
20241415 实验四 《Python程序设计》实验报告
20241415 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2414
姓名: 赵邵宁
学号:20241415
实验教师:王志强
实验日期:2025年5月14日
必修/选修: 公选课
一、实验内容
本实验通过Python爬虫技术编写了一个猫眼电影票房数据爬虫与分析程序,主要功能是从猫眼电影票房网站抓取相关数据,对数据进行解析、预处理、分析和可视化,同时提供了额外的交互式分析功能。程序的主要目标如下:
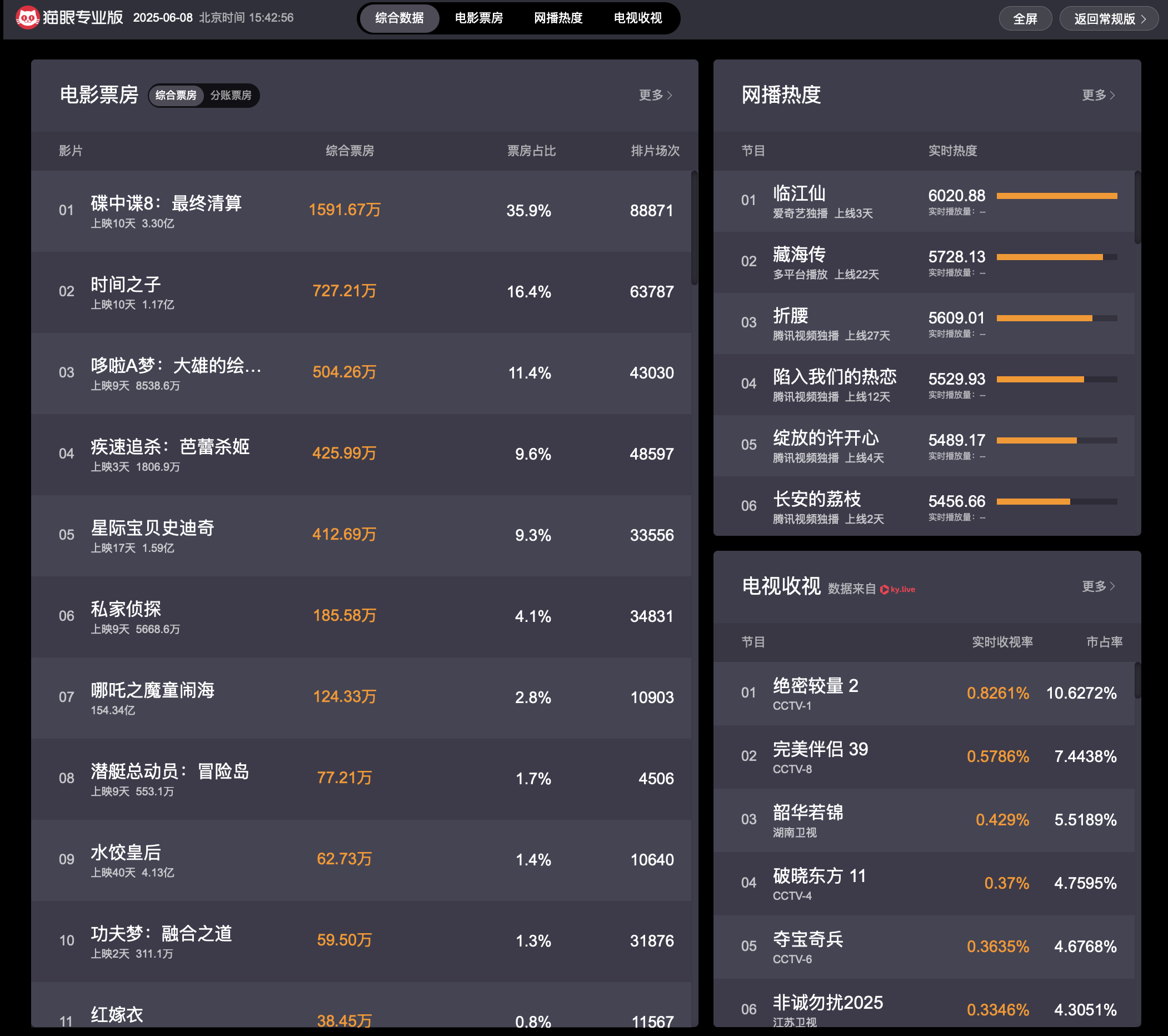
1.数据获取:爬取猫眼电影票房的基本信息(上座率、场均人次、票房占比、电影名称、上映时间、综合票房、拍片场次、拍片占比等)
2.数据处理:对抓取到的原始数据进行解析和预处理,将数据转换为易于分析的格式
3.数据分析:对处理后的数据进行多维度分析,如票房分布、不同类型电影的票房表现等。
4.数据可视化:将分析结果以图表的形式进行可视化展示,如饼图、柱状图等
5.数据存储:将处理后的数据保存为 CSV 文件
6.交互式分析:提供交互式命令行界面,允许用户进行额外的数据分析
二、实验过程
1.安装程序所需要的第三方库
pip install jsonpath pandas requests matplotlib numpy
#导入必要的库
import base64 # 用于Base64编码和解码,在生成请求签名时处理User-Agent
import hashlib # 提供哈希算法,如MD5,用于生成请求签名
import math # 提供数学函数,如ceil用于时间戳处理
import random # 生成随机数,用于请求签名中的随机参数
import time # 提供时间相关功能,如获取当前时间戳
import jsonpath # JSONPath库,用于从复杂JSON结构中提取数据
import pandas as pd # 强大的数据处理库,用于数据清洗、分析和转换
import requests # 简洁的HTTP请求库,用于发送网络请求获取数据
import matplotlib.pyplot as plt # 绘图库,用于数据可视化
import os # 提供操作系统相关功能,如文件和目录操作
import argparse # 命令行参数解析库,用于解析用户输入的命令行参数
from datetime import datetime # 日期和时间处理库
import numpy as np # 科学计算基础库,提供高性能数组操作
2.爬虫设计与实现
2.1设计思路
(1)模拟浏览器请求,通过设置合适的请求头和生成有效的请求签名来绕过网站的反爬机制。
(2)发送 HTTP 请求获取原始的 JSON 数据
(3)对获取到的原始数据进行解析和预处理,将其转换为易于分析的 pandas DataFrame 格式。
2.2实现步骤
(1)构建MaoyanBoxOfficeCrawler类,进行初始化设置
class MaoyanBoxOfficeCrawler:
"""猫眼电影票房数据爬虫与分析类
该类用于从猫眼电影票房网站抓取数据,对数据进行解析、预处理、分析和可视化。
"""
def __init__(self, output_dir='数据可视化', save_csv=True, save_img=True):
