
云原生第六周--k8s组件详解(下)(velero, HPA控制器,RBAC鉴权,资源限制,亲和反亲和,污点和容忍)
一 Velero结合minio实现kubernetes etcd数据备份与恢复
Velero简介:
Velero 是vmware开源的一个云原生的灾难恢复和迁移工具,它本身也是开源的,采用Go语言编写,可以安全的备份、恢复和迁移Kubernetes集群资源数据
Velero 支持标准的K8S集群,既可以是私有云平台也可以是公有云,除了灾备之外它还能做资源移转,支持把容器应用从一个集群迁移到另一个集群。
Velero 的工作方式就是把kubernetes中的数据备份到对象存储以实现高可用和持久化,默认的备份保存时间为720小时,并在需要的时候进行下载和恢复。
Velero与etcd快照备份的区别:
- etcd 快照是全局完成备份(类似于MySQL全部备份),即使需要恢复一个资源对象(类似于只恢复MySQL的一个库),但是也需要做全局恢复到备份的状态(类似于MySQL的全库恢复),即会影响其它namespace中pod运行服务(类似于会影响MySQL其它数据库的数据)。
- Velero可以有针对性的备份,比如按照namespace单独备份、只备份单独的资源对象等,在恢复的时候可以根据备份只恢复单独的namespace或资源对象,而不影响其它namespace中pod运行服务。
- velero支持ceph、oss等对象存储,etcd 快照是一个为本地文件。
- velero支持任务计划实现周期备份,但etcd 快照也可以基于cronjob实现。
- velero支持对AWS EBS创建快照及还原。
velero整体架构:
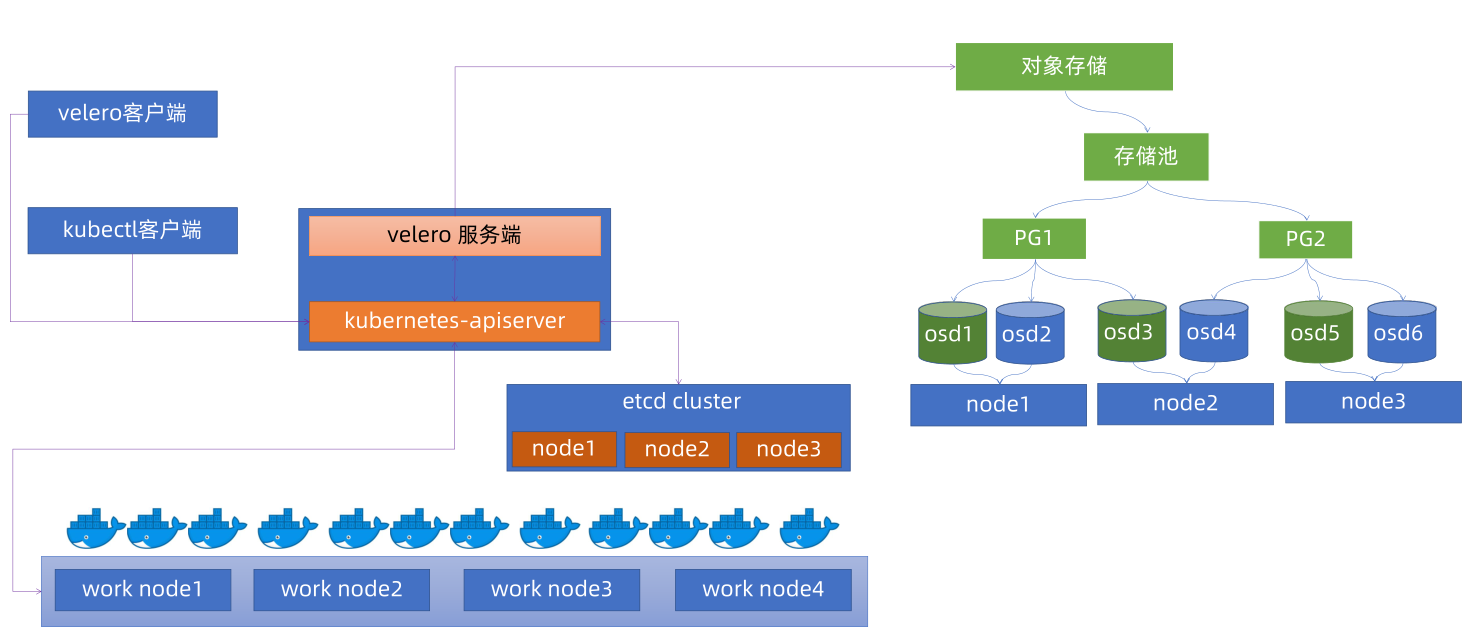
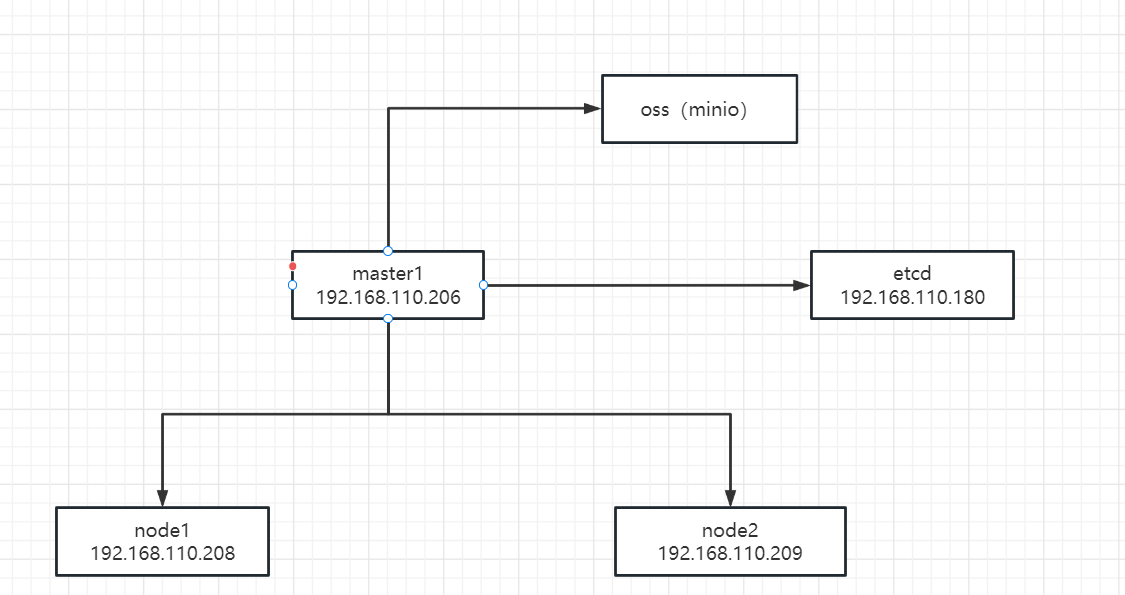
部署环境
部署minio存储
创建数据目录:
nerdctl pull minio/minio:RELEASE.2022-04-12T06-55-35Z
mkdir -p /data/minio
创建minio容器,如果不指定,则默认用户名与密码为 minioadmin/minioadmin,可以通过环境变量自定义
nerdctl run --name minio \
-p 9000:9000 \
-p 9999:9999 \
-d --restart=always \
-e "MINIO_ROOT_USER=admin" \
-e "MINIO_ROOT_PASSWORD=12345678" \
-v /data/minio/data:/data \
minio/minio:RELEASE.2022-04-12T06-55-35Z server /data \
--console-address '0.0.0.0:9999'
部署velero:
root@192:/usr/local/src/velero# wget https://github.com/vmware-tanzu/velero/releases/download/v1.11.0/velero-v1.11.0-linux-amd64.tar.gz
root@192:/usr/local/src/velero# tar -zxvf velero-v1.11.0-linux-amd64.tar
root@192:/usr/local/src/velero# cp velero-v1.11.0-linux-amd64/velero /usr/local/bin/
root@192:/usr/local/src/velero# velero --help
配置velero认证环境:
#工作目录:
root@k8s-master1:~# mkdir /data/velero -p
root@k8s-master1:~# cd /data/velero/data
root@k8s-master1:/data/velero#
#访问minio的认证文件:
root@k8s-master1:/data/velero# vim velero-auth.txt
[default]
aws_access_key_id = admin
aws_secret_access_key = 12345678
#准备user-csr文件:
root@k8s-master1:/data/velero# vim awsuser-csr.json
{
"CN": "awsuser",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
之后准备证书签发
#准备证书签发环境:
root@k8s-master1:/data/velero# apt install golang-cfssl
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.1/cfssl_1.6.1_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.1/cfssljson_1.6.1_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.1/cfssl-certinfo_1.6.1_linux_amd64
root@k8s-master1:/data/velero# mv cfssl-certinfo_1.6.1_linux_amd64 cfssl-certinfo
root@k8s-master1:/data/velero# mv cfssl_1.6.1_linux_amd64 cfssl
root@k8s-master1:/data/velero# mv cfssljson_1.6.1_linux_amd64 cfssljson
root@k8s-master1:/data/velero# cp cfssl-certinfo cfssl cfssljson /usr/local/bin/
root@k8s-master1:/data/velero# chmod a+x /usr/local/bin/cfssl*
#执行证书签发命令:
>= 1.24.x:
root@k8s-deploy:~# scp cp /etc/kubeasz/clusters/k8s-master1/ssl/ca-config.json 192.168.110.206:/data/velero
root@k8s-master1:/data/velero# /usr/local/bin/cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem -ca-key=/etc/kubernetes/ssl/ca-key.pem -config=./ca-config.json -profile=kubernetes ./awsuser-csr.json | cfssljson -bare awsuser
######
1.23 <=
root@k8s-master1:/data/velero# /usr/local/bin/cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem -ca-key=/etc/kubernetes/ssl/ca-key.pem -config=/etc/kubeasz/clusters/k8s-cluster1/ssl/ca-config.json -profile=kubernetes ./awsuser-csr.json | cfssljson -bare awsuser

