
第一个实战任务:MNIST 手写数字识别,以及超参调节有什么影响
!!!一下训练的样本我是通过mps进行加速了训练过程中,如果使用NVIDIA 显卡需自己进行调整device
通过torchvision.datasets.MNIST 我们可以下载到已经准备好的素材,可以通过一下代码进行训练
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 1) 数据集:MNIST
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 2) 定义 MLP 模型
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 256) # 输入层 → 隐藏层
self.fc2 = nn.Linear(256, 128) # 隐藏层 → 隐藏层
self.fc3 = nn.Linear(128, 10) # 输出层 → 10 分类
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 28*28) # 拉直 [batch, 1, 28, 28] → [batch, 784]
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
model = MLP()
# 3) 定义损失 & 优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 4) 训练
for epoch in range(5):
model.train()
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss={loss.item():.4f}")
# 5) 测试
model.eval()
correct, total = 0, 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Test Accuracy: {100 * correct / total:.2f}%")
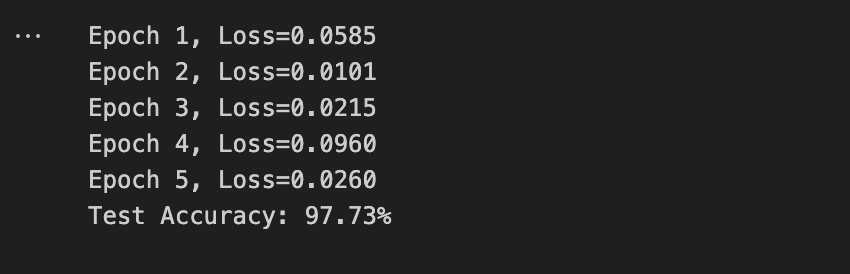
通过上述的代码和训练出来的结果我们可以看到MLP已经能够对图片进行识别和分类,但是有几个核心的问题需要我们思考,
1:训练过程中如果缩小训练的样本数量会导致结果怎么样
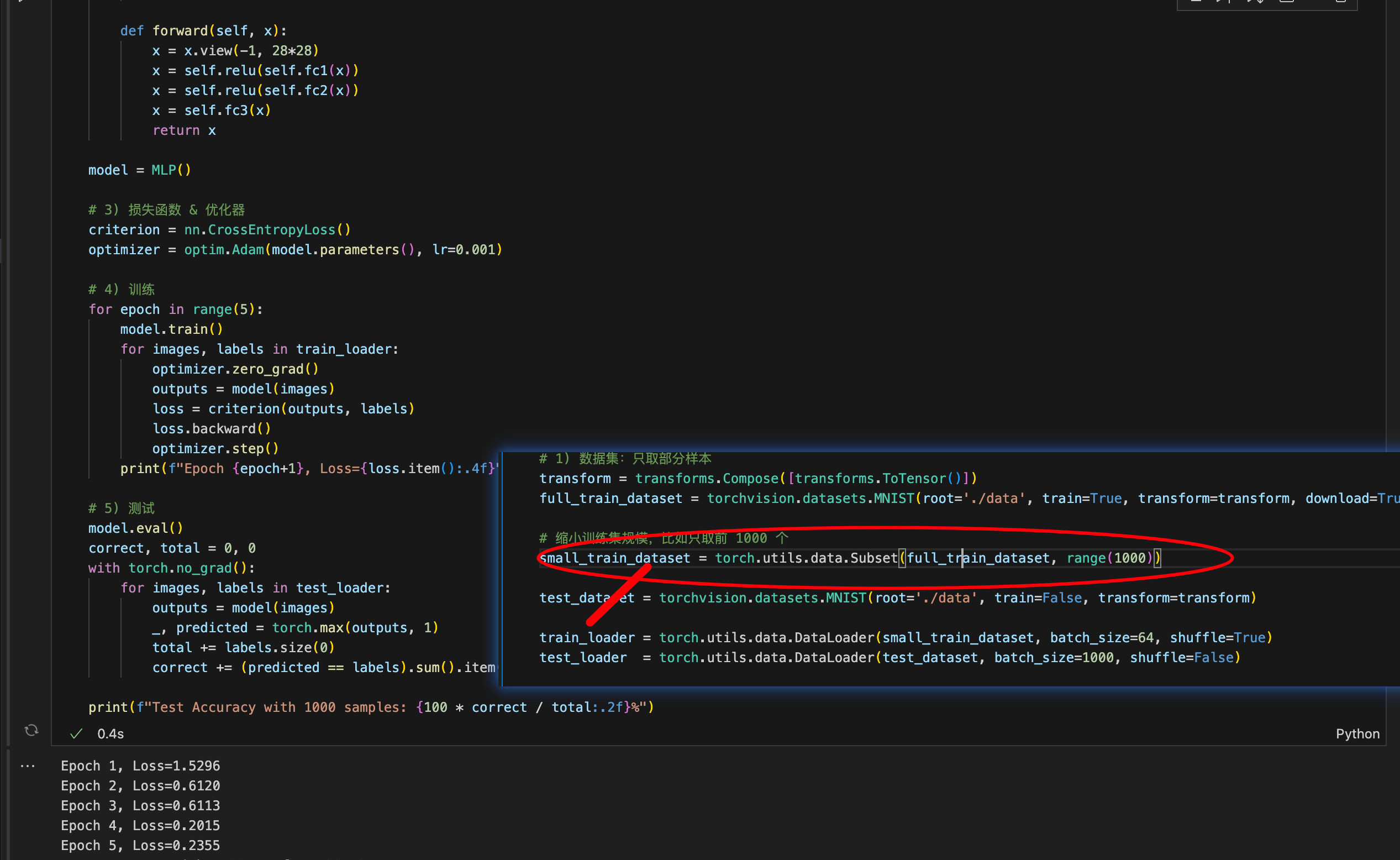
保持其他参数不变,我们看到缩小样本量导致识别的准确率降低
2: 为什么选择256个隐藏的神经元,如果增加神经元的个数有什么作用
3:隐藏层选择多少层
4:激活函数为什么选择了RELU,还有哪些激活函数对预测结果有什么影响
5:损失函数为什么选择了CrossEntropy,损失函数有哪些,分别有什么影响
6:优化器选择了optim.Adam,优化器的作用是什么,优化器的变化对预测结果有什么影响
7:batch_size批量训练大小选择多少合适,对训练的效率和准确率有什么影响,接下来我们通过调整上述的参数来做实验演示,然后通过分析的图标来了解超参的调节和判断
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import time
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 设置中文显示
rcParams['font.sans-serif'] = ['Arial Unicode MS'] # macOS
rcParams['axes.unicode_minus'] = False
# 设置设备为MPS
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print(f"Using device: {device}")
print(f"MPS available: {torch.backends.mps.is_available()}")
print(f"MPS built: {torch.backends.mps.is_built()}\n")
# ==================== 公共模块 ====================
# 灵活的 MLP 模型定义
class FlexibleMLP(nn.Module):
def __init__(self, hidden_sizes=[256, 128], activation='relu'):
"""
hidden_sizes: 隐藏层神经元数量列表,如 [256, 128] 表示两层隐藏层
activation: 激活函数类型 ('relu', 'tanh', 'sigmoid', 'leaky_relu')
"""
super().__init__()
layers = []
input_size = 28 * 28
