
AlexNet vs LeNet 对比实验
1. AlexNet 论文的关键创新点
(2012, ImageNet Classification with Deep Convolutional Neural Networks)
| 创新点 | 简述 | 意义 |
|---|---|---|
| ReLU 激活函数 | 用 ReLU 替代 Sigmoid/Tanh | 缓解梯度消失,训练速度更快 |
| Dropout 正则化 | 全连接层使用 Dropout | 有效防止过拟合 |
| 数据增强 | 平移、镜像、裁剪 | 提升泛化性能 |
| GPU 并行训练 | 使用两块 GTX 580 训练 | 使大规模 CNN 训练成为可能 |
| 更深网络结构 | 5 个卷积层 + 3 个全连接层 | 能力大幅提升,ImageNet 错误率大幅降低 |
| 局部响应归一化 (LRN, 后续常用 BN 替代) | 模拟神经抑制 | 增强泛化(现代 CNN 多用 BN 替代) |
-
关键差异
特性LeNetAlexNet卷积层数2层5层全连接层3层3层激活函数ReLUReLUDropout无有(0.5)参数量62K24M
主要特点 1: LeNet-5: 经典的轻量级CNN,约62K参数 2: AlexNet: 更深更宽的网络,约24M参数(适配CIFAR-10) -
训练设置
LeNet vs AlexNet 实验模型差异对比
实验简介 这个实验在CIFAR-10数据集上对比了经典的LeNet-5和AlexNet两个卷积神经网络架构,展示了模型架构演进带来的性能提升。
| 维度 | LeNet(实验A) | AlexNet-mini(实验B) | 说明 |
|---|---|---|---|
| 卷积层深度 | 2 个卷积块(Conv→Pool) | 3 个 stage × 每 stage 2 个卷积 + Pool(共 6 个卷积层) | AlexNet 更深,特征提取能力更强 |
| 卷积核大小 | 5×5 | 3×3 堆叠 | 更细粒度的特征提取,参数更高效 |
| 通道数 | 6 → 16 | 64 → 128 → 256 | 通道数更多,表达能力更强 |
| 激活函数 | ReLU | ReLU | AlexNet 论文强调 ReLU 的优势,为公平实验保持一致 |
| 归一化 | 无 | BatchNorm | 稳定分布、加快收敛(论文用 LRN,这里用 BN 替代) |
| 池化方式 | 最大池化 (MaxPool) | 最大池化 (MaxPool) | AlexNet 原论文也是 MaxPool,为公平一致 |
| 正则化 | Dropout(0.5) + L2 | Dropout(0.5) + L2 | 论文提出 Dropout,这里两模型都采用 |
| 数据增强 | 无(MNIST/F-MNIST) 随机裁剪+翻转(CIFAR-10) |
同左 | 保持一致,体现论文提出的数据增强思想 |
| 输入数据 | MNIST/F-MNIST: 1×28×28 CIFAR-10: 3×32×32 |
同左 | 输入保持一致,只比较网络结构差异 |
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
import time
# 设置设备
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"使用设备: {device}")
# ==================== LeNet-5 模型 ====================
class LeNet(nn.Module):
def __init__(self, num_classes=10):
super(LeNet, self).__init__()
self.features = nn.Sequential(