#分发证书到api-server证书路径:
root@k8s-master1:/data/velero# cp awsuser-key.pem /etc/kubernetes/ssl/
root@k8s-master1:/data/velero# cp awsuser.pem /etc/kubernetes/ssl/
#生成集群认证config文件:
# export KUBE_APISERVER="https://192.168.110.206:6443"
# kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=./awsuser.kubeconfig
#设置客户端证书认证:
# kubectl config set-credentials awsuser \
--client-certificate=/etc/kubernetes/ssl/awsuser.pem \
--client-key=/etc/kubernetes/ssl/awsuser-key.pem \
--embed-certs=true \
--kubeconfig=./awsuser.kubeconfig
#设置上下文参数:
# kubectl config set-context kubernetes \
--cluster=kubernetes \
--user=awsuser \
--namespace=velero-system \
--kubeconfig=./awsuser.kubeconfig
#设置默认上下文:
# kubectl config use-context kubernetes --kubeconfig=awsuser.kubeconfig
#k8s集群中创建awsuser账户:
# kubectl create clusterrolebinding awsuser --clusterrole=cluster-admin --user=awsuser
#创建namespace:
# kubectl create ns velero-system
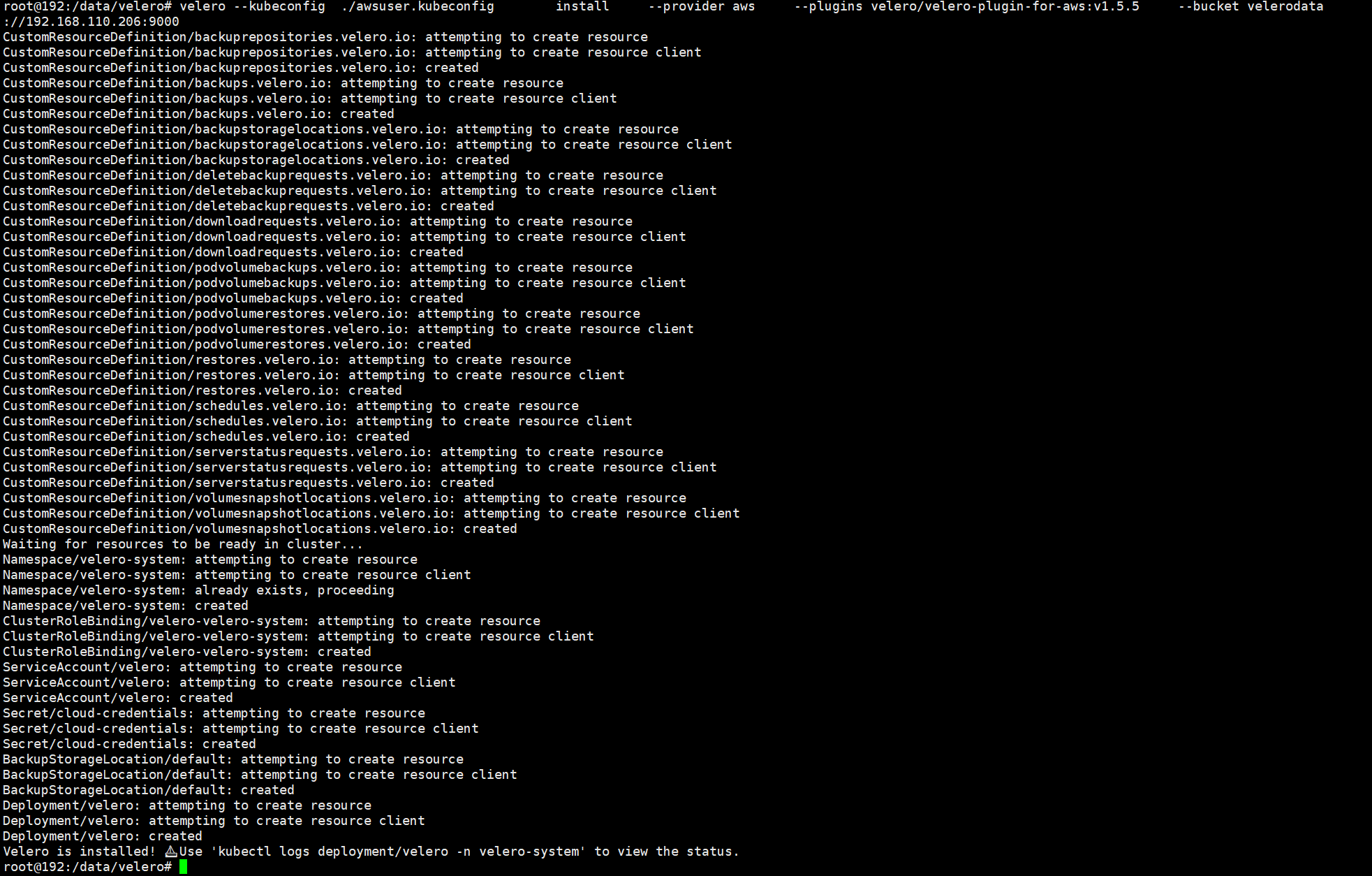
#安装velero
root@192:/data/minio# velero --kubeconfig ./awsuser.kubeconfig \
install \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.5.5 \
--bucket velerodata \
--secret-file ./velero-auth.txt \
--use-volume-snapshots=false \
--namespace velero-system \
--backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://192.168.110.206:9000
查看velero的pod