# 构建隐藏层
for hidden_size in hidden_sizes:
layers.append(nn.Linear(input_size, hidden_size))
# 选择激活函数
if activation == 'relu':
layers.append(nn.ReLU())
elif activation == 'tanh':
layers.append(nn.Tanh())
elif activation == 'sigmoid':
layers.append(nn.Sigmoid())
elif activation == 'leaky_relu':
layers.append(nn.LeakyReLU())
input_size = hidden_size
# 输出层
layers.append(nn.Linear(input_size, 10))
self.network = nn.Sequential(*layers)
def forward(self, x):
x = x.view(-1, 28*28)
return self.network(x)
# 通用训练和测试函数(MPS优化版)
def train_and_evaluate(
model,
train_loader,
test_loader,
criterion,
optimizer,
epochs=5
):
"""训练并评估模型,返回准确率和训练时间"""
# 确保模型在MPS上
model = model.to(device)
criterion = criterion.to(device)
train_start = time.time()
# 训练
for epoch in range(epochs):
model.train()
for images, labels in train_loader:
# 数据移到MPS
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_time = time.time() - train_start
# 测试
model.eval()
correct, total = 0, 0
with torch.no_grad():
for images, labels in test_loader:
# 数据移到MPS
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return accuracy, train_time
# 数据准备函数
def prepare_data(train_size=None, batch_size=64):
"""准备MNIST数据集"""
transform = transforms.Compose([transforms.ToTensor()])
full_train_dataset = torchvision.datasets.MNIST(
root='./data', train=True, transform=transform, download=True
)
test_dataset = torchvision.datasets.MNIST(
root='./data', train=False, transform=transform
)
# 如果指定训练集大小,则截取
if train_size:
train_dataset = torch.utils.data.Subset(full_train_dataset, range(train_size))
else:
train_dataset = full_train_dataset
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True,
num_workers=0, # macOS上建议设为0
pin_memory=False # MPS不需要pin_memory
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=1000, shuffle=False,
num_workers=0,
pin_memory=False
)
return train_loader, test_loader
# ==================== 实验设计 ====================
def experiment_sample_size():
"""实验1: 样本数量的影响"""
print("="*60)
print("实验1: 训练样本数量的影响")
print("="*60)
sample_sizes = [500, 1000, 2000, 5000, 10000, 30000, 60000]
accuracies = []
train_times = []
for size in sample_sizes:
print(f"Training with {size} samples...")