# Conv1: 3x32x32 -> 6x28x28
nn.Conv2d(3, 6, kernel_size=5),
nn.ReLU(),
# Pool1: 6x28x28 -> 6x14x14
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv2: 6x14x14 -> 16x10x10
nn.Conv2d(6, 16, kernel_size=5),
nn.ReLU(),
# Pool2: 16x10x10 -> 16x5x5
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# ==================== AlexNet 模型 ====================
class AlexNet(nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# Conv1: 3x32x32 -> 64x8x8 (适配CIFAR-10的小尺寸)
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv2: 64x16x16 -> 192x16x16
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Conv3: 192x8x8 -> 384x8x8
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# Conv4: 384x8x8 -> 256x8x8
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# Conv5: 256x8x8 -> 256x8x8
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 4 * 4, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# ==================== 数据加载 ====================
def load_data(batch_size=128):
"""加载CIFAR-10数据集"""
# 数据增强
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 下载并加载训练集
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train
)
trainloader = DataLoader(
trainset, batch_size=batch_size, shuffle=True, num_workers=2
)
# 下载并加载测试集
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test
)
testloader = DataLoader(
testset, batch_size=batch_size, shuffle=False, num_workers=2
)
return trainloader, testloader
# ==================== 训练函数 ====================
def train_epoch(model, trainloader, criterion, optimizer, device):
"""训练一个epoch"""
model.train()
running_loss = 0.0
correct = 0
total = 0
pbar = tqdm(trainloader, desc='训练中')
for inputs, labels in pbar:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