利用velero对 default namespace进行备份
root@192:/data/velero# pwd
/data/velero
root@192:/data/velero# DATE=`date +%Y%m%d%H%M%S`
root@192:/data/velero# velero backup create default-backup-${DATE} \
--include-cluster-resources=true \
--include-namespaces default \
--kubeconfig=./awsuser.kubeconfig \
--namespace velero-system
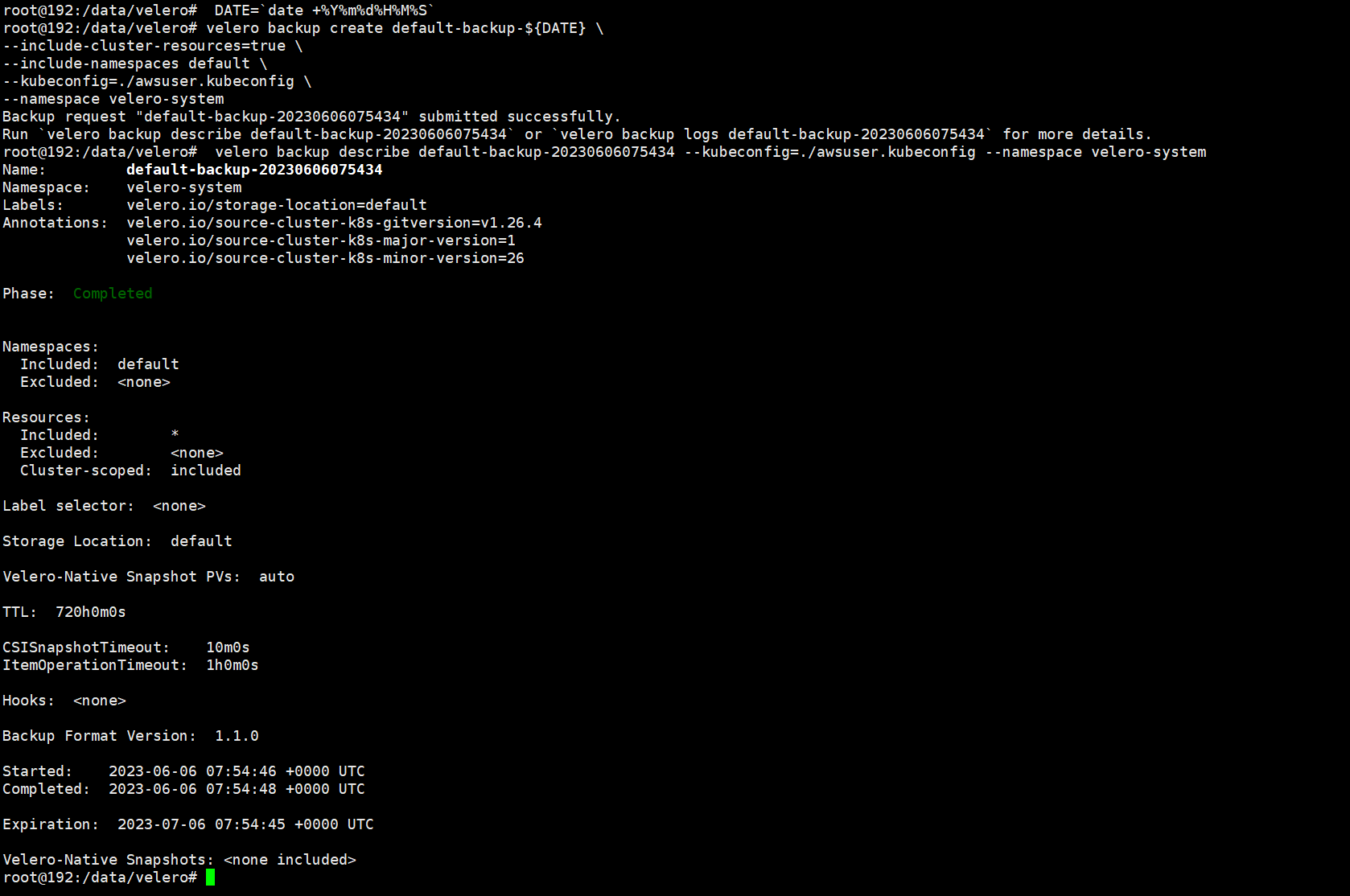
Backup request "default-backup-20230606075434" submitted successfully.
Run `velero backup describe default-backup-20230606075434` or `velero backup logs default-backup-20230606075434` for more details.
root@192:/data/velero# velero backup describe default-backup-20230606075434 --kubeconfig=./awsuser.kubeconfig --namespace velero-system
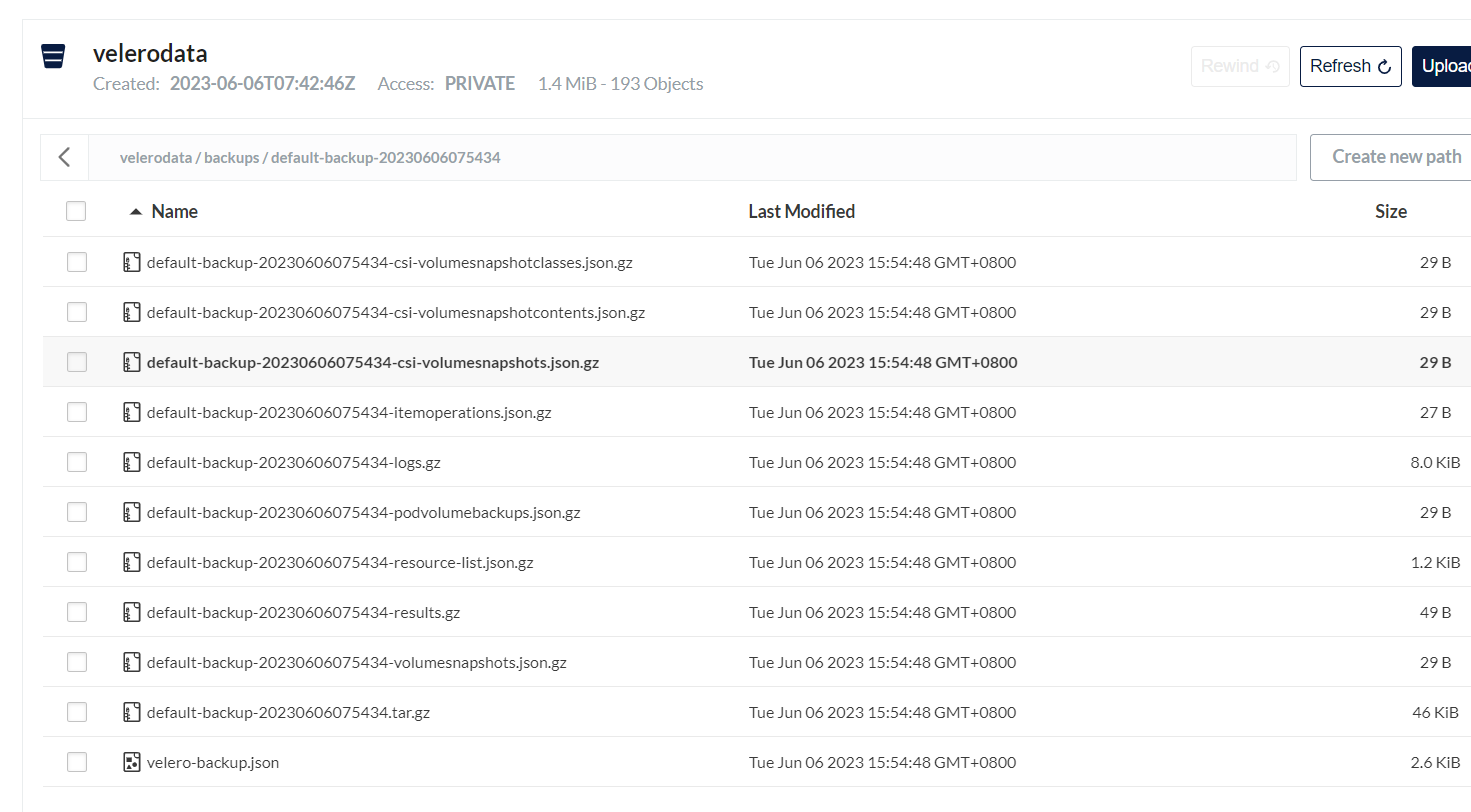
备份指定资源对象:
备份指定namespace中的pod或特定资源:
kubectl run net-test1 --image=centos:7.9.2009 sleep 10000000000 -n myserver pod/net-test1 created
root@k8s-master1:/data/velero# kubectl get pod -n myserver
NAME READY STATUS RESTARTS AGE
myserver-nginx-deployment-76f7df66c8-dq8k8 1/1 Running 0 19m
myserver-tomcat-app1-deployment-6bb596979f-gc2jw 1/1 Running 0 10m
net-test1 1/1 Running 0 24s
root@k8s-master1:/data/velero# kubectl get deployments -n myserver
NAME READY UP-TO-DATE AVAILABLE AGE
myserver-nginx-deployment 1/1 1 1 15m
myserver-tomcat-app1-deployment 1/1 1 1 6m12s
root@k8s-master1:/data/velero# velero backup create pod-backup-202207222335 --include-cluster-resources=true --ordered-resources'pods=myserver/net-test1,defafut/net-test1' --namespace velero-system --include-namespaces=myserver,defafut
注意:
--ordered-resources指的是一个备份顺序,不是挑某单个资源去备份。
velero backup create
批量备份所有namespace:
root@k8s-master1:~# cat /data/velero/ns-back.sh
#!/bin/bash
NS_NAME=`kubectl get ns | awk '{if (NR>2){print}}' | awk '{print $1}'`
DATE=`date +%Y%m%d%H%M%S`
cd /data/velero/
for i in $NS_NAME;do
velero backup create ${i}-ns-backup-${DATE} \
--include-cluster-resources=true \
--include-namespaces ${i} \
--kubeconfig=/root/.kube/config \
--namespace velero-system
done
root@k8s-master1:~# bash /data/velero/ns-back.sh

HPA控制器
Pod 水平自动扩缩
在 Kubernetes 中,HorizontalPodAutoscaler 自动更新工作负载资源 (例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与 “垂直(Vertical)” 扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且 Pod 的数量高于配置的最小值, HorizontalPodAutoscaler 会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减。
水平 Pod 自动扩缩不适用于无法扩缩的对象(例如:DaemonSet。)
HorizontalPodAutoscaler 被实现为 Kubernetes API 资源和控制器。
资源决定了控制器的行为。 在 Kubernetes 控制平面内运行的水平 Pod 自动扩缩控制器会定期调整其目标(例如:Deployment)的所需规模,以匹配观察到的指标, 例如,平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标。
pod伸缩简介:
- 根据当前pod的负载,动态调整 pod副本数量,业务高峰期自动扩容pod的副本数以尽快响应pod的请求。
- 在业务低峰期对pod进行缩容,实现降本增效的目的。
- 公有云支持node级别的弹性伸缩。
手动调整pod副本数:
scale命令 调整deployment控制器副本
root@k8s-master1:~# kubectl get pod -n myserver #当前pod副本数
NAME READY STATUS RESTARTS AGE
myserver-myapp-deployment-name-fb44b4447-pwwxq 1/1 Running 1 (5h15m ago) 11d
myserver-myapp-frontend-deployment-855c89f977-th64z 1/1 Running 2 (5h15m ago) 11d
myserver-tomcat-app1-deployment-86bc8cbcb5-k9vc7 1/1 Running 7 (5h15m ago) 18d
root@k8s-master1:~# kubectl scale deployment myserver-tomcat-app1-deployment --replicas=2 -n myserver
deployment.apps/myserver-tomcat-app1-deployment scaled
验证pod副本数:
root@k8s-master1:~# kubectl get pod -n myserver
NAME READY STATUS RESTARTS AGES
myserver-myapp-deployment-name-fb44b4447-pwwxq 1/1 Running 1 (5h53m ago) 11d
myserver-myapp-frontend-deployment-855c89f977-th64z 1/1 Running 2 (5h53m ago) 11d
myserver-tomcat-app1-deployment-86bc8cbcb5-gdczd 1/1 Running 0 42s
myserver-tomcat-app1-deployment-86bc8cbcb5-k9vc7 1/1 Running 7 (5h53m ago) 18d
动态伸缩控制器类型:
水平pod自动缩放器(HPA):
- 基于pod 资源利用率横向调整pod副本数量。
垂直pod自动缩放器(VPA):
- 基于pod资源利用率,调整对单个pod的最大资源限制,不能与HPA同时使用。
集群伸缩(Cluster Autoscaler,CA)
- 基于集群中node 资源使用情况,动态伸缩node节点,从而保证有CPU和内存资源用于创建pod。
HPA控制器参数:
--horizontal-pod-autoscaler-sync-period # 默认每隔 15s( 可以通过 –horizontal-pod-autoscaler-sync-period 修改) ) 查询 metrics 的资源使用情况 。
--horizontal-pod-autoscaler-downscale-stabilization # 缩容间隔周期,默认5分钟。
--horizontal-pod-autoscaler-sync-period #HPA 控制器同步 pod 副本数的间隔周期
--horizontal-pod-autoscaler-cpu-initialization-period # 初始化延迟时间, 在此时间内 pod 的 CPU 资源指标将不会 生效 ,默认为 5 分钟 。
--horizontal-pod-autoscaler-initial-readiness-delay # 用于设置 pod 准备时间, 在此时间内的 pod 统统被认为未就绪及不采集数据, 默认为 30 秒 。
--horizontal-pod-autoscaler-tolerance #HPA控制器能容忍的数据差异(浮点数,默认为0.1),即新的指标要与当前的阈值差异在0.1或以上,即要大于1+0.1=1.1,或小于1-0.1=0.9,比如阈值为CPU利用率50%,当前为80%,那么80/50=1.6 > 1.1则会触发扩容,分之会缩容。
即触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9=把N个pod的数据相加后根据pod的数量计算出平均数除以阈值,大于1.1就扩容,小于0.9就缩容。
计算公式: TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target) # ceil 是一个向上取整的目的 pod 整数。
metrics-server 部署:
Metrics Server 是 Kubernetes 内置的容器资源指标来源。
Metrics Server 从node节点上的 Kubelet 收集资源指标,并通过Metrics API在 Kubernetes apiserver 中公开指标数据,以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler使用,也可以通过访问kubectl top node/pod 查看指标数据。
metric-server.yaml
root@192:/usr/local/src/20230521/20230521/metrics-server-0.6.1-case# cat metrics-server-v0.6.1.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: bitnami/metrics-server:0.6.1
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
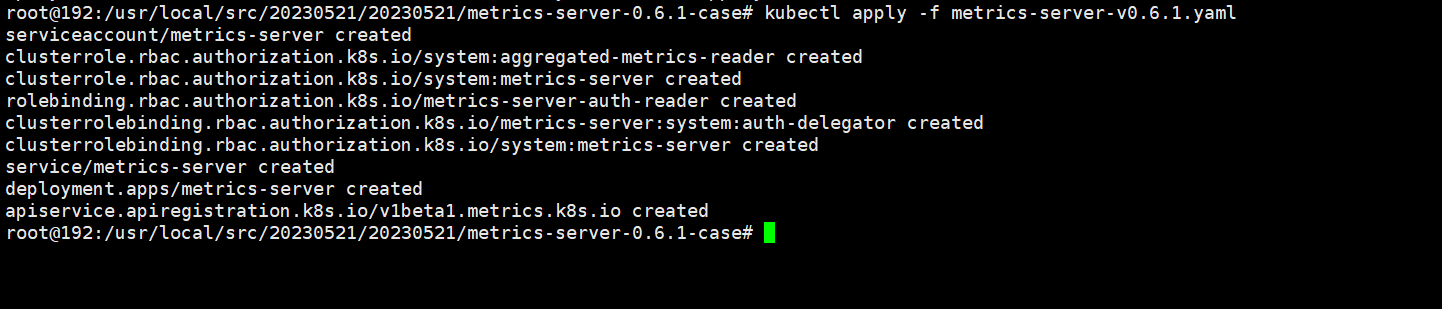
可以看到metrics-server已经生效