train_loader, test_loader = prepare_data(train_size=size, batch_size=64)
model = FlexibleMLP(hidden_sizes=[256, 128])
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
acc, t = train_and_evaluate(model, train_loader, test_loader, criterion, optimizer)
accuracies.append(acc)
train_times.append(t)
print(f" Accuracy: {acc:.2f}%, Time: {t:.2f}s\n")
return sample_sizes, accuracies, train_times
def experiment_hidden_neurons():
"""实验2: 隐藏层神经元数量的影响"""
print("="*60)
print("实验2: 隐藏层神经元数量的影响 (保持2层隐藏层)")
print("="*60)
neuron_configs = [
[64, 32], [128, 64], [256, 128], [512, 256], [1024, 512]
]
config_labels = ['64-32', '128-64', '256-128', '512-256', '1024-512']
accuracies = []
train_times = []
train_loader, test_loader = prepare_data(train_size=10000, batch_size=64)
for config, label in zip(neuron_configs, config_labels):
print(f"Training with hidden layers: {label}...")
model = FlexibleMLP(hidden_sizes=config)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
acc, t = train_and_evaluate(model, train_loader, test_loader, criterion, optimizer)
accuracies.append(acc)
train_times.append(t)
print(f" Accuracy: {acc:.2f}%, Time: {t:.2f}s\n")
return config_labels, accuracies, train_times
def experiment_num_layers():
"""实验3: 隐藏层层数的影响"""
print("="*60)
print("实验3: 隐藏层数量的影响")
print("="*60)
layer_configs = [
[256], # 1层
[256, 128], # 2层
[256, 128, 64], # 3层
[512, 256, 128, 64], # 4层
[512, 256, 128, 64, 32] # 5层
]
config_labels = ['1层', '2层', '3层', '4层', '5层']
accuracies = []
train_times = []
train_loader, test_loader = prepare_data(train_size=10000, batch_size=64)
for config, label in zip(layer_configs, config_labels):
print(f"Training with {label}...")
model = FlexibleMLP(hidden_sizes=config)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
acc, t = train_and_evaluate(model, train_loader, test_loader, criterion, optimizer)
accuracies.append(acc)
train_times.append(t)
print(f" Accuracy: {acc:.2f}%, Time: {t:.2f}s\n")
return config_labels, accuracies, train_times
def experiment_activation():
"""实验4: 激活函数的影响"""
print("="*60)
print("实验4: 激活函数的影响")
print("="*60)
activations = ['relu', 'tanh', 'sigmoid', 'leaky_relu']
activation_names = ['ReLU', 'Tanh', 'Sigmoid', 'LeakyReLU']
accuracies = []
train_times = []
train_loader, test_loader = prepare_data(train_size=10000, batch_size=64)
for act, name in zip(activations, activation_names):
print(f"Training with {name} activation...")
model = FlexibleMLP(hidden_sizes=[256, 128], activation=act)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
acc, t = train_and_evaluate(model, train_loader, test_loader, criterion, optimizer)
accuracies.append(acc)
train_times.append(t)
print(f" Accuracy: {acc:.2f}%, Time: {t:.2f}s\n")
return activation_names, accuracies, train_times
def experiment_loss_function():
"""实验5: 损失函数的影响(新增实验)"""
print("="*60)
print("实验5: 损失函数的影响")
print("="*60)
loss_names = ['CrossEntropy', 'NLLLoss']
accuracies = []
train_times = []
train_loader, test_loader = prepare_data(train_size=10000, batch_size=64)
for loss_name in loss_names:
print(f"Training with {loss_name}...")
