部响应归一化) | 无(未使用 LRN/BN) | 论文中未引入 BN,后续 BN 成为主流 |
| 参数规模 | ~24M | ~138M(VGG-16) | 大幅增加,计算和存储开销显著 |
| 主要贡献 | 更深 + 大卷积核 | 更深 + 小卷积核堆叠 | 提供了统一、简洁的架构范式 |
VGG vs AlexNet(CIFAR-10)实验设计概览
| 维度 | AlexNet-mini | VGG-mini(11/16) | 统一设置 |
|---|---|---|---|
| 卷积核 | 3×3 堆叠 + 几层较宽通道 | 纯 3×3 堆叠,更深 | 输入 3×32×32 |
| 深度 | 5 个卷积 stage | 5 个 stage(每 stage 2~3 个 conv) | 训练/测试增强一致 |
| 通道规划 | 64→192→384→256→256 | 64→128→256→512→512 | Label Smoothing=0.1 |
| 归一化 | (可选)BN | BN(实操中常配套) | Optim=AdamW, WD=5e-4 |
| 正则化 | Dropout(0.5) | Dropout(0.3~0.5) | StepLR/OneCycleLR |
| 池化 | MaxPool 2×2 | MaxPool 2×2 | Epoch=5~30(视时间) |
| 期望 | 收敛较快,容量中等 | 表达力更强,最终更优 | 统一评测 Top-1 / Loss |
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
import time
# ============ 设备 ============
device = torch.device("cuda" if torch.cuda.is_available() else
"mps" if torch.backends.mps.is_available() else "cpu")
print("使用设备:", device)
# ============ 数据增强 ============
mean, std = (0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
# ============ 模型定义 ============
class AlexNetMini(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64, 192, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(192, 384, 3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, 3, padding=1), nn.ReLU(),
nn.Conv2d(256, 256, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256*4*4, 1024), nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(1024, 512), nn.ReLU(),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
return self.classifier(x)
class VGG11Mini(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
def block(in_c, out_c, n_conv):
layers = []
for i in range(n_conv):
layers.append(nn.Conv2d(in_c if i==0 else out_c, out_c, 3, padding=1))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.MaxPool2d(2))
return nn.Sequential(*layers)
self.features = nn.Sequential(
block(3, 64, 1),
block(64, 128, 1),
block(128, 256, 2),
block(256, 512, 2),
block(512, 512, 2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Dropout(0.5),
nn.Linear(512, 512), nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
return self.classifier(x)
# ============ 训练与测试函数 ============
def train_epoch(model, loader, criterion, optimizer):
model.train()
loss_total, correct, total = 0, 0, 0
for imgs, labels in loader:
imgs, labels = imgs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(imgs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
loss_total += loss.item()