HPA控制器部署文件:
apiVersion: autoscaling/v2beta1 # 定义 API 版本
kind: HorizontalPodAutoscaler # 对象类型
metadata: # 定义对象元数据
namespace: linux36 # 创建后隶属的 namespace
name: linux36-tomcat-app1-podautoscaler # 对象名称
labels: 这样的 label 标签
app: linux36-tomcat-app1 # 自定义的 label 名称
version: v2beta1 # 自定义的 api 版本
spec: # 定义对象具体信息
scaleTargetRef: # 定义水平伸缩的目标对象, Deployment 、 ReplicationController/ReplicaSet
apiVersion: apps/v1
#API 版本, HorizontalPodAutoscaler.spec.scaleTargetRef.apiVersion
kind: Deployment # 目标对象类型为 deployment
name: linux36-tomcat-app1-deployment #deployment 的具体名称
minReplicas: 2 # 最小 pod 数
maxReplicas: 5 # 最大 pod 数
metrics: # 调用 metrics 数据定义
- type: Resource # 类型为资源
resource: # 定义资源
name: cpu # 资源名称为 cpu
targetAverageUtilization: 80 #CPU 使用率
- type: Resource # 类型为资源
resource: # 定义资源
name: memory # 资源名称为 memory
targetAverageValue: 1024Mi #memory
创建tomcat的deployment
root@192:/usr/local/src/20230521/20230521/metrics-server-0.6.1-case# cat tomcat-app1.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app1-deployment-label
name: magedu-tomcat-app1-deployment
namespace: magedu
spec:
replicas: 2 #只设定2个副本
selector:
matchLabels:
app: magedu-tomcat-app1-selector
template:
metadata:
labels:
app: magedu-tomcat-app1-selector
spec:
containers:
- name: magedu-tomcat-app1-container
image: tomcat:7.0.93-alpine
#image: lorel/docker-stress-ng
#args: ["--vm", "2", "--vm-bytes", "256M"]
##command: ["/apps/tomcat/bin/run_tomcat.sh"]
imagePullPolicy: IfNotPresent
##imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-tomcat-app1-service-label
name: magedu-tomcat-app1-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
#nodePort: 40003
selector:
app: magedu-tomcat-app1-selector

创建HPA控制器pod
root@192:/usr/local/src/20230521/20230521/metrics-server-0.6.1-case# cat hpa.yaml
#apiVersion: autoscaling/v2beta1
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
namespace: magedu
name: magedu-tomcat-app1-deployment
labels:
app: magedu-tomcat-app1
version: v2beta1
spec:
scaleTargetRef:
apiVersion: apps/v1
#apiVersion: extensions/v1beta1
kind: Deployment
name: magedu-tomcat-app1-deployment
minReplicas: 3 #设定至少3个副本,与deploy的2个副本冲突
maxReplicas: 10
targetCPUUtilizationPercentage: 60
#metrics:
#- type: Resource
# resource:
# name: cpu
# targetAverageUtilization: 60
#- type: Resource
# resource:
# name: memory


pod由2个变成3个,hpa优先级更高,生效。
根据hpa限制,在两个node节点cpu使用率达到60%左右时,停止伸缩控制器
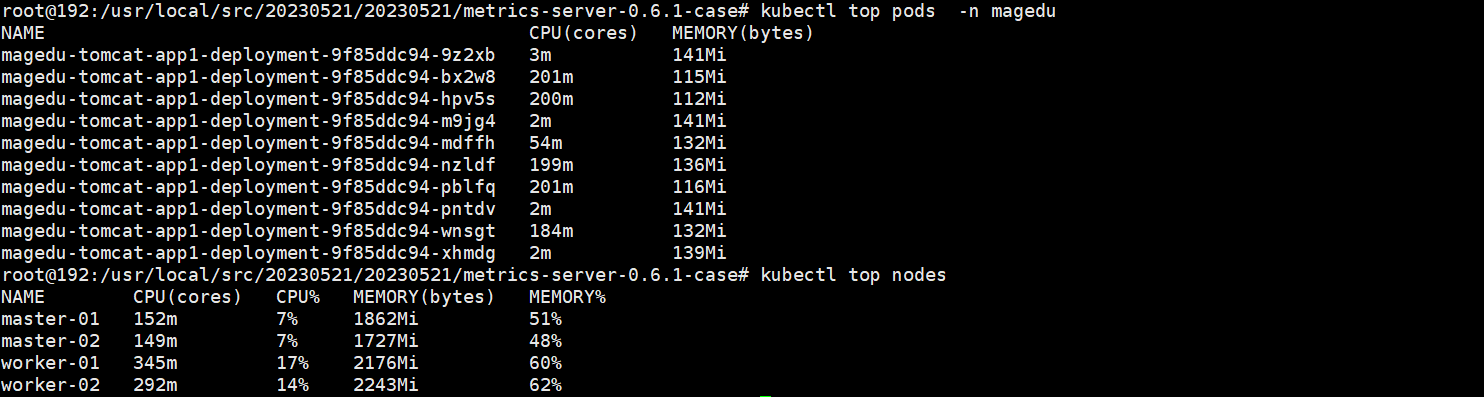
由于pod资源利用率都很低,最后hpa控制器将pod伸缩到最小值3个

查看下hpa控制器日志

kubernetes资源限制
默认情况下, Kubernetes 集群上的容器运行使用的计算资源没有限制。 使用 Kubernetes 资源配额, 管理员(也称为 集群操作者)可以在一个指定的命名空间内限制集群资源的使用与创建。 在命名空间中,一个 Pod 最多能够使用命名空间的资源配额所定义的 CPU 和内存用量。 作为集群操作者或命名空间级的管理员,你可能也会担心如何确保一个 Pod 不会垄断命名空间内所有可用的资源。
LimitRange
LimitRange 是限制命名空间内可为每个适用的对象类别 (例如 Pod 或 PersistentVolumeClaim) 指定的资源分配量(限制和请求)的策略对象。
一个 LimitRange(限制范围) 对象提供的限制能够做到:
在一个命名空间中实施对每个 Pod 或 Container 最小和最大的资源使用量的限制。
在一个命名空间中实施对每个 PersistentVolumeClaim 能申请的最小和最大的存储空间大小的限制。
在一个命名空间中实施对一种资源的申请值和限制值的比值的控制。
设置一个命名空间中对计算资源的默认申请/限制值,并且自动的在运行时注入到多个 Container 中。
当某命名空间中有一个 LimitRange 对象时,将在该命名空间中实施 LimitRange 限制。
LimitRange 的名称必须是合法的 DNS 子域名。
LimitRange 配置文件
apiVersion: v1
kind: LimitRange
metadata:
name: limitrange-magedu
namespace: magedu
spec:
limits:
- type: Container #限制的资源类型
max:
cpu: "2" #限制单个容器的最大CPU
memory: "2Gi" #限制单个容器的最大内存
min:
cpu: "500m" #限制单个容器的最小CPU
memory: "512Mi" #限制单个容器的最小内存
default:
cpu: "500m" #默认单个容器的CPU限制
memory: "512Mi" #默认单个容器的内存限制
defaultRequest:
cpu: "500m" #默认单个容器的CPU创建请求
memory: "512Mi" #默认单个容器的内存创建请求
maxLimitRequestRatio:
cpu: 2 #限制CPU limit/request比值最大为2
memory: 2 #限制内存limit/request比值最大为1.5
- type: Pod
max:
cpu: "4" #限制单个Pod的最大CPU
memory: "4Gi" #限制单个Pod最大内存
- type: PersistentVolumeClaim
max:
storage: 50Gi #限制PVC最大的requests.storage
min:
storage: 30Gi #限制PVC最小的requests.storage
创建一个pod 使单个容器cpu和内存超过限制
root@192:/usr/local/src/20230521/20230521/magedu-limit-case# cat case1-pod-memory-limit.yml
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
kind: Deployment
metadata:
name: limit-test-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels: #rs or deployment
app: limit-test-pod
# matchExpressions:
# - {key: app, operator: In, values: [ng-deploy-80,ng-rs-81]}
template:
metadata:
labels:
app: limit-test-pod
spec:
containers:
- name: limit-test-container
image: lorel/docker-stress-ng
resources:
limits:
cpu: 2.2
memory: "256Mi"
requests:
cpu: 1.5
memory: "256Mi"
#command: ["stress"]
args: ["--vm", "2", "--vm-bytes", "256M"]
#nodeSelector:
# env: group1
创建pod 发现不生效

