InnoDB索引模型
索引: 数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询、更新数据库表中数据。
MySQL中有三大索引:B+树索引,Hash索引,全文索引
InnoDB不支持Hash索引
索引的原理就是二分查找:
最基本的想到的数据结构就是二叉树
- 二叉查找树: 如果插入的数字恰好是有序递增的,那么就是一颗斜树,就和数组一样了
- 平衡二叉树: 左右子树深度差绝对值不能超过 1
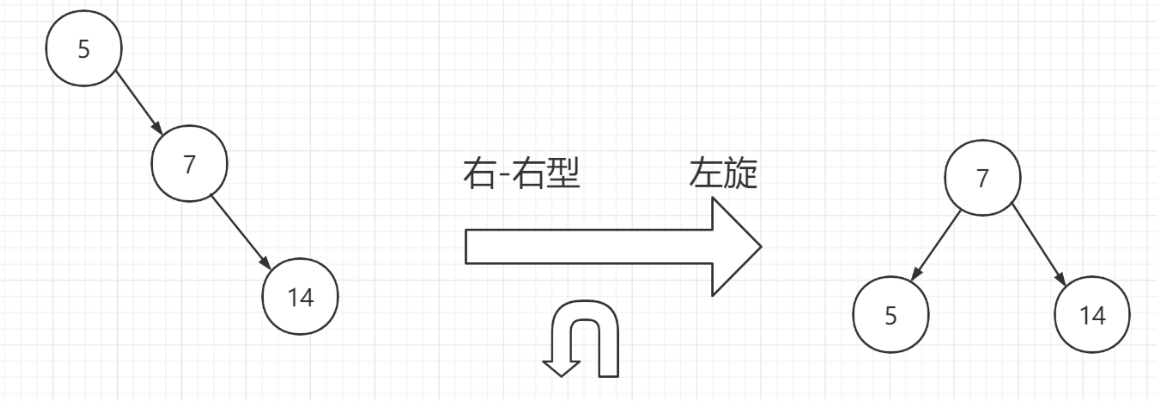
平衡二叉树中,一个节点的大小是一个固定的单位
索引中存储的位置:
- 索引的键值,比如我们在 id 上面创建了一个索引,我在用 where id =1 的条件查询的时候就会找到索引里面的 id 的这个键值
- 数据的磁盘地址,索引的作用就是去查找数据的存放的地址
- 左右子节点的指针
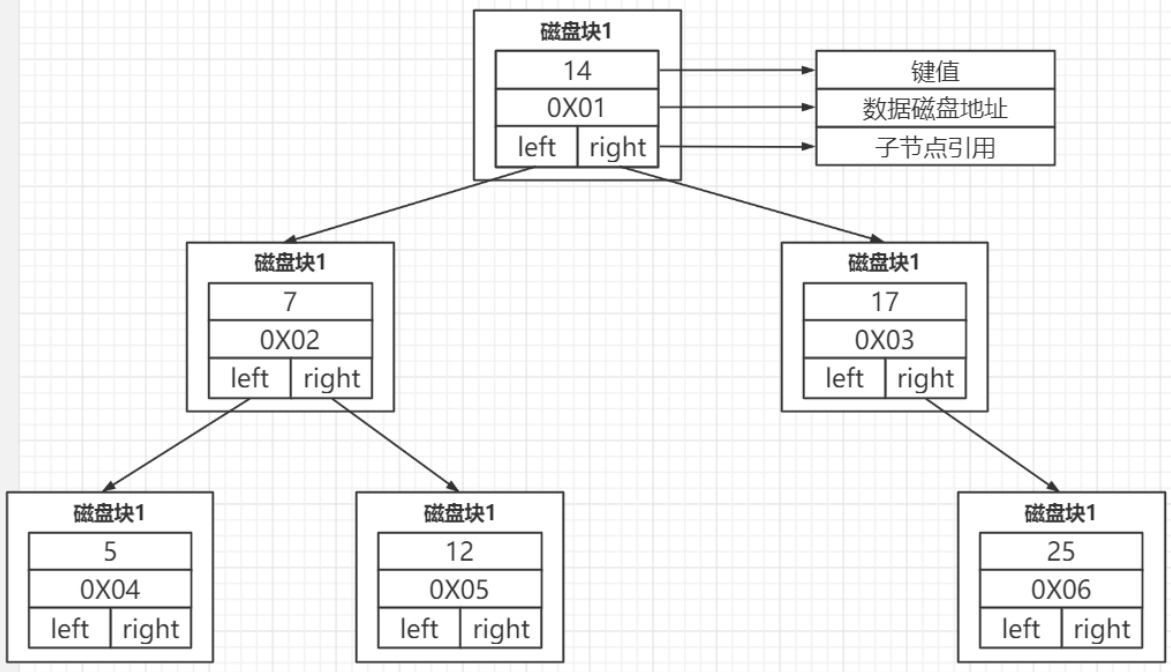
缺点:
InnoDB 操作磁盘的最小的单位是一页(或者叫一个磁盘块),大小是 16K(16384字节),那么一个树的节点就是16K的大小。如果一个节点只存一个键值+数据+引用,占用的可能只是几十字节,但是访问树的一个节点就要发生一次IO,就是发生一次IO的访问造成了大量的浪费
- 多路平衡查找树:
特点:分叉数(路数)永远比关键字数多 1。比如下面的这棵树,每个节点存储两个关键字,那么就会有三个指针指向三个子节点
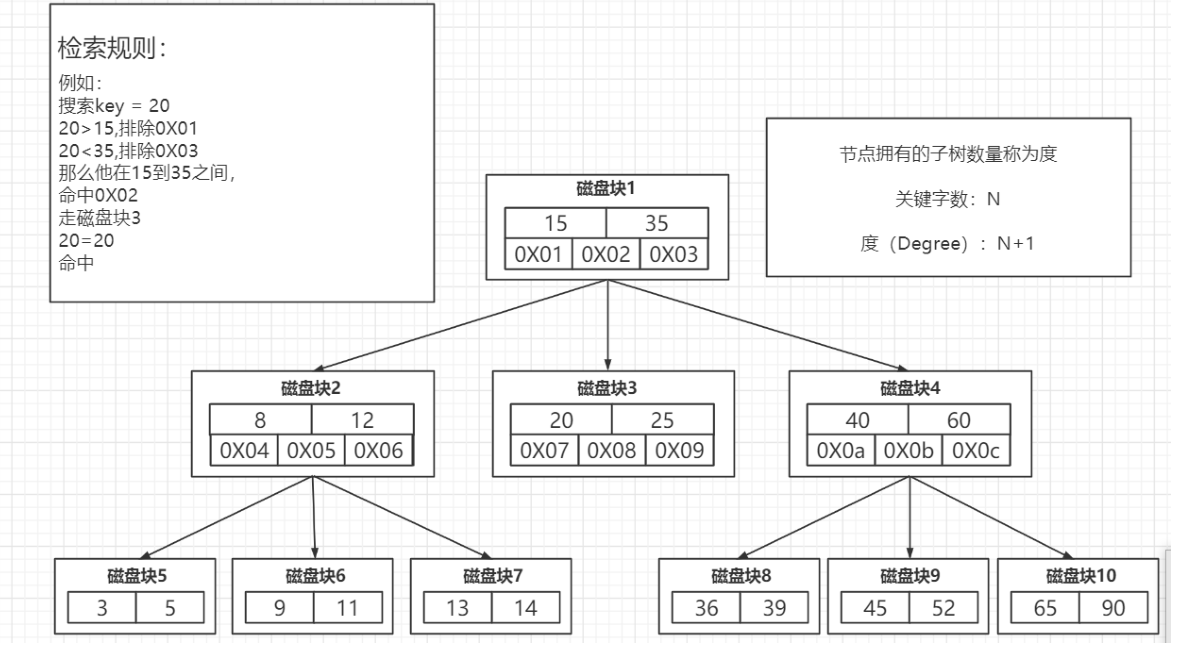
如何保持的平衡?