if loss_name == 'CrossEntropy':
model = FlexibleMLP(hidden_sizes=[256, 128])
criterion = nn.CrossEntropyLoss()
else: # NLLLoss需要在模型输出后加LogSoftmax
model = nn.Sequential(
FlexibleMLP(hidden_sizes=[256, 128]),
nn.LogSoftmax(dim=1)
)
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
acc, t = train_and_evaluate(model, train_loader, test_loader, criterion, optimizer)
accuracies.append(acc)
train_times.append(t)
print(f" Accuracy: {acc:.2f}%, Time: {t:.2f}s\n")
return loss_names, accuracies, train_times
def experiment_optimizer():
"""实验6: 优化器的影响"""
print("="*60)
print("实验6: 优化器的影响")
print("="*60)
optimizer_names = ['SGD', 'Adam', 'RMSprop', 'AdamW']
accuracies = []
train_times = []
train_loader, test_loader = prepare_data(train_size=10000, batch_size=64)
for opt_name in optimizer_names:
print(f"Training with {opt_name} optimizer...")
model = FlexibleMLP(hidden_sizes=[256, 128])
criterion = nn.CrossEntropyLoss()
# 选择优化器
if opt_name == 'SGD':
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
elif opt_name == 'Adam':
optimizer = optim.Adam(model.parameters(), lr=0.001)
elif opt_name == 'RMSprop':
optimizer = optim.RMSprop(model.parameters(), lr=0.001)
elif opt_name == 'AdamW':
optimizer = optim.AdamW(model.parameters(), lr=0.001)
acc, t = train_and_evaluate(model, train_loader, test_loader, criterion, optimizer)
accuracies.append(acc)
train_times.append(t)
print(f" Accuracy: {acc:.2f}%, Time: {t:.2f}s\n")
return optimizer_names, accuracies, train_times
def experiment_batch_size():
"""实验7: Batch Size的影响"""
print("="*60)
print("实验7: Batch Size的影响")
print("="*60)
batch_sizes = [16, 32, 64, 128, 256, 512]
accuracies = []
train_times = []
for bs in batch_sizes:
print(f"Training with batch_size={bs}...")
train_loader, test_loader = prepare_data(train_size=10000, batch_size=bs)
model = FlexibleMLP(hidden_sizes=[256, 128])
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
acc, t = train_and_evaluate(model, train_loader, test_loader, criterion, optimizer)
accuracies.append(acc)
train_times.append(t)
print(f" Accuracy: {acc:.2f}%, Time: {t:.2f}s\n")
return batch_sizes, accuracies, train_times
# ==================== 运行所有实验 ====================
print("🚀 Starting all experiments on MPS device...\n")
start_all = time.time()
# 运行实验
exp1_x, exp1_acc, exp1_time = experiment_sample_size()
exp2_x, exp2_acc, exp2_time = experiment_hidden_neurons()
exp3_x, exp3_acc, exp3_time = experiment_num_layers()
exp4_x, exp4_acc, exp4_time = experiment_activation()
exp5_x, exp5_acc, exp5_time = experiment_loss_function()