查看deploy信息,可看到limitrange生效。单个容器cpu和memory超过最大值
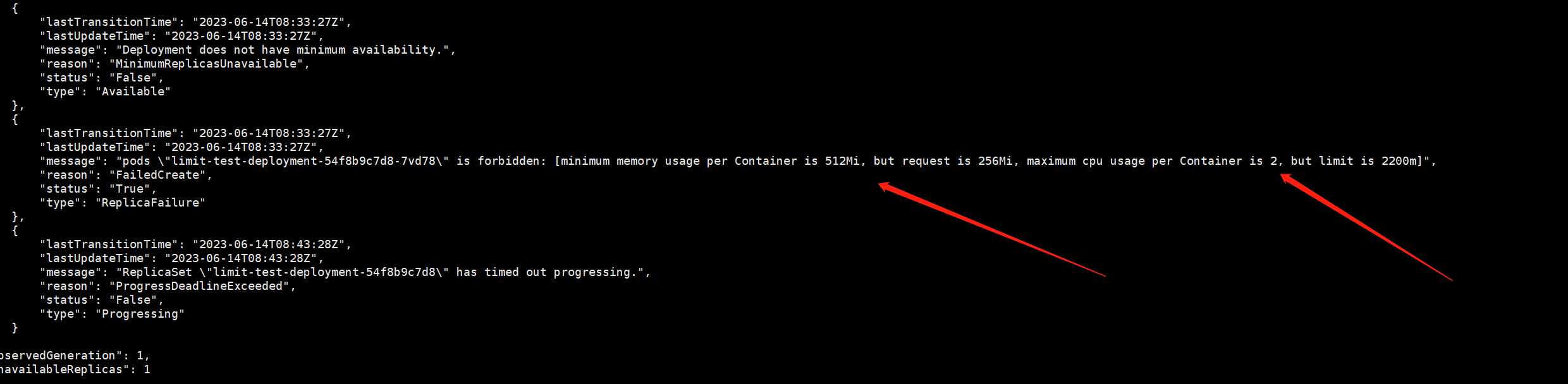
创建pod 使memory limits和request比例超过限制2
root@192:/usr/local/src/20230521/20230521/magedu-limit-case# cat case4-pod-RequestRatio-limit.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: magedu-wordpress-deployment-label
name: magedu-wordpress-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-wordpress-selector
template:
metadata:
labels:
app: magedu-wordpress-selector
spec:
containers:
- name: magedu-wordpress-nginx-container
image: nginx:1.16.1
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 0.5
memory: 0.5Gi
requests:
cpu: 0.5
memory: 0.5Gi
- name: magedu-wordpress-php-container
image: php:5.6-fpm-alpine
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 0.5
memory: 0.5Gi
requests:
cpu: 0.5
memory: 0.5Gi
- name: magedu-wordpress-redis-container
image: redis:4.0.14-alpine
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: 0.5Gi
requests:
cpu: 1
memory: 0.2Gi ##limits requests 比例是2.5 超过限制
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-wordpress-service-label
name: magedu-wordpress-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30033
selector:
app: magedu-wordpress-selector
创建结果

资源配额
资源配额,通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。 它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命名空间中的 Pod 可以使用的计算资源的总上限。
资源配额的工作方式如下:
不同的团队可以在不同的命名空间下工作。这可以通过 RBAC 强制执行。
集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。
当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会跟踪集群的资源使用情况, 以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。
如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
如果命名空间下的计算资源 (如 cpu 和 memory)的配额被启用, 则用户必须为这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 提示: 可使用 LimitRanger 准入控制器来为没有设置计算资源需求的 Pod 设置默认值。
资源配额配置文件
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-magedu
namespace: magedu
spec:
hard:
requests.cpu: "8" #所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。
limits.cpu: "8" #所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。
requests.memory: 4Gi #所有非终止状态的 Pod,其内存需求总量不能超过该值。
limits.memory: 4Gi #所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。
requests.nvidia.com/gpu: 4 #以 GPU 拓展资源为例,如果资源名称为 nvidia.com/gpu,并且要将命名空间中请求的 GPU 资源总数限制为 4
pods: "100" #该命名空间中允许存在的非终止状态的 Pod 总数上限
services: "100" ##在该命名空间中允许存在的 Service 总数上限。
创建一个memory超出限制的deploy
root@192:/usr/local/src/20230521/20230521/magedu-limit-case# cat case7-namespace-pod-limit-test.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: magedu-nginx-deployment-label
name: magedu-nginx-deployment
namespace: magedu
spec:
replicas: 5
selector:
matchLabels:
app: magedu-nginx-selector
template:
metadata:
labels:
app: magedu-nginx-selector
spec:
containers:
- name: magedu-nginx-container
image: nginx:1.16.1
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: 1Gi
requests:
cpu: 1
memory: 1Gi
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-nginx-service-label
name: magedu-nginx-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30033
selector:
app: magedu-nginx-selector
可以看到报错

memory已经占满

RBAC准入控制
基于角色(Role)的访问控制(RBAC)是一种基于组织中用户的角色来调节控制对计算机或网络资源的访问的方法。
RBAC 鉴权机制使用 rbac.authorization.k8s.io API 组来驱动鉴权决定, 允许你通过 Kubernetes API 动态配置策略。
要启用 RBAC,在启动 API 服务器时将 --authorization-mode 参数设置为一个逗号分隔的列表并确保其中包含 RBAC。
kube-apiserver --authorization-mode=Example,RBAC --<其他选项> --<其他选项>
RBAC鉴权流程:
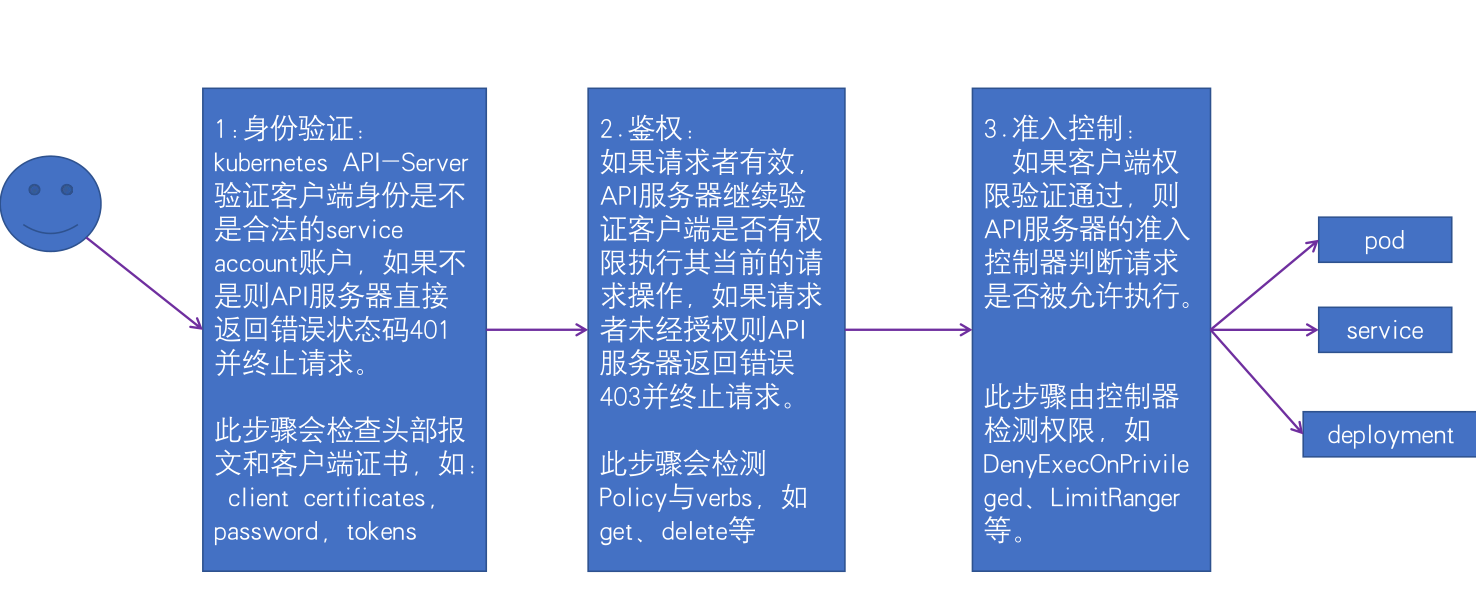
API 对象
RBAC API 声明了四种 Kubernetes 对象:Role、ClusterRole、RoleBinding 和 ClusterRoleBinding。你可以像使用其他 Kubernetes 对象一样,通过类似 kubectl 这类工具描述对象, 或修补对象。
- Role: 定义一组规则,用于访问命名空间中的 Kubernetes 资源。
- RoleBinding: 定义用户和角色(Role)的绑定关系。
- ClusterRole: 定义了一组访问集群中 Kubernetes 资源(包括所有命名空间)的规则。
- ClusterRoleBinding: 定义了用户和集群角色(ClusterRole)的绑定关系。
创建用户magedu-role并使用授权
1.1:在指定namespace创建账户:
# kubectl create serviceaccount magedu -n magedu
serviceaccount/magedu created
1.2:创建role规则:
# kubectl apply -f magedu-role.yaml
role.rbac.authorization.k8s.io/magedu-role created
cat magedu-role.yaml
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: magedu
name: magedu-role
rules:
- apiGroups: ["*"]
resources: ["pods"]
#verbs: ["*"]
##RO-Role
verbs: ["get", "watch", "list"]
- apiGroups: ["*"]
resources: ["pods/exec"]
#verbs: ["*"]
##RO-Role
verbs: ["get", "watch", "list","put","create"]
- apiGroups: ["extensions", "apps/v1"]
resources: ["deployments"]
#verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
##RO-Role
verbs: ["get", "watch", "list"]
- apiGroups: ["*"]
resources: ["*"]
#verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
##RO-Role
verbs: ["get", "watch", "list"]
1.3:将规则与账户进行绑定:
# kubectl apply -f magedu-role-bind.yaml
rolebinding.rbac.authorization.k8s.io/role-bind-magedu created
# cat magedu-role-bind.yaml
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: role-bind-magedu
namespace: magedu
subjects:
- kind: ServiceAccount
name: magedu
namespace: magedu
roleRef:
kind: Role
name: magedu-role
apiGroup: rbac.authorization.k8s.io
1.4:获取token名称:
kubectl apply -f magedu-token.yaml
kubectl get secret -n magedu | grep magedu