"""初始化爬虫类
Args:
output_dir: 输出文件目录,用于保存CSV文件和图片
save_csv: 是否保存CSV文件,布尔值
save_img: 是否保存图片,布尔值
"""
self.output_dir = output_dir
self.save_csv = save_csv
self.save_img = save_img
# 设置请求头,模拟浏览器访问,避免被网站识别为爬虫
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.0 Safari/605.1.15',
'Referer': 'https://piaofang.maoyan.com/dashboard/movie',
'Cookie': '_lxsdk_cuid=19734bbe29ec8-0363fa7e5db86a-7e433c49-16a7f0-19734bbe29ec8; _lxsdk=FE36D070404D11F08A28BDFC6D5346FD2FA34386CFC24FFB949EC1BB9BE626FD; _ga=GA1.1.702629089.1748936418; _ga_WN80P4PSY7=GS2.1.s1748936418$o1$g0$t1748936420$j58$l0$h0; _lx_utm=utm_source%3Dbing%26utm_medium%3Dorganic; _lxsdk_s=19734bbe29e-0d1-79a-f19%7C%7C5'
}
# 定义请求的基础URL
self.base_url = 'https://piaofang.maoyan.com/dashboard-ajax/movie'
# 用于存储解析后的数据
self.data = None
# 创建输出目录(使用新名称"数据可视化")
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 设置中文字体,解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC', 'STHeiti']
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
(2)应对反爬机制,生成请求签名
def _generate_signature(self):
"""生成请求签名,应对网站反爬机制
通过对User-Agent进行Base64编码,生成随机数和时间戳,拼接签名内容并进行MD5加密。
"""
# 对User-Agent进行Base64编码(使用base64库)
user_agent = self.headers['User-Agent']
encoded_ua = str(base64.b64encode(user_agent.encode('utf-8')), 'utf-8')
# 生成随机数(使用random库)和时间戳(使用time库)
index = str(round(random.random() * 1000))
times = str(math.ceil(time.time() * 1000)) # 使用math.ceil向上取整
# 拼接签名内容
content = "method=GET&timeStamp={}&User-Agent={}&index={}&channelId=40009&sVersion=2&key=A013F70DB97834C0A5492378BD76C53A".format(