比如 Max Degree(路数)是 3 的时候,我们插入数据 1、2、3,在插入 3 的时候,本来应该在第一个磁盘块,但是如果一个节点有三个关键字的时候,意味着有 4 个指针, 子节点会变成 4 路,所以这个时候必须进行分裂(其实就是 B+Tree)。把中间的数据 2提上去,把 1 和 3 变成 2 的子节点
如果删除节点,会有相反的合并的操作

在更新索引的时候会有大量索引的结构的调整,所以:
不要在频繁更新的列上建索引,不要更新主键
节点的分裂和合并,其实就是 InnoDB 页(page)的分裂和合并。
- B+树:

MySQL 中的 B+Tree 有两个特点:
- 它的关键字的数量是跟路数相等的
- B+Tree根节点和枝节点中都不会存储数据,只有叶子结点才存储数据
搜索到的关键字不会直接返回,会到最后一层的叶子节点拿数据 - B+Tree的每个叶子结点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,形成了一个有序链表的结构
InnoDB中的B+Tree这种特点带来的优势: - 扫库,扫表的能力更强,如果我们要对表进行全表扫描,只需要遍历叶子节点就可以了,不需要遍历整颗B+树拿到数据
- B+Tree的磁盘读写能力相对于B tree来说更强:根节点和枝节点不保存数据区,所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多
- 排序能力更强:因为叶子节点上有下一个数据区的指针,数据形成了链表
- 效率更加稳定: B+Tree永远是在叶子节点拿到数据,所以IO次数是稳定的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号