1.5:使用base加密:
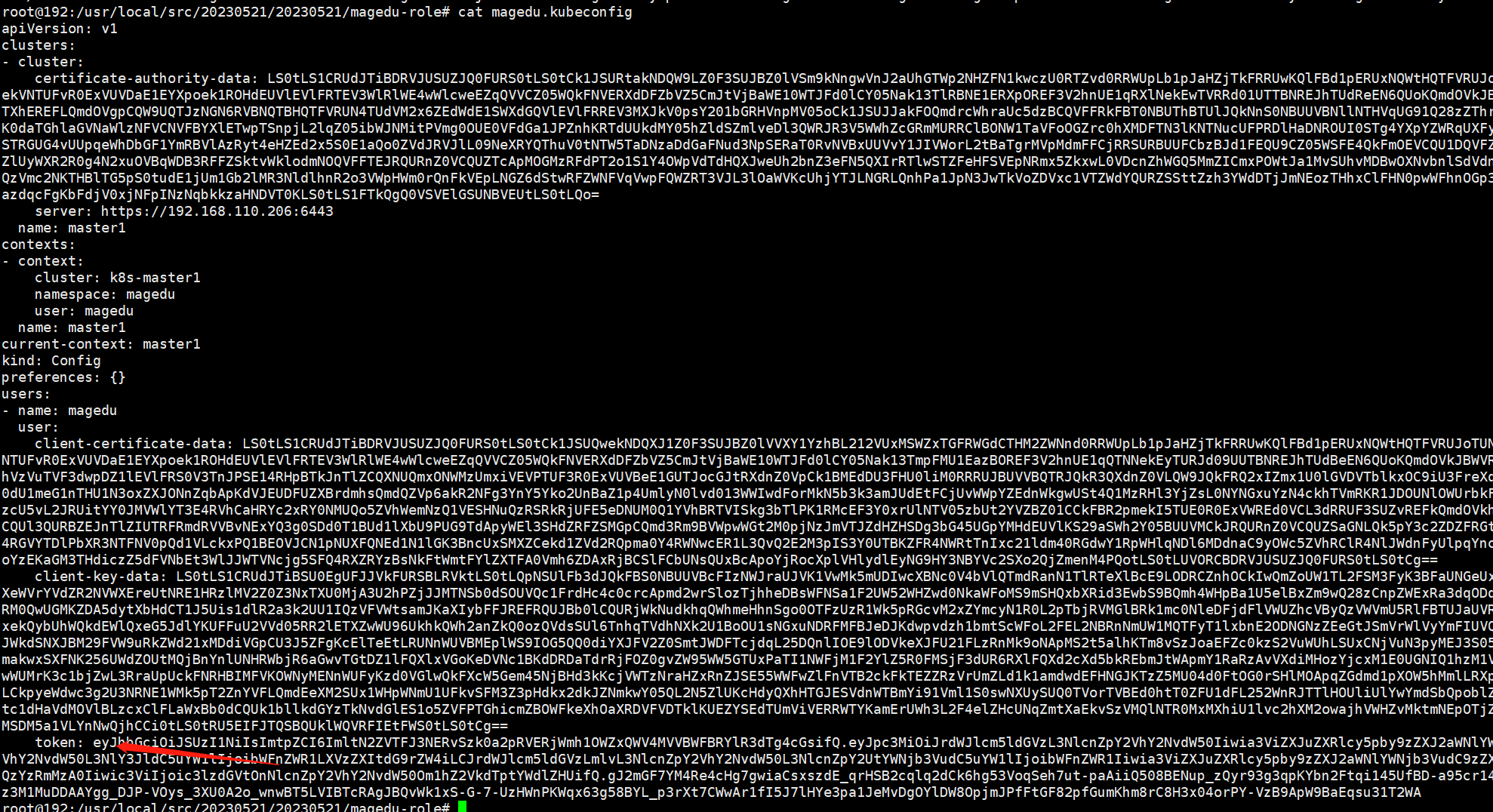
# kubectl get secret magedu-user-token -o jsonpath={.data.token} -n magedu |base64 -d
eyJhbGciOiJSUzI1NiIsImtpZCI6ImltN2ZVTFJ3NERvSzk0a2pRVERjWmh1OWZxQWV4MVVBWFBRYlR3dTg4cGsifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtYWdlZHUiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlY3JldC5uYW1lIjoibWFnZWR1LXVzZXItdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoibWFnZWR1Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiMDQwNzVlZjgtY2FmYy00NTdhLWE1ZGYtYzgzZjQzYzRmMzA0Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Om1hZ2VkdTptYWdlZHUifQ.gJ2mGF7YM4Re4cHg7gwiaCsxszdE_qrHSB2cqlq2dCk6hg53VoqSeh7ut-paAiiQ508BENup_zQyr93g3qpKYbn2Ftqi145UfBD-a95cr14JKtgB38-aNQiAd2A-oC9SmvTKPzKqOYCtmWAD0mjrVYHgH8z1aBe-m1EV9REzdFqz3M1MuDDAAYgg_DJP-VOys_3XU0A2o_wnwBT5LVIBTcRAgJBQvWk1xS-G-7-UzHWnPKWqx63g58BYL_p3rXt7CWwAr1fI5J7lHYe3pa1JeMvDgOYlDW8OpjmJPfFtGF82pfGumKhm8rC8H3x04orPY-VzB9ApW9BaEqsu31T2WA
登录测试 输入token后,可以发现只能看到magedu namespace下的pod看不到别的名称空间
基于kube-config文件登录:
2.1:创建csr文件:
# cat magedu-csr.json
{
"CN": "China",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
2.2:签发证书:
# ln -sv /etc/kubeasz/bin/cfssl* /usr/bin/
# cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem -ca-key=/etc/kubernetes/ssl/ca-key.pem -config=/etc/kubeasz/clusters/k8s-cluster1/ssl/ca-config.json -profile=kubernetes magedu-csr.json | cfssljson -bare magedu

# ls magedu*
magedu-csr.json magedu-key.pem magedu-role-bind.yaml magedu-role.yaml magedu.csr magedu.pem
2.3:生成普通用户kubeconfig文件:
# kubectl config set-cluster master1 --certificate-authority=/etc/kubernetes/ssl/ca.pem --embed-certs=true --server=https://192.168.110.206:6443 --kubeconfig=magedu.kubeconfig #--embed-certs=true为嵌入证书信息
2.4:设置客户端认证参数:
# cp *.pem /etc/kubernetes/ssl/
# kubectl config set-credentials magedu \
--client-certificate=/etc/kubernetes/ssl/magedu.pem \
--client-key=/etc/kubernetes/ssl/magedu-key.pem \
--embed-certs=true \
--kubeconfig=magedu.kubeconfig

2.5:设置上下文参数(多集群使用上下文区分)
# kubectl config set-context master1 \
--cluster=k8s-master1 \
--user=magedu \
--namespace=magedu \
--kubeconfig=magedu.kubeconfig
2.5: 设置默认上下文
# kubectl config use-context master1 --kubeconfig=magedu.kubeconfig
2.7:获取token: 并将其输入到magedu.kubeconfig中 将文件拷出来
# kubectl get secrets -n magedu | grep magedu


kubernetes 亲和与反亲和
你可以约束一个 Pod 以便 限制 其只能在特定的节点上运行, 或优先在特定的节点上运行。有几种方法可以实现这点,推荐的方法都是用 标签选择算符来进行选择。 通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 Pod 分散到节点上, 而不是将 Pod 放置在可用资源不足的节点上等等)。但在某些情况下,你可能需要进一步控制 Pod 被部署到哪个节点。例如,确保 Pod 最终落在连接了 SSD 的机器上, 或者将来自两个不同的服务且有大量通信的 Pod 被放置在同一个可用区。
nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。你可以将 nodeSelector 字段添加到 Pod 的规约中设置你希望目标节点所具有的节点标签。 Kubernetes 只会将 Pod 调度到拥有你所指定的每个标签的节点上。
实例:
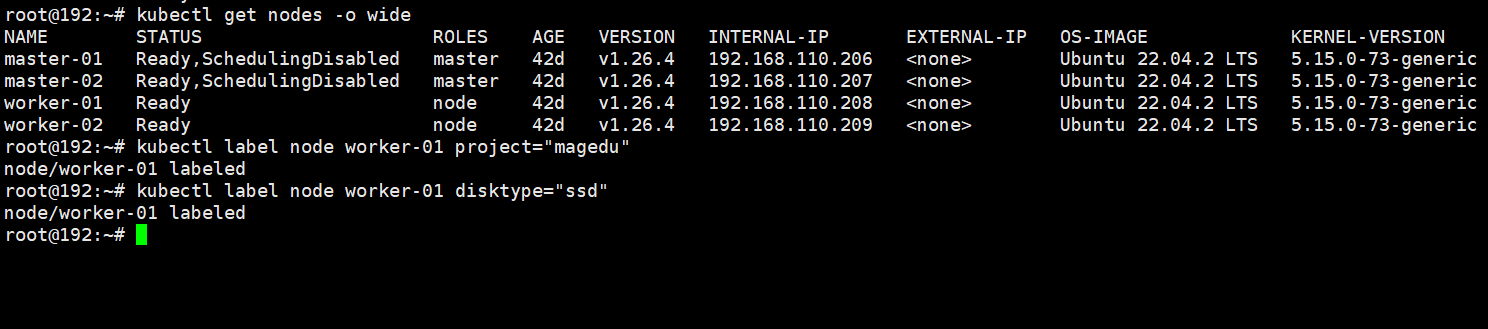
node1上打标签
kubectl label node worker-01 project="magedu"
kubectl label node worker-01 disktype="ssd"
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case1-nodeSelector.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 4
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
nodeSelector:
project: magedu #匹配标签
disktype: ssd #只有worker-01满足,因此pod会调度到worker-01上