exp6_x, exp6_acc, exp6_time = experiment_optimizer()
exp7_x, exp7_acc, exp7_time = experiment_batch_size()
total_time = time.time() - start_all
print(f"\n✅ All experiments completed in {total_time/60:.2f} minutes!\n")
# ==================== 可视化 ====================
fig = plt.figure(figsize=(20, 12))
# 实验1: 样本数量
ax1 = plt.subplot(3, 5, 1)
ax1.plot(exp1_x, exp1_acc, marker='o', linewidth=2, markersize=8, color='#FF6B6B')
ax1.set_xlabel('Training Sample Size', fontsize=10)
ax1.set_ylabel('Test Accuracy (%)', fontsize=10)
ax1.set_title('1. Impact of Sample Size', fontsize=11, fontweight='bold')
ax1.grid(True, alpha=0.3)
ax1.set_xscale('log')
ax2 = plt.subplot(3, 5, 6)
ax2.plot(exp1_x, exp1_time, marker='s', linewidth=2, markersize=8, color='#4ECDC4')
ax2.set_xlabel('Training Sample Size', fontsize=10)
ax2.set_ylabel('Training Time (s)', fontsize=10)
ax2.set_title('Training Time vs Sample Size', fontsize=11)
ax2.grid(True, alpha=0.3)
ax2.set_xscale('log')
# 实验2: 神经元数量
ax3 = plt.subplot(3, 5, 2)
ax3.bar(range(len(exp2_x)), exp2_acc, color='#95E1D3', alpha=0.8)
ax3.set_xlabel('Hidden Layer Config', fontsize=10)
ax3.set_ylabel('Test Accuracy (%)', fontsize=10)
ax3.set_title('2. Impact of Neuron Count', fontsize=11, fontweight='bold')
ax3.set_xticks(range(len(exp2_x)))
ax3.set_xticklabels(exp2_x, rotation=45, ha='right', fontsize=8)
ax3.grid(True, alpha=0.3, axis='y')
ax4 = plt.subplot(3, 5, 7)
ax4.bar(range(len(exp2_x)), exp2_time, color='#F38181', alpha=0.8)
ax4.set_xlabel('Hidden Layer Config', fontsize=10)
ax4.set_ylabel('Training Time (s)', fontsize=10)
ax4.set_title('Training Time vs Neuron Count', fontsize=11)
ax4.set_xticks(range(len(exp2_x)))
ax4.set_xticklabels(exp2_x, rotation=45, ha='right', fontsize=8)
ax4.grid(True, alpha=0.3, axis='y')
# 实验3: 层数
ax5 = plt.subplot(3, 5, 3)
ax5.plot(range(1, 6), exp3_acc, marker='D', linewidth=2, markersize=8, color='#A29BFE')
ax5.set_xlabel('Number of Hidden Layers', fontsize=10)
ax5.set_ylabel('Test Accuracy (%)', fontsize=10)
ax5.set_title('3. Impact of Layer Depth', fontsize=11, fontweight='bold')
ax5.set_xticks(range(1, 6))
ax5.set_xticklabels(exp3_x, fontsize=8)
ax5.grid(True, alpha=0.3)
ax6 = plt.subplot(3, 5, 8)
ax6.plot(range(1, 6), exp3_time, marker='D', linewidth=2, markersize=8, color='#FDCB6E')
ax6.set_xlabel('Number of Hidden Layers', fontsize=10)
ax6.set_ylabel('Training Time (s)', fontsize=10)
ax6.set_title('Training Time vs Layer Depth', fontsize=11)
ax6.set_xticks(range(1, 6))
ax6.set_xticklabels(exp3_x, fontsize=8)