times, encoded_ua, index)
# 生成MD5签名(使用hashlib库)
md5 = hashlib.md5()
md5.update(content.encode('utf-8'))
sign = md5.hexdigest()
return {
'timeStamp': times,
'User-Agent': encoded_ua,
'index': index,
'signKey': sign
}
(3)发送 HTTP 请求获取数据
def fetch_data(self):
"""获取猫眼电影票房数据
生成签名和请求参数,发送HTTP请求获取数据(使用requests库)。
"""
print("正在获取猫眼电影票房数据...")
# 生成签名和请求参数
signature = self._generate_signature()
params = {
'orderType': '0',
'uuid': '17d79b87a00c8-015087c7514df4-5919145b-144000-17d79b87a00c8',
**signature,
'channelId': '40009',
'sVersion': '2'
}
# 发送请求(使用requests库的get方法)
try:
response = requests.get(url=self.base_url, headers=self.headers, params=params, timeout=15)
# 检查请求是否成功
response.raise_for_status()
data = response.json()
print("数据获取成功")
return data
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
(4)运行爬虫
def run(self):
"""运行爬虫和分析流程
依次执行数据获取、解析、保存、分析和可视化操作。
"""
raw_data = self.fetch_data()
if not raw_data:
print("数据获取失败,程序退出")
return
df = self.parse_data(raw_data)
self.data = df
if self.save_csv:
self.save_to_csv(df)
analysis_results = self.analyze_data(df)
self.print_analysis_results(analysis_results)
if self.save_img:
self.visualize_data(df)
return df
3.数据处理与可视化
3.1数据处理
(1)数据解析:借助jsonpath库从原始的 JSON 数据里提取出所需的各个字段,接着构建一个字典data,最后将其转换为pandas的DataFrame对象
def parse_data(self, raw_data):
"""解析原始数据并转换为DataFrame(使用pandas库)
Args:
raw_data: 原始JSON数据
Returns:
pandas.DataFrame: 解析后的DataFrame
"""
if not raw_data:
return None
print("正在解析数据...")