NodeName
根据node名称选择调度。实际生产中应用较少
kubectl label node worker-02 disktype=ssd
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case2-nodename.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
nodeName: worker-02 ##规定pod所在节点的名称
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"

Node affinity 亲和性匹配
affinity是Kubernetes 1.2版本后引入的新特性,类似于nodeSelector,允许使用者指定一些Pod在Node间调度的约束,目前支持两种形式:
- requiredDuringSchedulingIgnoredDuringExecution #必须满足pod调度匹配条件,如果不满足则不进行调度
- preferredDuringSchedulingIgnoredDuringExecution #倾向满足pod调度匹配条件,不满足的情况下会调度的不符合条件的Node上
- IgnoreDuringExecution表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,也会继续运行当前的Pod。
- Affinity与anti-affinity的目的也是控制pod的调度结果,但是相对于nodeSelector,Affinity(亲和)与anti-affinity(反亲和)的功能更加强大
affinity与nodeSelector对比:
1、亲和与反亲和对目的标签的选择匹配不仅仅支持and,还支持In、NotIn、Exists、DoesNotExist、Gt、Lt。
- In:标签的值存在匹配列表中(匹配成功就调度到目的node,实现node亲和)
- NotIn:标签的值不存在指定的匹配列表中(不会调度到目的node,实现反亲和)
- Gt:标签的值大于某个值(字符串)
- Lt:标签的值小于某个值(字符串)
- Exists:指定的标签存在
2、可以设置软匹配和硬匹配,在软匹配下,如果调度器无法匹配节点,仍然将pod调度到其它不符合条件的节点。
3、还可以对pod定义亲和策略,比如允许哪些pod可以或者不可以被调度至同一台node。
注:
-
如果定义一个nodeSelectorTerms(条件)中通过一个matchExpressions基于列表指定了多个operator条件,则只要满足其中一个条件,就会被调度到相应的节点上,即or的关系,即如果nodeSelectorTerms下面有多个条件的话,只要满足任何一个条件就可以调度
-
如果定义一个nodeSelectorTerms中都通过一个matchExpressions(匹配表达式)指定key匹配多个条件,则所有的目的条件都必须满足才会调度到对应的节点,即and的关系,即果matchExpressions有多个选项的话,则必须同时满足所有这些条件才能正常调度
-
如果你同时指定了 nodeSelector 和 nodeAffinity,两者必须都要满足,才能将 Pod 调度到候选节点上。
case3-1.1-nodeAffinity-requiredDuring-matchExpressions.yaml
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case3-1.1-nodeAffinity-requiredDuring-matchExpressions.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配条件1,有一个key但是有多个values、则只要匹配成功一个value就可以调度
- key: disktype
operator: In
values:
- ssd # 只有一个value是匹配成功也可以调度
- xxx
- matchExpressions: #匹配条件2,有一个key但是有多个values、则只要匹配成功一个value就可以调度 ;
- key: project
operator: In
values:
- xxx #即使这俩条件都匹配不上也可以调度,即多个matchExpressions只要有任意一个能匹配任何一个value就可以调用。
- nnn
测试 worker01 disktype=ssd; worker02 disktype=hdd

由于条件2都不满足,而条件1 disktype=ssd 或 xxx worker01满足,因此调度到worker-01节点上
case3-1.2-nodeAffinity-requiredDuring-matchExpressions.yaml
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case3-1.2-nodeAffinity-requiredDuring-matchExpressions.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配条件1,同一个key的多个value只有有一个匹配成功就认为当前key匹配成功
- key: disktype
operator: In
values:
- ssd
- hdd
- key: project #匹配条件2,当前key也要匹配成功一个value,即条件1和条件2必须同时每个key匹配成功一个value,否则不调度
operator: In
#values:magedu
values:none

由于匹配条件2不符合 worker01 02 都无法调度pod
case3-2.1-nodeAffinity-preferredDuring.yaml 节点软亲和
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case3-2.1-nodeAffinity-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80 软亲和条件1,weight值越大优先级越高,越优先匹配调度
preference:
matchExpressions:
- key: project
operator: In
values:
- magedu
- weight: 60 #软亲和条件2,在条件1不满足时匹配条件2
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd

worker-01最符合,优先调用
case3-2.2-nodeAffinity-requiredDuring-preferredDuring.yaml 硬反亲和 软亲和搭配使用
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case3-2.2-nodeAffinity-requiredDuring-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #Ó²Ç׺Í
nodeSelectorTerms:
- matchExpressions: #ӲƥÅäÌõ¼þ1
- key: "kubernetes.io/role"
operator: NotIn
values:
- "master" #Ó²ÐÔÆ¥Åäkey µÄÖµkubernetes.io/role²»°üº¬masterµÄ½Úµã,¼´¾ø¶Ô²»»áµ÷¶Èµ½master½Úµã(node·´Ç׺Í)
preferredDuringSchedulingIgnoredDuringExecution: #ÈíÇ׺Í
- weight: 60
preference:
matchExpressions:
- key: project
operator: In
values:
- magedu
- weight: 80
preference:
matchExpressions:
- key: disktype
operator: In
values:
- hdd
由于反亲和,master节点无法调度,而由于 disktype In hdd条件比重较大,因此worker02更加符合

case3-3.1-nodeantiaffinity.yaml 反亲和
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配条件1
- key: disktype
operator: NotIn #调度的目的节点没有key为disktype且值为hdd的标签
values:
- hhd #绝对不会调度到含有label的key为disktype且值为hdd的hdd的节点,即会调度到没有key为disktype且值为hdd的hdd的节点
如图,无法调度disktype = hdd的02节点,因此调度到01上

pod Affinity与pod anti-affinity
Pod 亲和性与反亲和性可以基于已经在node节点上运行的Pod的标签来 约束新创建的 Pod 可以调度到的目的节点,注意不是基于node上的标签而是使用的已经运行在node上的pod标签匹配。
其规则的格式为如果 node 节点 A A已经运行了一个或多个 满足调度新创建的 Pod B 的规则,那么新的Pod B在亲和的条件下会调度到A节点之上,而在反亲和性的情况下则不会调度到A节点至上。
其中规则表示一个具有可选的关联命名空间列表的 LabelSelector,只所以Pod亲和与反亲和需可以通过LabelSelector选择namespace,是因为Pod是命名空间限定的而node不属于任何nemespace所以node的亲和与反亲和不需要namespace,因此作用于Pod标签的 标签选择算符必须指定选择算符应用在哪个命名空间。
从概念上讲,node节点是一个拓扑域(具有拓扑结构的区域、宕机的时候的故障域),比如k8s集群中的单台node节点、一个机架、云供应商可用区、云供应商地理区域等,可以使用topologyKey来定义亲和或者反亲和的颗粒度是node级别还是可用区级别 ,以便 kubernetes 调度系统用来识别并选择正确的目的拓扑域
pod亲和性和反亲和性参数
Pod 亲和性与反亲和性的合法操作符 (operator) 有 In 、 NotIn 、 Exists 、 DoesNotExist 。
在Pod亲和性配置中,在requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution中,topologyKey不允许为空(Empty topologyKey is not allowed.)。
在Pod反亲和性中配置中,requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution 中,topologyKey也不可以为空(Empty topologyKey is not allowed.)。
对于requiredDuringSchedulingIgnoredDuringExecution要求的Pod反亲和性,准入控制器LimitPodHardAntiAffinityTopology被引入以确保topologyKey只能是 kubernetes.io/hostname,如果希望 topologyKey 也可用于其他定制拓扑逻辑,可以更改准入控制器或者禁用。
除上述情况外,topologyKey 可以是任何合法的标签键。
nginx.yaml
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case4-4.1-nginx.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: python-nginx-deployment-label
name: python-nginx-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: python-nginx-selector
template:
metadata:
labels:
app: python-nginx-selector
project: python
spec:
containers:
- name: python-nginx-container
image: nginx:1.20.2-alpine
#command: ["/apps/tomcat/bin/run_tomcat.sh"]
#imagePullPolicy: IfNotPresent
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
- containerPort: 443
protocol: TCP
name: https
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
# resources:
# limits:
# cpu: 2
# memory: 2Gi
# requests:
# cpu: 500m
# memory: 1Gi
---
kind: Service
apiVersion: v1
metadata:
labels:
app: python-nginx-service-label
name: python-nginx-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
nodePort: 30014
- name: https
port: 443
protocol: TCP
targetPort: 443
nodePort: 30453
selector:
app: python-nginx-selector
project: python #一个或多个selector,至少能匹配目标pod的一个标签
case4-4.2-podaffinity-preferredDuring.yaml软亲和
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case4-4.2-podaffinity-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 2
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAffinity: #Pod亲和
#requiredDuringSchedulingIgnoredDuringExecution: #硬亲和,必须匹配成功才调度,如果匹配失败则拒绝调度。
preferredDuringSchedulingIgnoredDuringExecution: #软亲和,能匹配成功就调度到一个topology,匹配不成功会由kubernetes自行调度。
- weight: 100
podAffinityTerm:
labelSelector: #标签选择
matchExpressions: #正则匹配
- key: project
operator: In
values:
- pythonX
topologyKey: kubernetes.io/hostname
namespaces:
- magedu