_, pred = outputs.max(1)
total += labels.size(0)
correct += pred.eq(labels).sum().item()
return loss_total/len(loader), 100.*correct/total
def test_epoch(model, loader, criterion):
model.eval()
loss_total, correct, total = 0, 0, 0
with torch.no_grad():
for imgs, labels in loader:
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
loss_total += loss.item()
_, pred = outputs.max(1)
total += labels.size(0)
correct += pred.eq(labels).sum().item()
return loss_total/len(loader), 100.*correct/total
# ============ 训练流程 ============
def run_exp(model, name, epochs=5, lr=0.001):
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
hist = {"train_loss":[], "train_acc":[], "test_loss":[], "test_acc":[]}
for epoch in range(1, epochs+1):
tl, ta = train_epoch(model, trainloader, criterion, optimizer)
vl, va = test_epoch(model, testloader, criterion)
hist["train_loss"].append(tl)
hist["train_acc"].append(ta)
hist["test_loss"].append(vl)
hist["test_acc"].append(va)
print(f"{name} | Epoch {epoch}/{epochs} | TL={tl:.3f} TA={ta:.2f}% | VL={vl:.3f} VA={va:.2f}%")
return hist
# ============ 同时训练 AlexNet-mini & VGG11-mini ============
alex_hist = run_exp(AlexNetMini(), "AlexNet-mini", epochs=5)
vgg_hist = run_exp(VGG11Mini(), "VGG11-mini", epochs=5)
# ============ 绘制对比曲线 ============
epochs = range(1, len(alex_hist["train_loss"])+1)
plt.figure(figsize=(14,6))
# Loss
plt.subplot(1,2,1)
plt.plot(epochs, alex_hist["train_loss"], "r-", label="AlexNet Train")
plt.plot(epochs, alex_hist["test_loss"], "r--", label="AlexNet Test")
plt.plot(epochs, vgg_hist["train_loss"], "b-", label="VGG11 Train")
plt.plot(epochs, vgg_hist["test_loss"], "b--", label="VGG11 Test")
plt.title("Loss Comparison"); plt.xlabel("Epoch"); plt.ylabel("Loss"); plt.legend(); plt.grid(True, alpha=0.3)
# Accuracy
plt.subplot(1,2,2)
plt.plot(epochs, alex_hist["train_acc"], "r-", label="AlexNet Train")
plt.plot(epochs, alex_hist["test_acc"], "r--", label="AlexNet Test")
plt.plot(epochs, vgg_hist["train_acc"], "b-", label="VGG11 Train")
plt.plot(epochs, vgg_hist["test_acc"], "b--", label="VGG11 Test")
plt.title("Accuracy Comparison"); plt.xlabel("Epoch"); plt.ylabel("Accuracy (%)"); plt.legend(); plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
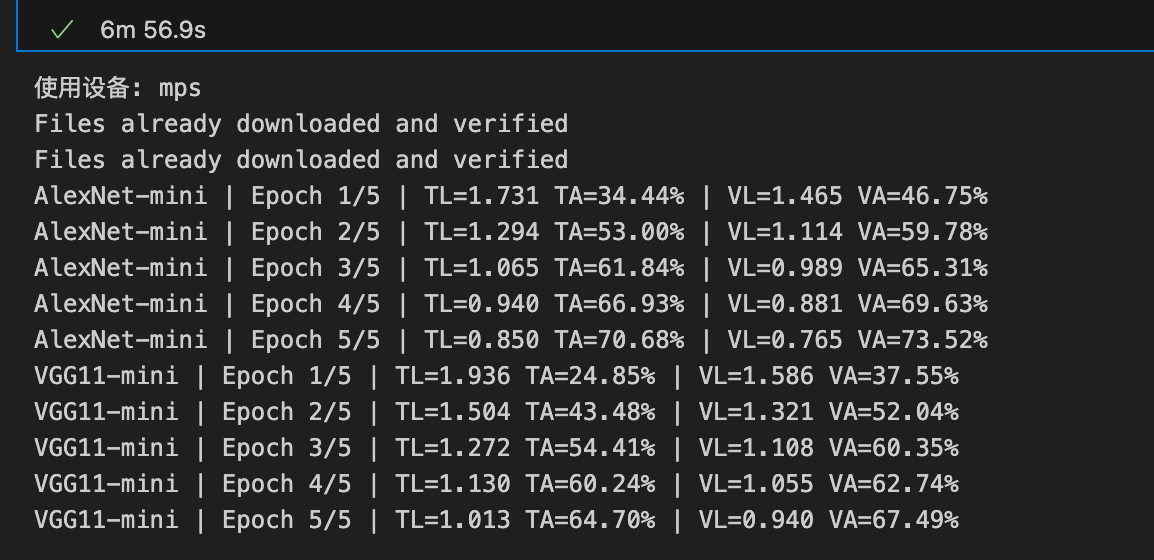

图中可以看到在只训练五轮的时候VGG的表现不如Alex,可能的原因是模型相对简单的Alex收敛的更快,导致预测的结果便好,需要调节一些超参来看对训练结果的影响

 浙公网安备 33010602011771号
浙公网安备 33010602011771号