ax6.grid(True, alpha=0.3)
# 实验4: 激活函数
ax7 = plt.subplot(3, 5, 4)
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#FFA07A']
ax7.bar(range(len(exp4_x)), exp4_acc, color=colors, alpha=0.8)
ax7.set_xlabel('Activation Function', fontsize=10)
ax7.set_ylabel('Test Accuracy (%)', fontsize=10)
ax7.set_title('4. Impact of Activation', fontsize=11, fontweight='bold')
ax7.set_xticks(range(len(exp4_x)))
ax7.set_xticklabels(exp4_x, fontsize=9)
ax7.grid(True, alpha=0.3, axis='y')
ax8 = plt.subplot(3, 5, 9)
ax8.bar(range(len(exp4_x)), exp4_time, color=colors, alpha=0.8)
ax8.set_xlabel('Activation Function', fontsize=10)
ax8.set_ylabel('Training Time (s)', fontsize=10)
ax8.set_title('Training Time vs Activation', fontsize=11)
ax8.set_xticks(range(len(exp4_x)))
ax8.set_xticklabels(exp4_x, fontsize=9)
ax8.grid(True, alpha=0.3, axis='y')
# 实验5: 损失函数
ax9 = plt.subplot(3, 5, 5)
ax9.bar(range(len(exp5_x)), exp5_acc, color=['#E17055', '#74B9FF'], alpha=0.8)
ax9.set_xlabel('Loss Function', fontsize=10)
ax9.set_ylabel('Test Accuracy (%)', fontsize=10)
ax9.set_title('5. Impact of Loss Function', fontsize=11, fontweight='bold')
ax9.set_xticks(range(len(exp5_x)))
ax9.set_xticklabels(exp5_x, fontsize=9)
ax9.grid(True, alpha=0.3, axis='y')
ax10 = plt.subplot(3, 5, 10)
ax10.bar(range(len(exp5_x)), exp5_time, color=['#E17055', '#74B9FF'], alpha=0.8)
ax10.set_xlabel('Loss Function', fontsize=10)
ax10.set_ylabel('Training Time (s)', fontsize=10)
ax10.set_title('Training Time vs Loss', fontsize=11)
ax10.set_xticks(range(len(exp5_x)))
ax10.set_xticklabels(exp5_x, fontsize=9)
ax10.grid(True, alpha=0.3, axis='y')
# 实验6: 优化器
ax11 = plt.subplot(3, 5, 11)
colors2 = ['#6C5CE7', '#00B894', '#FDCB6E', '#E17055']
ax11.bar(range(len(exp6_x)), exp6_acc, color=colors2, alpha=0.8)
ax11.set_xlabel('Optimizer', fontsize=10)
ax11.set_ylabel('Test Accuracy (%)', fontsize=10)
ax11.set_title('6. Impact of Optimizer', fontsize=11, fontweight='bold')
ax11.set_xticks(range(len(exp6_x)))
ax11.set_xticklabels(exp6_x, fontsize=9)
ax11.grid(True, alpha=0.3, axis='y')
ax12 = plt.subplot(3, 5, 12)
ax12.bar(range(len(exp6_x)), exp6_time, color=colors2, alpha=0.8)
ax12.set_xlabel('Optimizer', fontsize=10)
ax12.set_ylabel('Training Time (s)', fontsize=10)
ax12.set_title('Training Time vs Optimizer', fontsize=11)
ax12.set_xticks(range(len(exp6_x)))
ax12.set_xticklabels(exp6_x, fontsize=9)
ax12.grid(True, alpha=0.3, axis='y')
# 实验7: Batch Size
ax13 = plt.subplot(3, 5, 13)
ax13.plot(exp7_x, exp7_acc, marker='o', linewidth=2, markersize=8, color='#74B9FF')
