

MaxCompute - ODPS重装上阵 第七弹 - Grouping Set, Cube and Rollup
MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务。 MaxCompute除了持续优化性能外,也致力于提升SQL语言的用户体验和表达能力,提高广大ODPS开发者的生产力。
MaxCompute基于ODPS2.0新一代的SQL引擎,显著提升了SQL语言编译过程的易用性与语言的表达能力。我们在此推出MaxCompute(ODPS2.0)重装上阵系列文章
- 第一弹 - 善用MaxCompute编译器的错误和警告
- 第二弹 - 新的基本数据类型与内建函数
- 第三弹 - 复杂类型
- 第四弹 - CTE,VALUES,SEMIJOIN
- 第五弹 - SELECT TRANSFORM
- 第六弹 - User Defined Type
- 第七弹 - Grouping Set, Cube and Rollup
第六弹向您介绍了User Defined Type,本篇将向您介绍MaxCompute对GROUPING SETS的支持。
场景
由于业务需求,需要经常对数据进行多维度的聚合分析,如既需要对a列做聚合也要对b列做聚合,同时也要按照a、b两列同时做聚合,所以,不得不写很多很多的UNION ALL,因此造成了很多重复代码,维护起来不方便。
该场景的问题,可以通过使用Grouping Sets能够非常好地解决。
本文中很多例子采用MaxCompute Studio作展示,没有安装MaxCompute Studio的用户,可以参照wiki安装MaxCompute Studio,导入测试MaxCompute项目,创建工程。
功能简介
MaxCompute中的GROUPING SETS功能是SELECT语句中GROUP BY子句的扩展。允许采用多种方式对结果分组,而不必使用多个SELECT语句来实现这一目的。这样能够使MaxCompute的引擎给出更有的执行计划,从而提高执行性能。
如下例子:
-
准备数据。数据源requests表记录了某系统收到的请求。

- 需求:在city维度和os、device维度计算请求数量,同时计算总的请求数。
之前解法,必须使用多个 SELECT 语句计算多个分组,并且用UNION ALL把它们连接起来:
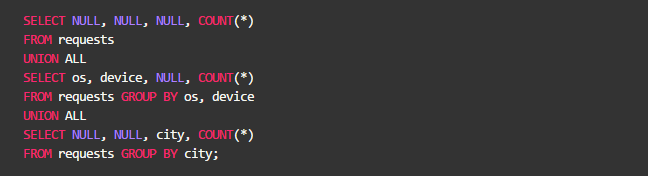
通过MaxCompute Studio的执行图,我们可以看出,物理执行计划是做了3次聚合,然后再UNION起来。
-
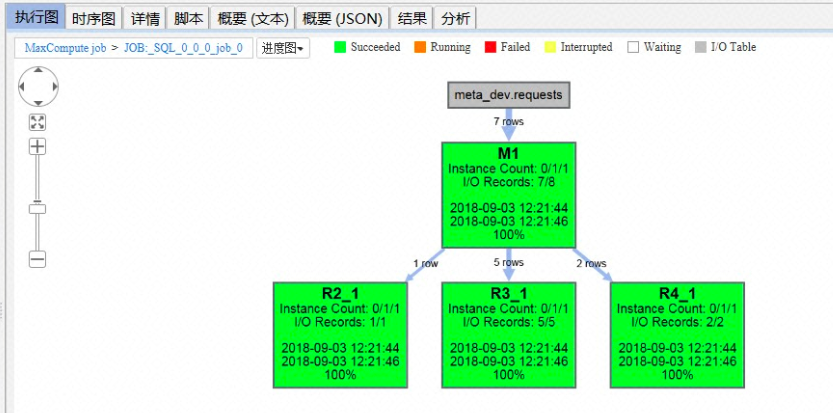
GROUPING SETS语法可以做到相同的逻辑,同时,使用更少的代码,消耗更少的集群资源:

- GROUPING SETS语法和普通GROUP BY类似,但需要额外执行所需的多个GROUP BY组合。例如以上SQL的((os, device), (city), ()), 请注意这是一个2层的括号,每个内层括号执行一个GROUP BY组合;空括号表示GROUP BY列表为空,即COUNT所有列。
- 观察MaxCompute Studio的执行图,我们发现,物理执行计划只包含一个Reduce阶段,无需进行UNION操作。
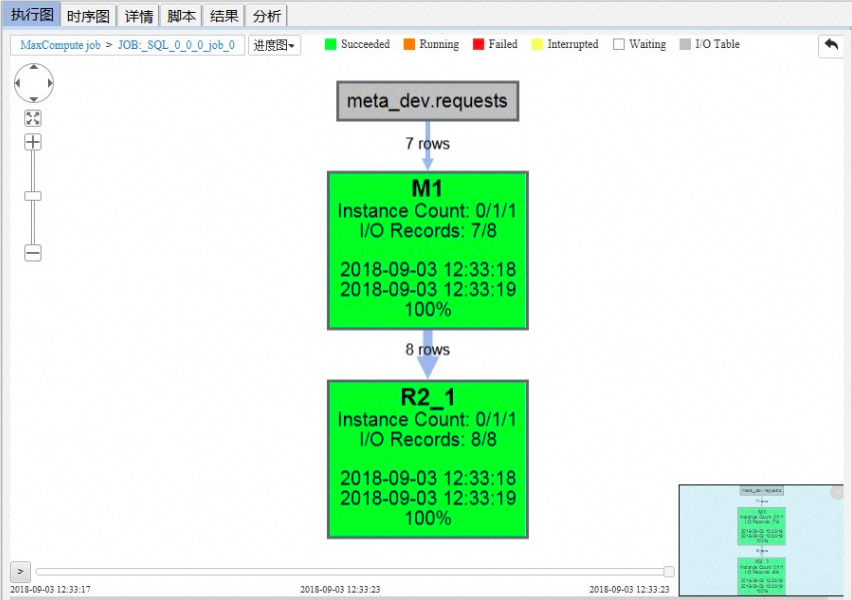
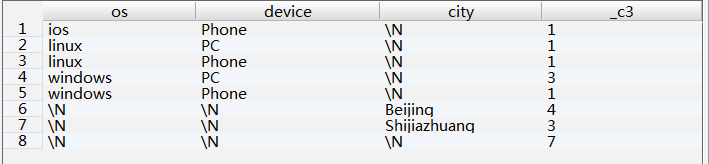
- 两种方法均产生相同的结果,如下所示:
请注意:
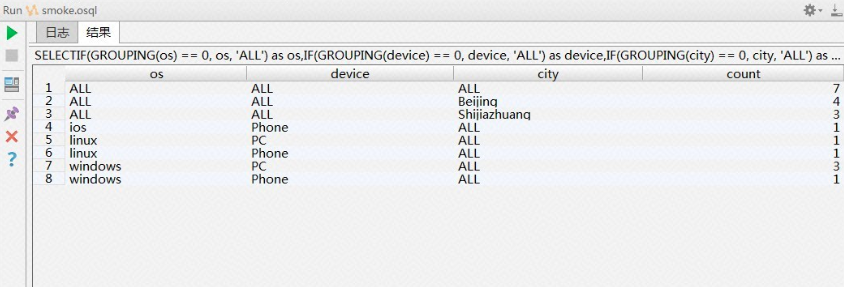
- 若分组集里不使用表达式,系统会使用NULL充当占位符,使得这些结果集可以做UNION操作。例如,结果第 1-5 行的city列。
- 相比于UNION多个group by的实现,GROUPINGSETS方式在总的资源消耗上面占优的。但使用GROUPINGSETS会使Reducer的阶段变少,如上例,从3个(R2_1, R3_1, R4_1)变为1个(R2_1), 从而导致总的Reducer instance数变少,可能会使任务端到端时间变长。
这种情况建议使用odps.sql.reducer.instances手动调大reducer的instance数目。例如上面的示例,可以set odps.sql.reducer.instances=3;来保持和原来instance数不变。
CUBE and ROLLUP
CUBE和ROLLUP可以认为是特殊的GROUPING SETS。
CUBE会枚举指定列的所有可能组合作为GROUPING SETS。而ROLLUP会以按层级聚合的方式产生GROUPING SETS。
例如:
GROUP BY CUBE(a, b, c)等价于GROUPING SETS( (a,b,c), (a,b), (a,c), (b,c), (a) ,(b), (c), () )。GROUP BY ROLLUP(a,b,c)等价于GROUPING SETS( (a,b,c), (a,b), (a), () )。
CUBE会把GROUP BY列进行全量组合,即N个列会产生 2^N中组合,故不建议N的数目超过5。
GROUPING() and GROUPING_ID()
前面提到,系统在GROUPING SETS结果中用 NULL 用作占位符,当出现此情况后,将无法区分占位符 NULL 与数据中真正的 NULL,针对这个问题,MaxCompute提供了GROUPING 函数。
GROUPING 函数接受一个列名作为参数,如果结果对应行使用了参数列做聚合,返回0,此时意味着NULL来自输入数据。否则返回1,此时意味着NULL是GROUPING SETS的占位符。
此外,MaxCompute还提供了GROUPING_ID函数,此函数接受1个或多个列名作为参数。结果是将参数列的GROUPING结果按照BitMap的方式组成整数。如:
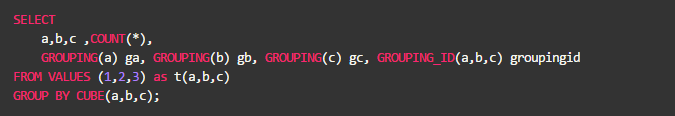
结果:
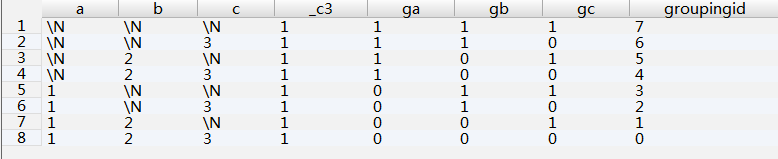
默认情况,GROUP BY列表中不被使用的列,会被填充为NULL。我们可以通过GROUPING函数输出更有实际意义的值。如:
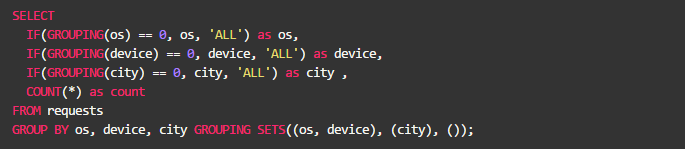
输出结果:
注意事项
CUBE会把GROUP BY列进行全量组合,即N个列会产生 2^N中组合,目前我们设置了GROUP BY列上限为13个。
小节
GROUPING SETS扩充了GROUP BY的聚合功能,在易用性,兼容性和性能方面,可以更好的满足您的需求。
对于SQL比较熟悉的专家会发现,上述功能大部分是标准的SQL支持的功能。MaxCompute会持续提升与标准SQL和业界常用产品的兼容性。
本文作者:海清
本文为阿里云内容,未经允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号