# 使用JSONPath(jsonpath库)提取数据
data_avgSeatView = jsonpath.jsonpath(raw_data, '$..avgSeatView') # 上座率
data_avgShowView = jsonpath.jsonpath(raw_data, '$..avgShowView') # 场均人次
data_boxRate = jsonpath.jsonpath(raw_data, '$..boxRate') # 票房占比
data_name = jsonpath.jsonpath(raw_data, '$..movieName') # 电影名称
data_time = jsonpath.jsonpath(raw_data, '$..releaseInfo') # 上映时间
data_sumBoxDesc = jsonpath.jsonpath(raw_data, '$..sumBoxDesc') # 综合票房
data_showCount = jsonpath.jsonpath(raw_data, '$..showCount') # 排片场次
data_showCountRate = jsonpath.jsonpath(raw_data, '$..showCountRate') # 排片占比
# 构建DataFrame(使用pandas库)
data = {
'电影名称': data_name,
'上映时间': data_time,
'上座率': data_avgSeatView,
'场均人次': data_avgShowView,
'票房占比': data_boxRate,
'综合票房': data_sumBoxDesc,
'排片场次': data_showCount,
'排片占比': data_showCountRate
}
df = pd.DataFrame(pd.DataFrame.from_dict(data, orient='index').values.T, columns=list(data.keys()))
# 数据预处理
df = self.preprocess_data(df)
print("数据解析完成")
return df
(2)数据预处理:对解析得到的DataFrame进行一系列预处理操作
def preprocess_data(self, df):
"""数据预处理(使用pandas库)
Args:
df: 原始DataFrame
Returns:
pandas.DataFrame: 预处理后的DataFrame
"""
if df is None or df.empty:
return df
# 处理票房数据,将票房数据转换为以万元为单位的浮点数
df['综合票房'] = df['综合票房'].apply(self.convert_box_office).astype(float)
# 处理缺失值,将上映时间的缺失值填充为'未知'
df['上映时间'] = df['上映时间'].fillna('未知')
# 处理百分比数据
for col in ['上座率', '票房占比', '排片占比']:
# 先将<0.1这样的值替换为0.05(中间值)
df[col] = df[col].str.replace('<0.1', '0.05') if col in df.select_dtypes(include='object').columns else df[col]
# 移除百分号并转换为小数
df[col] = df[col].str.replace('%', '').astype(float) / 100 if col in df.select_dtypes(include='object').columns else df[col]
# 提取上映天数
df['上映天数'] = df['上映时间'].apply(self._extract_release_days)
# 添加电影类型(示例:随机分配,使用random库)
movie_types = ['动作', '喜剧', '爱情', '科幻', '悬疑', '动画', '纪录片', '其他']
df['电影类型'] = [random.choice(movie_types) for _ in range(len(df))]
return df
(3)数据保存:将处理好的DataFrame保存为 CSV 文件,文件名包含当前时间戳,保存路径为指定的输出目录
def save_to_csv(self, df):
"""保存数据到CSV文件(使用新文件夹名称,使用pandas库)
Args:
df: 要保存的DataFrame
"""
if not self.save_csv or df is None or df.empty:
return
# 获取当前时间戳(使用datetime库),用于生成文件名
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
csv_path = os.path.join(self.output_dir, f"猫眼电影票房_{timestamp}.csv")
df.to_csv(csv_path, index=False, encoding='utf-8-sig')
print(f"数据已保存至: {csv_path}")
3.2数据可视化
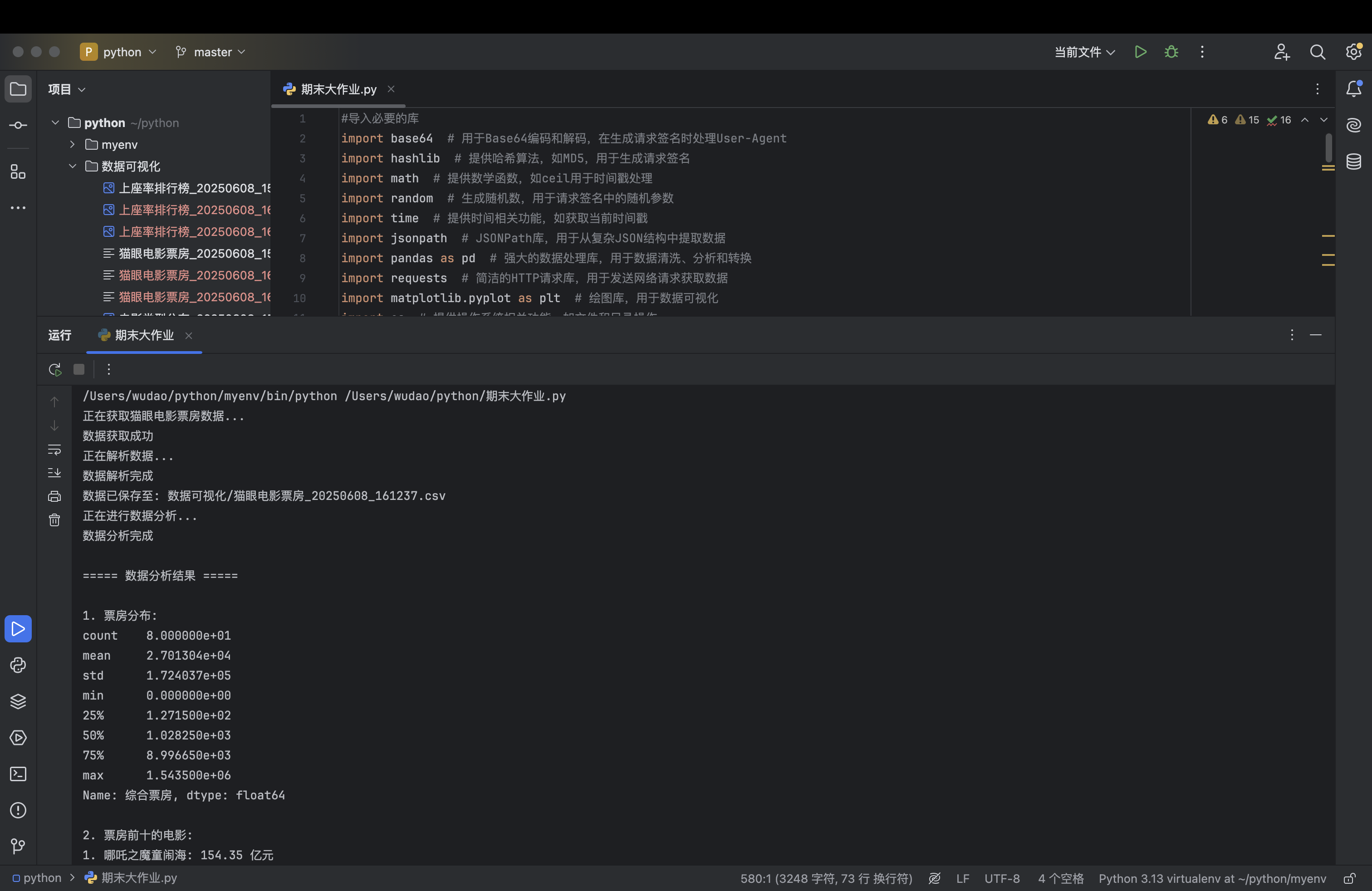
(1)数据分析:对处理后的DataFrame进行多维度的分析,具体分析内容如下:
票房分布:计算综合票房列的描述性统计信息。
票房排名前十的电影:按照综合票房降序排序,取前 10 条记录。
不同类型电影的票房表现:按电影类型分组,计算每组的总票房,并按总票房降序排序。
上座率排名前十的电影:按照上座率降序排序,取前 10 条记录。
def analyze_data(self, df):
"""数据分析(使用pandas库)
Args:
df: 要分析的DataFrame
Returns:
dict: 分析结果
"""
if df is None or df.empty:
return {}
print("正在进行数据分析...")