ax13.set_xlabel('Batch Size', fontsize=10)
ax13.set_ylabel('Test Accuracy (%)', fontsize=10)
ax13.set_title('7. Impact of Batch Size', fontsize=11, fontweight='bold')
ax13.set_xscale('log', base=2)
ax13.grid(True, alpha=0.3)
ax14 = plt.subplot(3, 5, 14)
ax14.plot(exp7_x, exp7_time, marker='s', linewidth=2, markersize=8, color='#A29BFE')
ax14.set_xlabel('Batch Size', fontsize=10)
ax14.set_ylabel('Training Time (s)', fontsize=10)
ax14.set_title('Training Time vs Batch Size', fontsize=11)
ax14.set_xscale('log', base=2)
ax14.grid(True, alpha=0.3)
# 添加总体标题
fig.suptitle('MLP Hyperparameter Experiments on MNIST (MPS Accelerated)',
fontsize=16, fontweight='bold', y=0.995)
plt.tight_layout()
plt.savefig('hyperparameter_experiments_mps.png', dpi=300, bbox_inches='tight')
print("="*60)
print("📊 Plot saved as 'hyperparameter_experiments_mps.png'")
print("="*60)
plt.show()
# ==================== 输出总结 ====================
print("\n" + "="*60)
print("📈 实验总结 (MPS加速)")
print("="*60)
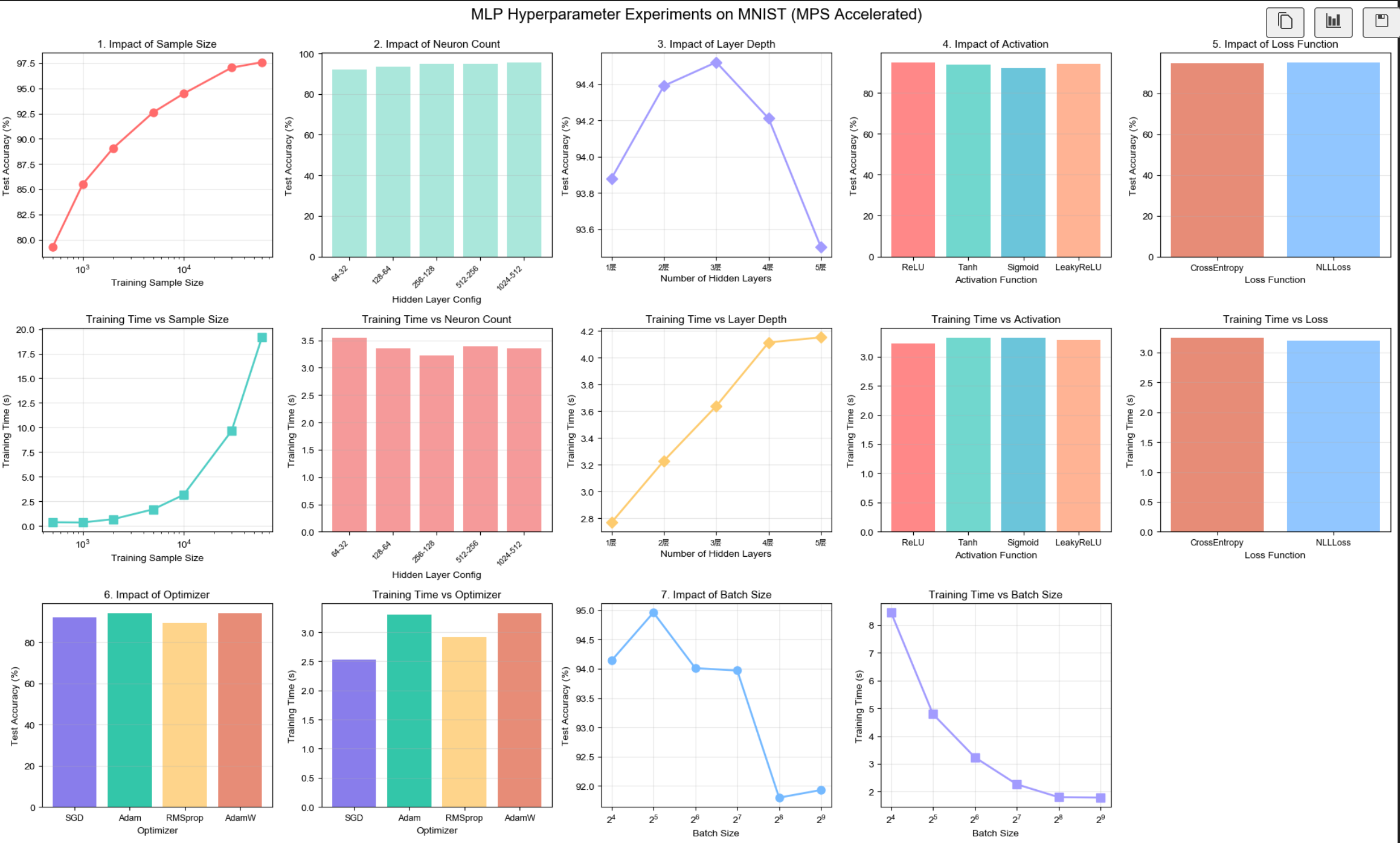
print("\n1. 样本数量影响:")
print(f" 最佳准确率: {max(exp1_acc):.2f}% (样本数: {exp1_x[exp1_acc.index(max(exp1_acc))]})")
print(f" 最快训练: {min(exp1_time):.2f}s (样本数: {exp1_x[exp1_time.index(min(exp1_time))]})")
print(f" 💡 结论: 样本量越大准确率越高,但边际效应递减")
print("\n2. 神经元数量影响:")
print(f" 最佳准确率: {max(exp2_acc):.2f}% (配置: {exp2_x[exp2_acc.index(max(exp2_acc))]})")
print(f" 最快训练: {min(exp2_time):.2f}s (配置: {exp2_x[exp2_time.index(min(exp2_time))]})")
print(f" 💡 结论: 256-128是平衡点,更多神经元提升有限但耗时增加")
print("\n3. 层数影响:")
print(f" 最佳准确率: {max(exp3_acc):.2f}% (层数: {exp3_x[exp3_acc.index(max(exp3_acc))]})")
print(f" 最快训练: {min(exp3_time):.2f}s (层数: {exp3_x[exp3_time.index(min(exp3_time))]})")
print(f" 💡 结论: 2-3层最佳,过深可能梯度消失且训练慢")
print("\n4. 激活函数影响:")
print(f" 最佳准确率: {max(exp4_acc):.2f}% (函数: {exp4_x[exp4_acc.index(max(exp4_acc))]})")
print(f" 💡 结论: ReLU系列表现最好,Sigmoid易梯度消失")
print("\n5. 损失函数影响:")
print(f" 最佳准确率: {max(exp5_acc):.2f}% (函数: {exp5_x[exp5_acc.index(max(exp5_acc))]})")
print(f" 💡 结论: CrossEntropy和NLLLoss本质相同,性能接近")
print("\n6. 优化器影响:")
print(f" 最佳准确率: {max(exp6_acc):.2f}% (优化器: {exp6_x[exp6_acc.index(max(exp6_acc))]})")
print(f" 💡 结论: Adam/AdamW自适应学习率,收敛快且稳定")
print("\n7. Batch Size影响:")
print(f" 最佳准确率: {max(exp7_acc):.2f}% (batch_size: {exp7_x[exp7_acc.index(max(exp7_acc))]})")
print(f" 最快训练: {min(exp7_time):.2f}s (batch_size: {exp7_x[exp7_time.index(min(exp7_time))]})")
print(f" 💡 结论: 较大batch训练快但可能泛化能力稍弱")
print("\n" + "="*60)
print(f"⏱️ 总运行时间: {total_time/60:.2f} 分钟")
print(f"🚀 MPS加速效果显著!")