可以看到虽然匹配失败 没有 project = pythonX标签 pod依然调度到两个节点上
case4-4.3-podaffinity-requiredDuring.yaml pod硬亲和
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case4-4.3-podaffinity-requiredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #硬亲和
- labelSelector:
matchExpressions:
- key: project
operator: In
values:
- python
topologyKey: "kubernetes.io/hostname"
namespaces:
- magedu
由于 project=python 只有01上的pod有,而且是硬亲和,因此tomcat的pod都在01上

硬亲和多用于将pod整合到一起以减少资源开销的作用
case4-4.4-podAntiAffinity-requiredDuring.yaml 硬反亲和
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case4-4.4-podAntiAffinity-requiredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 3
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: project
operator: In
values:
- python
topologyKey: "kubernetes.io/hostname"
namespaces:
- magedu

由于是硬反亲和,所以pod都在另一个节点上
case4-4.5-podAntiAffinity-preferredDuring.yaml软反亲和
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case4-4.5-podAntiAffinity-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 20
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: project
operator: In
values:
- python
topologyKey: kubernetes.io/hostname
namespaces:
- magedu
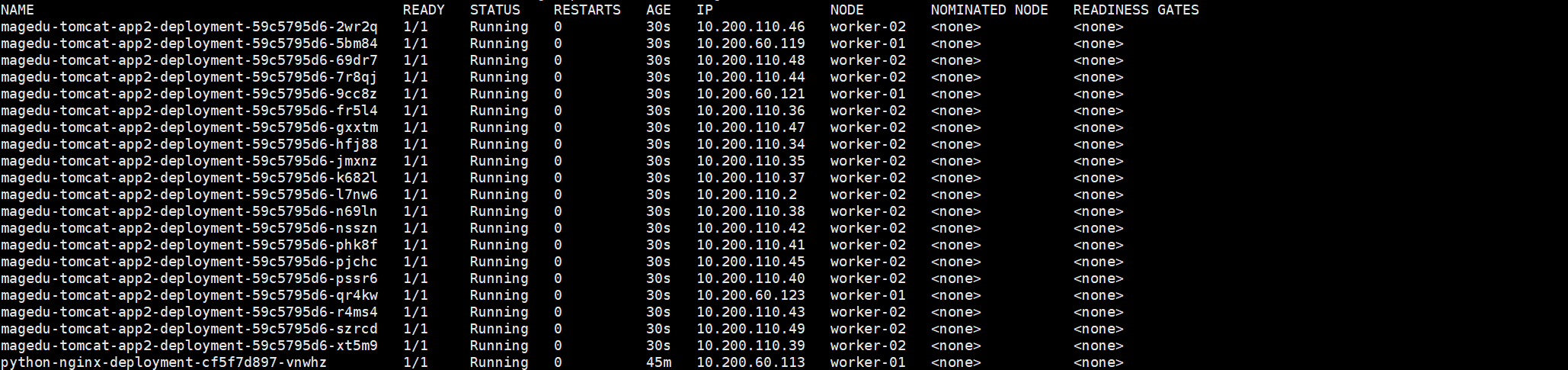
由于是软反亲和 ,01虽然不符合条件,但不会强制将pod调度在02上,但可以看出02上面pod比较多。
污点和容忍
节点亲和性 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点 (这可能出于一种偏好,也可能是硬性要求)。 污点(Taint) 则相反——它使节点能够排斥一类特定的 Pod。
容忍度(Toleration) 是应用于 Pod 上的。容忍度允许调度器调度带有对应污点的 Pod。 容忍度允许调度但并不保证调度:作为其功能的一部分, 调度器也会评估其他参数。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod, 是不会被该节点接受的。
污点的三种类型:
NoSchedule: 表示k8s将不会将Pod调度到具有该污点的Node上
kubectl taint nodes 192.168.110.207 key1=value1:NoSchedule #设置污点
kubectl describe node 192.168.110.207#查看污点
kubectl taint node 192.168.110.207 key1:NoSchedule- #取消污点
PreferNoSchedule: 表示k8s将尽量避免将Pod调度到具有该污点的Node上
NoExecute: 表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod强制驱逐出去
kubectl taint nodes 192.168.110.207 key1=value1:NoExecute
容忍简介
tolerations容忍:
- 定义 Pod 的容忍度(可以接受node的哪些污点),容忍后可以将Pod调度至含有该污点的node。
基于operator的污点匹配:
- 如果operator是Exists,则容忍度不需要value而是直接匹配污点类型。
- 如果operator是Equal,则需要指定value并且value的值需要等于tolerations的key。
节点打上污点信息:
# kubectl taint nodes worker02 key1=value1:NoSchedule
测试对污点容忍和不容忍分别能否调度:
# kubectl apply -f case5.1-taint-tolerations.yaml
污点的删除:
# kubectl taint nodes worker-02 key1:NoSchedule-
root@192:/usr/local/src/20230521/20230521/Affinit-case# cat case5.1-taint-tolerations.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app1-deployment-label
name: magedu-tomcat-app1-deployment
namespace: magedu
spec:
replicas: 2
selector:
matchLabels:
app: magedu-tomcat-app1-selector
template:
metadata:
labels:
app: magedu-tomcat-app1-selector
spec:
containers:
- name: magedu-tomcat-app1-container
#image: harbor.magedu.net/magedu/tomcat-app1:v7
image: tomcat:7.0.93-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
protocol: TCP
name: http
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-tomcat-app1-service-label
name: magedu-tomcat-app1-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
#nodePort: 40003
selector:
app: magedu-tomcat-app1-selector
给01打上污点

创建pod后,由于pod里面有容忍,因此pod依然可以调度到01上

kubernetes pod驱逐 :
节点压力驱逐是由各kubelet进程主动终止Pod,以回收节点上的内存、磁盘空间等资源的过程,kubelet监控当前node节点的CPU、内存、磁盘空间和文件系统的inode等资源,当这些资源中的一个或者多个达到特定的消耗水平,kubelet就会主动地将节点上一个或者多个Pod强制驱逐,以防止当前node节点资源无法正常分配而引发的OOM(OutOfMemory)。
污点的效果值 NoExecute 会影响已经在节点上运行的如下 Pod:
如果 Pod 不能忍受这类污点,Pod 会马上被驱逐。
如果 Pod 能够忍受这类污点,但是在容忍度定义中没有指定 tolerationSeconds, 则 Pod 还会一直在这个节点上运行。
如果 Pod 能够忍受这类污点,而且指定了 tolerationSeconds, 则 Pod 还能在这个节点上继续运行这个指定的时间长度。
驱逐规则:
驱逐(eviction,节点驱逐),用于当node节点资源不足的时候自动将pod进行强制驱逐,以保证当前node节点的正常运行。
Kubernetes基于是QoS(服务质量等级)驱逐Pod , Qos等级包括目前包括以下三个:
Guaranteed: # limits 和 request 的值相等,等级最高、最后被驱逐
resources:
limits:
cpu: 500m
memory: 256Mi
requests:
cpu: 500m
memory: 256Mi
Burstable: # limit 和 request 不相等,等级折中、中间被驱逐
resources:
limits:
cpu: 500m
memory: 256Mi
requests:
cpu: 256m
memory: 128Mi
BestEffort: # 没有限制,即 resources 为空,等级最低、最先被驱逐
驱逐条件:
eviction-signal : kubelet 捕获 node 节点驱逐触发信号,进行判断是否驱逐,比如通过cgroupfs获取memory.available的值来进行下一步匹配。
operator :操作符,通过操作符对比条件是否匹配资源量是否触发驱逐。
quantity :使用量,即基于指定的资源使用值进行判断,如memory.available: 300Mi、nodefs.available: 10%等。
比如: nodefs.available<10% 表示当node节点磁盘空间可用率低于10%就触发驱逐
软驱逐:
软驱逐不会立即驱逐pod,可以自定义宽限期,在条件持续到宽限期还没有恢复,kubelet再强制杀死pod并触发驱逐:
软驱逐条件:
• eviction-soft : 软驱逐触发条件,比如memory.available < 1.5Gi,如果驱逐条件持续时长超过指定的宽限期,可以触发Pod驱逐。
• eviction-soft-grace-period :软驱逐宽限期, 如 memory.available=1m30s,定义软驱逐条件在触发Pod驱逐之前必须保持多长时间。
• eviction-max-pod-grace-period :终止 pod 的宽限期,即在满足软驱逐条件而终止Pod时使用的最大允许宽限期(以秒为单位)。
硬驱逐:
硬驱逐条件没有宽限期,当达到硬驱逐条件时, kubelet 会强制立即杀死 pod 并驱逐:
kubelet 具有以下默认硬驱逐条件( ( 可以自行调整) ) :
memory.available<100Mi
nodefs.available<10%
imagefs.available<15%
nodefs.inodesFree<5% ( Linux 节点)
配置驱逐规则的文件 kubelet
/etc/systemd/system/kubelet.service
/var/lib/kubelet/config.yaml
**Kube 预留值 **
Kubelet 标志:--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]
Kubelet 标志:--kube-reserved-cgroup=
kube-reserved 用来给诸如 kubelet、容器运行时、节点问题监测器等 Kubernetes 系统守护进程记述其资源预留值。 该配置并非用来给以 Pod 形式运行的系统守护进程预留资源。kube-reserved 通常是节点上 Pod 密度的函数。
要选择性地对 Kubernetes 系统守护进程上执行 kube-reserved 保护,需要把 kubelet 的 --kube-reserved-cgroup 标志的值设置为 kube 守护进程的父控制组。
注意,如果 --kube-reserved-cgroup 不存在,Kubelet 将 不会 创建它。 如果指定了一个无效的 cgroup,Kubelet 将会失败。就 systemd cgroup 驱动而言, 你要为所定义的 cgroup 设置名称时要遵循特定的模式: 所设置的名字应该是你为 --kube-reserved-cgroup 所给的参数值加上 .slice 后缀

 浙公网安备 33010602011771号
浙公网安备 33010602011771号