pbar.set_postfix({
'loss': running_loss / (pbar.n + 1),
'acc': 100. * correct / total
})
epoch_loss = running_loss / len(trainloader)
epoch_acc = 100. * correct / total
return epoch_loss, epoch_acc
# ==================== 测试函数 ====================
def test(model, testloader, criterion, device):
"""在测试集上评估模型"""
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in tqdm(testloader, desc='测试中'):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
test_loss = test_loss / len(testloader)
test_acc = 100. * correct / total
return test_loss, test_acc
# ==================== 训练模型 ====================
def train_model(model, model_name, trainloader, testloader, num_epochs=30, lr=0.001):
"""完整的训练流程"""
print(f"\n{'='*50}")
print(f"开始训练 {model_name}")
print(f"{'='*50}")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.5) # 2个epoch后衰减
train_losses = []
train_accs = []
test_losses = []
test_accs = []
best_acc = 0.0
start_time = time.time()
for epoch in range(num_epochs):
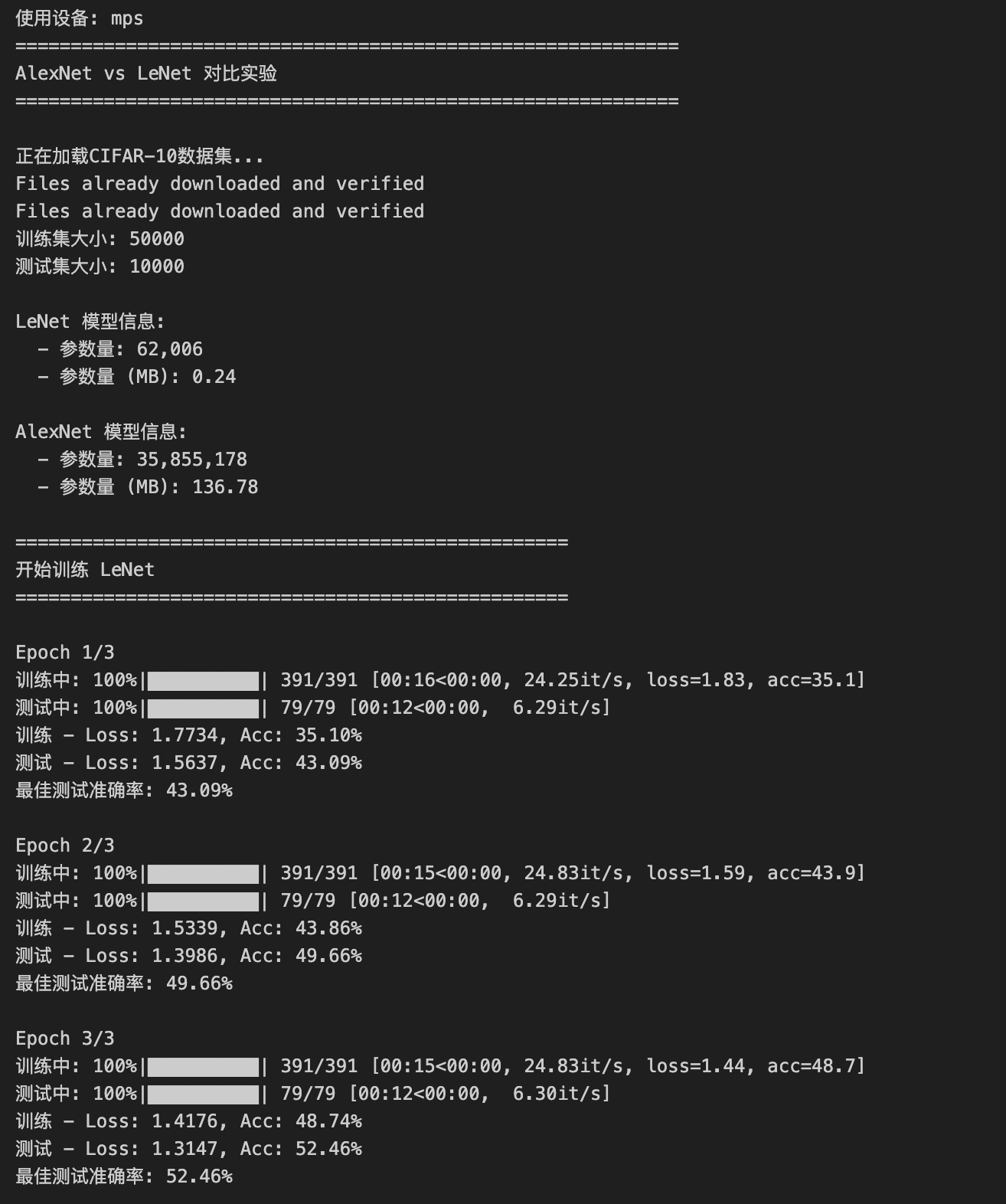
print(f'\nEpoch {epoch+1}/{num_epochs}')
# 训练
train_loss, train_acc = train_epoch(model, trainloader, criterion, optimizer, device)
train_losses.append(train_loss)
train_accs.append(train_acc)
# 测试
test_loss, test_acc = test(model, testloader, criterion, device)
test_losses.append(test_loss)
test_accs.append(test_acc)
# 更新学习率
scheduler.step()
# 保存最佳模型
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), f'{model_name}_best.pth')
print(f'训练 - Loss: {train_loss:.4f}, Acc: {train_acc:.2f}%')
print(f'测试 - Loss: {test_loss:.4f}, Acc: {test_acc:.2f}%')
print(f'最佳测试准确率: {best_acc:.2f}%')
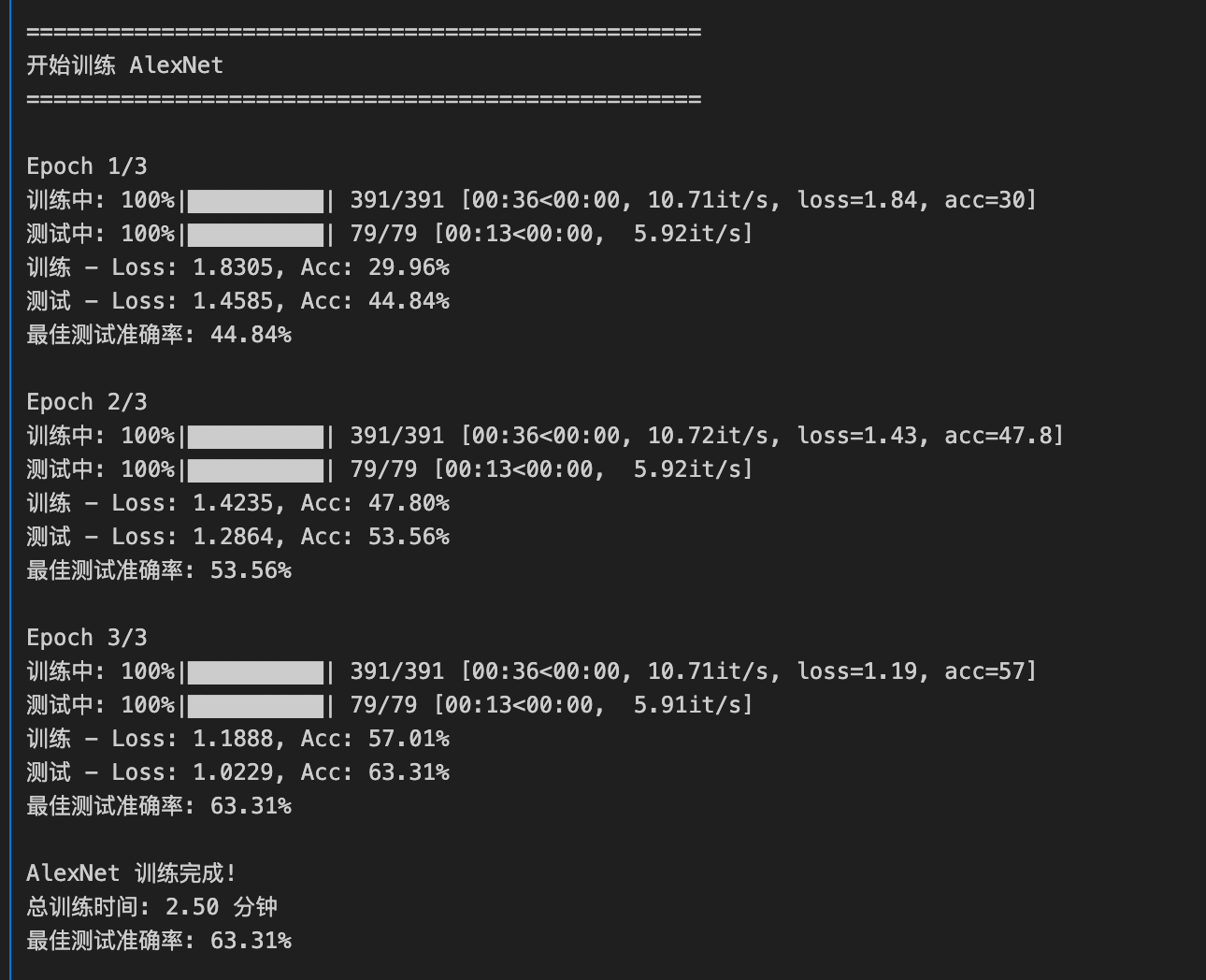