print("="*60)
Using device: mps
MPS available: True
MPS built: True
🚀 Starting all experiments on MPS device...
============================================================
实验1: 训练样本数量的影响
============================================================
Training with 500 samples...
Accuracy: 79.24%, Time: 0.37s
Training with 1000 samples...
Accuracy: 85.51%, Time: 0.35s
Training with 2000 samples...
Accuracy: 89.07%, Time: 0.68s
Training with 5000 samples...
Accuracy: 92.62%, Time: 1.68s
Training with 10000 samples...
Accuracy: 94.47%, Time: 3.15s
Training with 30000 samples...
Accuracy: 97.05%, Time: 9.65s
Training with 60000 samples...
Accuracy: 97.59%, Time: 19.16s
============================================================
实验2: 隐藏层神经元数量的影响 (保持2层隐藏层)
============================================================
Training with hidden layers: 64-32...
Accuracy: 92.04%, Time: 3.55s
Training with hidden layers: 128-64...
Accuracy: 93.46%, Time: 3.36s
Training with hidden layers: 256-128...
Accuracy: 94.72%, Time: 3.22s
Training with hidden layers: 512-256...
Accuracy: 94.82%, Time: 3.39s
Training with hidden layers: 1024-512...
Accuracy: 95.44%, Time: 3.36s
============================================================
实验3: 隐藏层数量的影响
============================================================
Training with 1层...
Accuracy: 93.88%, Time: 2.77s
Training with 2层...
Accuracy: 94.39%, Time: 3.23s
Training with 3层...
Accuracy: 94.52%, Time: 3.64s
Training with 4层...
Accuracy: 94.21%, Time: 4.11s
Training with 5层...
Accuracy: 93.50%, Time: 4.15s
============================================================
实验4: 激活函数的影响
============================================================
Training with ReLU activation...
Accuracy: 94.71%, Time: 3.23s
Training with Tanh activation...
Accuracy: 93.70%, Time: 3.32s
Training with Sigmoid activation...
Accuracy: 91.92%, Time: 3.32s
Training with LeakyReLU activation...
Accuracy: 94.27%, Time: 3.29s
============================================================
实验5: 损失函数的影响
============================================================
Training with CrossEntropy...
Accuracy: 94.61%, Time: 3.25s
Training with NLLLoss...
Accuracy: 94.92%, Time: 3.20s
============================================================
实验6: 优化器的影响
============================================================
Training with SGD optimizer...
Accuracy: 92.09%, Time: 2.53s
Training with Adam optimizer...
Accuracy: 94.21%, Time: 3.30s
Training with RMSprop optimizer...
Accuracy: 89.45%, Time: 2.91s
Training with AdamW optimizer...
Accuracy: 94.27%, Time: 3.33s
============================================================
实验7: Batch Size的影响
============================================================
Training with batch_size=16...
Accuracy: 94.14%, Time: 8.45s
Training with batch_size=32...
Accuracy: 94.96%, Time: 4.79s
Training with batch_size=64...
Accuracy: 94.01%, Time: 3.23s
Training with batch_size=128...
Accuracy: 93.97%, Time: 2.26s
Training with batch_size=256...
Accuracy: 91.80%, Time: 1.80s
Training with batch_size=512...
Accuracy: 91.93%, Time: 1.78s
✅ All experiments completed in 2.21 minutes!
============================================================
📊 Plot saved as 'hyperparameter_experiments_mps.png'
============================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号