

ASCII编码:Linux&Windows
我们的服务器为linux系统,日志中的字段通常会用不同分隔符来做分隔,在不同操作系统编码格式下查看也会有不同的体现,甚至会出现所谓的乱码。我在xshell5下常用的编码格式Unicode(UTF-8)和默认语言。通常xshell5的默认语言能查看到分隔符隔开的字段,而utf-8不能。在网上查了下\001作为分隔符的日志,从linux终端复制出来用notePad打开时看到的SOH,而\002分隔的,从终端复制到编辑器是里STX。。。
比如下案例:
一 java代码: public class appendTest { public static void main(String[] args) { String string1 = "HOW"; String string2 = "DO"; String string3 = "YOU"; String string4 = "DO"; StringBuffer clickBuffer = new StringBuffer(); clickBuffer.append(string1).append("\001").append(string2).append("\002").append(string3).append("\003").append(string4); System.out.println(clickBuffer); } }
二 放到linux下编译运行:javac appendTest.java;java appendTest.查看结果
默认语言时:linux下显示为--,复制到notePad++中,显示为
unicode时:HOWDOYOUDO。
java代码中:会写成"\001" "\002",或者任意其他字符,作为分隔。
 ,复制到notePad++中,显示为
,复制到notePad++中,显示为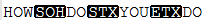
我在查看日志时,大多从linux终端(默认语言下)复制到notePad++里,再用编辑器的替换功能,按分隔符换行,对比各个字段。如需调用接口进行插入,则在notepad++里将分隔符替换成"\001"之类写入时的分隔符,进行写入。
下面是网上找的一些资料,不过并不是我想要的,后续再熟悉熟悉看。
1 ASCII码
在计算机内部,所有的信息最终都表示为一个二进制的字符串,每一个二进制位(bit)有0和1两种状态,因此八个二进制就可以组合出2的8次方=256种状态,被称为一个字节(byte),即,一个字节可以用来表示256种不同的状态,从00000000到11111111。上个世纪60年代,美国指定了一套字符编码,对英语字符和二进制位之间的关系,做了统一规定。被称为ASCII码。ASCII一共规定了128个字符的编码,占用一个字节的后7位,最前面的1位统一规定为0。比如空格"SPACE"是32,即00100000.
英语用128个符号编码就够了,但是其他语言,128个符号并不能满足需求。另不同的国家有不同的字母。哪怕他们都是用256个符号的编码方式,代表的字母却不一样。因此编码格式是多种多样的。
2 Unicode
世家上存在如此多的编码方式,同一个二进制数字便可被解释成不同的符号。因为打开文件必须知道它的编码方式,否则用错误的方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字"严"。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
然后Unicode也有它自己的问题,它只是一个符号集,只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如汉字"严"的unicode是十六进制数4E25,转成二进制足足有15位 100111000100101,也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前面必然有几个字节是0,对于存储来说,文本文件的大小会因此大出二三倍,这是无法接受的。他们造成的结果是:1)出现了Unicode的多种存储方式,也就是说有许多不同的二进制格式,可以用来表示Unicode;2)Unicode在很长的一段时间内无法推广,直到互联网出现。
3.UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
解读UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
ASCII编码-控制字符
| 二进制 | 十进制 | 十六进制 | 控制字符 | 转义字符 | 说明 |
|---|---|---|---|---|---|
| 000 0000 | 0 | 00 | NUL | Null character(空字符) | |
| 000 0001 | 1 | 01 | SOH | Start of Header(标题开始) | |
| 000 0010 | 2 | 02 | STX | Start of Text(正文开始) | |
| 000 0011 | 3 | 03 | ETX | End of Text(正文结束) | |
| 000 0100 | 4 | 04 | EOT | End of Transmission(传输结束) | |
| 000 0101 | 5 | 05 | ENQ | Enquiry(请求) | |
| 000 0110 | 6 | 06 | ACK | Acknowledgment(收到通知) | |
| 000 0111 | 7 | 07 | BEL | a | Bell(响铃) |
| 000 1000 | 8 | 08 | BS | b | Backspace(退格) |
| 000 1001 | 9 | 09 | HT | t | Horizontal Tab(水平制表符) |
| 000 1010 | 10 | 0A | LF | n | Line feed(换行键) |
| 000 1011 | 11 | 0B | VT | v | Vertical Tab(垂直制表符) |
| 000 1100 | 12 | 0C | FF | f | Form feed(换页键) |
| 000 1101 | 13 | 0D | CR | r | Carriage return(回车键) |
| 000 1110 | 14 | 0E | SO | Shift Out(不用切换) | |
| 000 1111 | 15 | 0F | SI | Shift In(启用切换) | |
| 001 0000 | 16 | 10 | DLE | Data Link Escape(数据链路转义) | |
| 001 0001 | 17 | 11 | DC1 | Device Control 1(设备控制1) | |
| 001 0010 | 18 | 12 | DC2 | Device Control 2(设备控制2) | |
| 001 0011 | 19 | 13 | DC3 | Device Control 3(设备控制3) | |
| 001 0100 | 20 | 14 | DC4 | Device Control 4(设备控制4) | |
| 001 0101 | 21 | 15 | NAK | Negative Acknowledgement(拒绝接收) | |
| 001 0110 | 22 | 16 | SYN | Synchronous Idle(同步空闲) | |
| 001 0111 | 23 | 17 | ETB | End of Trans the Block(传输块结束) | |
| 001 1000 | 24 | 18 | CAN | Cancel(取消) | |
| 001 1001 | 25 | 19 | EM | End of Medium(介质中断) | |
| 001 1010 | 26 | 1A | SUB | Substitute(替补) | |
| 001 1011 | 27 | 1B | ESC | e | Escape(溢出) |
| 001 1100 | 28 | 1C | FS | File Separator(文件分割符) | |
| 001 1101 | 29 | 1D | GS | Group Separator(分组符) | |
| 001 1110 | 30 | 1E | RS | Record Separator(记录分离符) | |
| 001 1111 | 31 | 1F | US | Unit Separator(单元分隔符) |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号