total_time = time.time() - start_time
print(f'\n{model_name} 训练完成!')
print(f'总训练时间: {total_time/60:.2f} 分钟')
print(f'最佳测试准确率: {best_acc:.2f}%')
return {
'train_losses': train_losses,
'train_accs': train_accs,
'test_losses': test_losses,
'test_accs': test_accs,
'best_acc': best_acc
}
# ==================== 绘制对比图 ====================
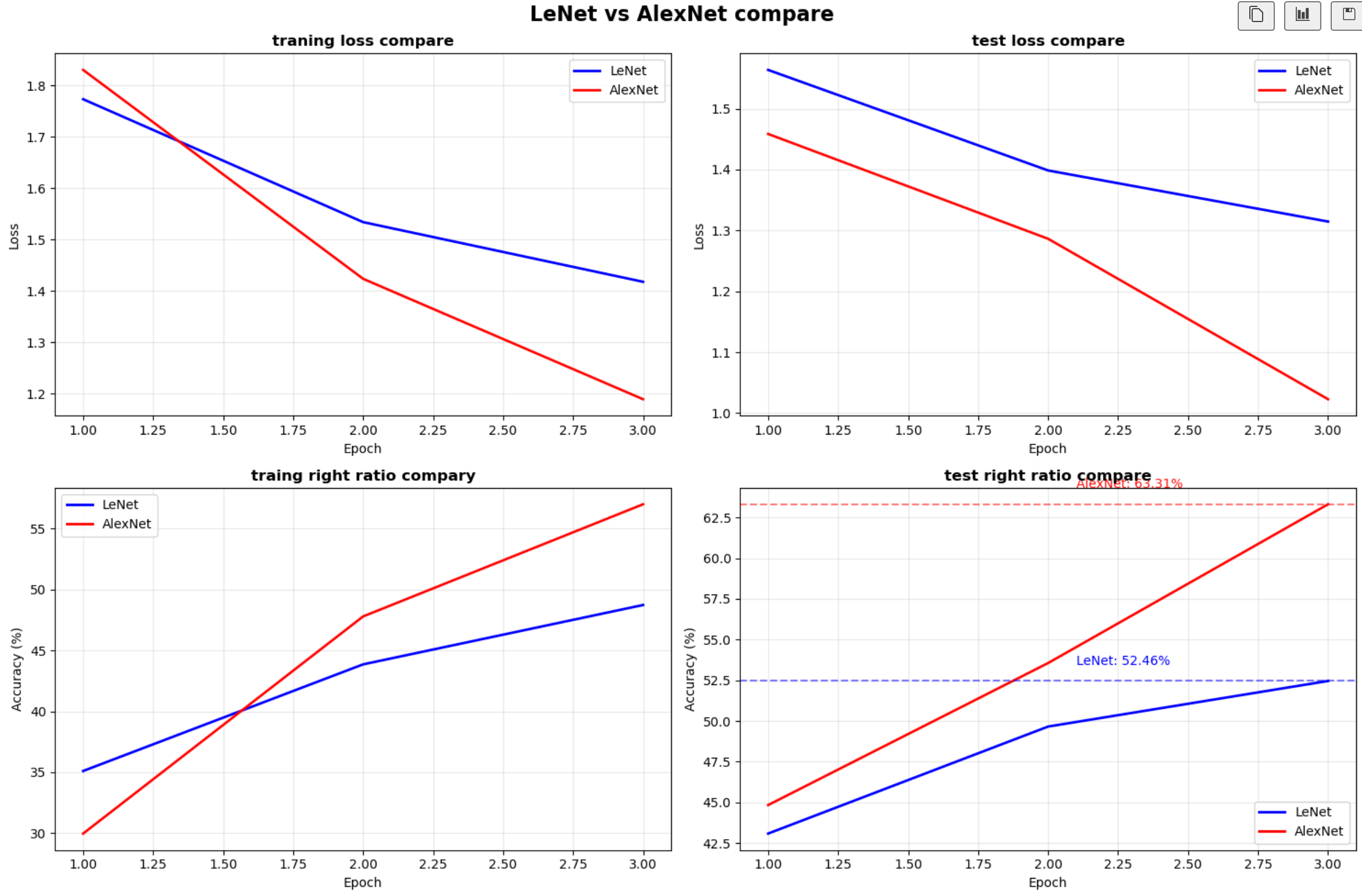
def plot_comparison(lenet_history, alexnet_history):
"""绘制两个模型的对比图"""
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('LeNet vs AlexNet 性能对比', fontsize=16, fontweight='bold')
epochs = range(1, len(lenet_history['train_losses']) + 1)
# 1. 训练损失对比
axes[0, 0].plot(epochs, lenet_history['train_losses'], 'b-', label='LeNet', linewidth=2)
axes[0, 0].plot(epochs, alexnet_history['train_losses'], 'r-', label='AlexNet', linewidth=2)
axes[0, 0].set_title('训练损失对比', fontsize=12, fontweight='bold')
axes[0, 0].set_xlabel('Epoch')
axes[0, 0].set_ylabel('Loss')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 2. 测试损失对比
axes[0, 1].plot(epochs, lenet_history['test_losses'], 'b-', label='LeNet', linewidth=2)
axes[0, 1].plot(epochs, alexnet_history['test_losses'], 'r-', label='AlexNet', linewidth=2)
axes[0, 1].set_title('测试损失对比', fontsize=12, fontweight='bold')
axes[0, 1].set_xlabel('Epoch')
axes[0, 1].set_ylabel('Loss')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 3. 训练准确率对比
axes[1, 0].plot(epochs, lenet_history['train_accs'], 'b-', label='LeNet', linewidth=2)
axes[1, 0].plot(epochs, alexnet_history['train_accs'], 'r-', label='AlexNet', linewidth=2)
axes[1, 0].set_title('训练准确率对比', fontsize=12, fontweight='bold')
axes[1, 0].set_xlabel('Epoch')
axes[1, 0].set_ylabel('Accuracy (%)')
