
[特征工程01] 什么是归一化?归一化/标准化有什么用?pandas与归一化的简单实践
引用
特征工程中的「归一化」有什么作用? - 微调的回答 - 知乎
https://www.zhihu.com/question/20455227/answer/370658612
特征工程中的「归一化」有什么作用? - 忆臻的回答 - 知乎
https://www.zhihu.com/question/20455227/answer/197897298
对一维数据的缩放有如下定义:
- 归一化(normalization): (Xi - Xmin) / (Xmax - Xmin), 由于Xi<=Xmax, 将所有数据归一化到区间[0,1]以内, 并且线性缩放后相对大小的数值倍数不变
- 标准化(standardization): (Xi - mean) / std
(Xi 表示单个样本, Xmax表示最大值, Xmin表示最小值)
归一化和标准化本质上都是一种线性变换 都是整体向下压缩再向左或者向右平移
通过变换公式形式,易得

简单的归一化和标准化的sklearn标准库
from sklearn import preprocessing
from scipy.stats import rankdata
x = [[1], [2], [13], [4], [555], [17], [9]]
stand = preprocessing.StandardScaler().fit_transform(x)
norm = preprocessing.MinMaxScaler().fit_transform(x)
print('stand: ', stand)
print('norm: ', norm)
print('原始顺序: ', rankdata(x))
print('标准化顺序: ', rankdata(stand))
print('归一化顺序: ', rankdata(norm))
输出
stand: [[-0.44287754] [-0.43765845][-0.38024839] [-0.42722026] [ 2.44850143] [-0.35937201] [-0.40112478] ]
norm: [[0. ] [0.00180505] [0.02166065] [0.00541516] [1. ] [0.02888087] [0.01444043] ]
原始顺序: [1. 2. 5. 3. 7. 6. 4.]
标准化顺序: [1. 2. 5. 3. 7. 6. 4.]
归一化顺序: [1. 2. 5. 3. 7. 6. 4.]
区别
标准化: 和整体的样本分布有很大的关系,标准化的缩放是更加“弹性”和“动态”的, 通过整体的方差得到体现,输出的范围更广 [ (Xi - mean) / std ]
归一化: 由极值(有且仅由最大值和最小值决定)决定,统一拍扁到 0-1 的区间 [(Xi - Xmin) / (Xmax - Xmin) == Xi / (Xmax - Xmin) - Xmin / (Xmax - Xmin)]
什么时候用归一化?什么时候用标准化?
- 如果对输出结果范围有要求,用归一化
- 如果数据十分稳定, 不存在极端的最大最小值, 使用归一化
- 如果数据存在任何极端的异常值或者较多的噪音, 用标准化, 可以如果对输出结果范围有要求**,用归一化避免异常值或者极端值的影响 **
归一化的好处 [Datawhale]
- 对特征做归一化,去除相关性高的特征
- 归一化目的是让训练过程更好更快的收敛,避免特征大吃小的问题
- 去除相关性是增加模型的可解释性,加快预测过程。
- 数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。 (如下图)
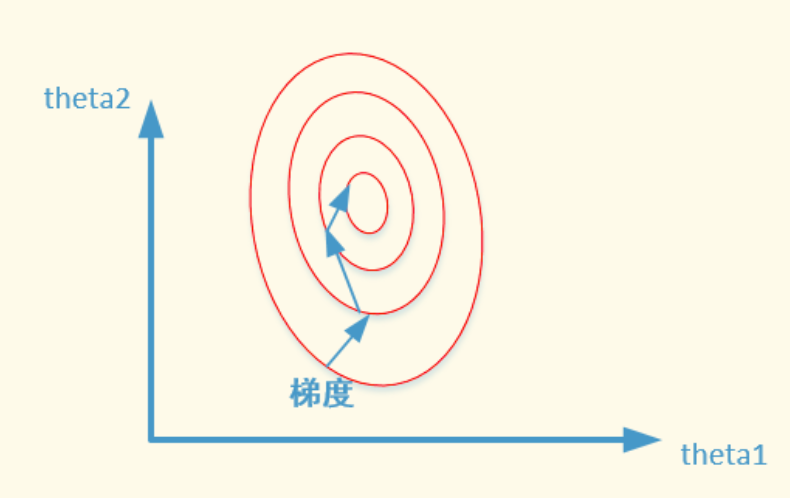
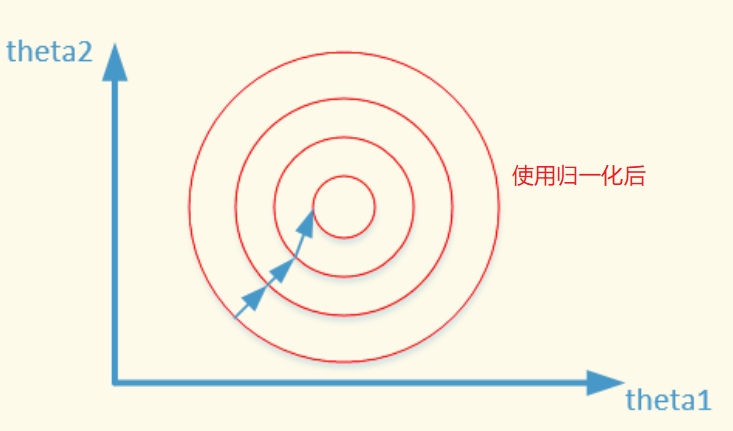
个人实践 [ 【第17期Datawhale | 零基础入门金融风控-贷款违约预测】的数据做比较]
由于盲目使用归一化, 把n0-n14的匿名列全部归一化后, 达成负优化.
去掉后, 分数有所提高.
你不逼自己一把,你永远都不知道自己有多优秀!只有经历了一些事,你才会懂得好好珍惜眼前的时光!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号