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# 4. 测试准确率对比
axes[1, 1].plot(epochs, lenet_history['test_accs'], 'b-', label='LeNet', linewidth=2)
axes[1, 1].plot(epochs, alexnet_history['test_accs'], 'r-', label='AlexNet', linewidth=2)
axes[1, 1].set_title('测试准确率对比', fontsize=12, fontweight='bold')
axes[1, 1].set_xlabel('Epoch')
axes[1, 1].set_ylabel('Accuracy (%)')
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
# 添加最佳准确率标注
lenet_best = lenet_history['best_acc']
alexnet_best = alexnet_history['best_acc']
axes[1, 1].axhline(y=lenet_best, color='b', linestyle='--', alpha=0.5)
axes[1, 1].axhline(y=alexnet_best, color='r', linestyle='--', alpha=0.5)
axes[1, 1].text(len(epochs)*0.7, lenet_best+1, f'LeNet: {lenet_best:.2f}%', color='b')
axes[1, 1].text(len(epochs)*0.7, alexnet_best+1, f'AlexNet: {alexnet_best:.2f}%', color='r')
plt.tight_layout()
plt.savefig('/mnt/user-data/outputs/model_comparison.png', dpi=300, bbox_inches='tight')
print("\n对比图已保存到: model_comparison.png")
plt.show()
# ==================== 模型参数统计 ====================
def count_parameters(model):
"""统计模型参数量"""
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def print_model_info(model, model_name):
"""打印模型信息"""
params = count_parameters(model)
print(f"\n{model_name} 模型信息:")
print(f" - 参数量: {params:,}")
print(f" - 参数量 (MB): {params * 4 / 1024 / 1024:.2f}")
# ==================== 主函数 ====================
def main():
# 设置随机种子
torch.manual_seed(42)
if torch.backends.mps.is_available():
torch.mps.manual_seed(42)
# 超参数设置
BATCH_SIZE = 128
NUM_EPOCHS = 3 # 快速实验版本
LEARNING_RATE = 0.001
print("="*60)
print("AlexNet vs LeNet 对比实验")
print("="*60)
# 加载数据
print("\n正在加载CIFAR-10数据集...")
trainloader, testloader = load_data(batch_size=BATCH_SIZE)
print(f"训练集大小: {len(trainloader.dataset)}")
print(f"测试集大小: {len(testloader.dataset)}")
# 创建模型
lenet = LeNet(num_classes=10)
alexnet = AlexNet(num_classes=10)
# 打印模型信息
print_model_info(lenet, "LeNet")
print_model_info(alexnet, "AlexNet")
# 训练LeNet
lenet_history = train_model(
lenet, "LeNet", trainloader, testloader,
num_epochs=NUM_EPOCHS, lr=LEARNING_RATE
)
# 训练AlexNet
alexnet_history = train_model(
alexnet, "AlexNet", trainloader, testloader,
num_epochs=NUM_EPOCHS, lr=LEARNING_RATE
)
# 绘制对比图
print("\n正在生成对比图...")
plot_comparison(lenet_history, alexnet_history)
# 打印最终对比结果
print("\n" + "="*60)
print("实验结果总结")
print("="*60)
print(f"LeNet 最佳测试准确率: {lenet_history['best_acc']:.2f}%")
print(f"AlexNet 最佳测试准确率: {alexnet_history['best_acc']:.2f}%")
print(f"准确率提升: {alexnet_history['best_acc'] - lenet_history['best_acc']:.2f}%")
print("\n模型架构对比:")
print(f" LeNet: {count_parameters(lenet):,} 参数")
print(f" AlexNet: {count_parameters(alexnet):,} 参数")
print(f" 参数量比例: {count_parameters(alexnet) / count_parameters(lenet):.1f}x")
print("="*60)
if __name__ == "__main__":
main()
模型更改与性能提升总结
| 改进点 | LeNet | AlexNet | 提升效果 | 为什么能提升 |
|---|---|---|---|---|
| 网络深度 | 2 个卷积层 | 5 个卷积层 | 特征提取能力增强 | 更深层能够逐层抽象出更复杂的空间与语义特征 |
| 卷积核设计 | 单一 5×5 | 大卷积核 + 小卷积核组合 (11×11, 5×5, 3×3) | 多尺度特征提取 | 大卷积核捕捉全局结构,小卷积核精细提取局部信息 |
| 通道数 | 6→16 | 96→256→384→384→256 | 更强的表征容量 | 更多卷积核意味着可以学习更丰富的模式 |
| 激活函数 | Sigmoid/Tanh(原始 LeNet) | ReLU | 训练更快,梯度更稳定 | ReLU 缓解梯度消失,加速收敛 |
| 归一化 | 无 | LRN(后续 BN 替代) | 稳定训练 | 归一化层抑制激活爆炸/梯度不稳定,提高泛化 |
| 池化方式 | 平均池化 | 最大池化 | 保留关键特征 | MaxPool 强调显著特征,减少背景干扰 |
| 正则化 | 无 | Dropout | 降低过拟合 | Dropout 随机丢弃神经元,提升泛化能力 |
| 数据增强 | 无 | 平移、镜像、裁剪 | 泛化显著提升 | 模拟数据多样性,减少模型对训练集的记忆化 |
| 硬件支持 | CPU 训练 | GPU 并行 | 可训练更深模型 | GPU 大幅缩短训练时间,使大规模深度网络可行 |
📌 总结:
AlexNet 相比 LeNet 的提升,主要来自 “更深 + 更宽的网络结构” 提供了更强的特征提取能力,配合 ReLU、归一化、Dropout、数据增强 让训练更稳定、泛化更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号