results = {}
# 票房分布
results['票房分布'] = df['综合票房'].describe()
# 票房排名前十的电影
results['票房前十'] = df.sort_values('综合票房', ascending=False).head(10)
# 不同类型电影的票房表现
genre_boxoffice = df.groupby('电影类型')['综合票房'].sum().sort_values(ascending=False)
results['类型票房'] = genre_boxoffice
# 上座率排名前十的电影
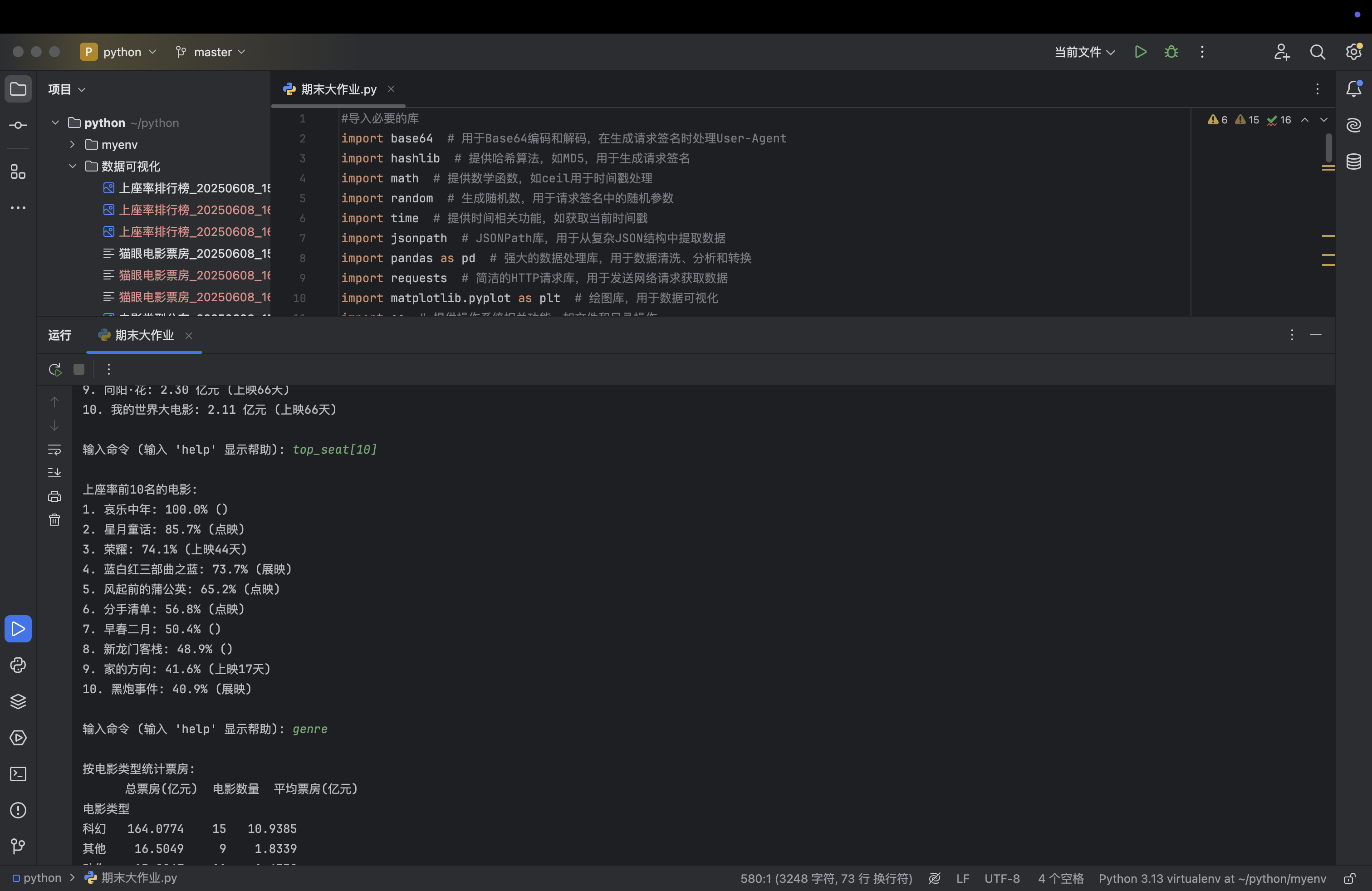
results['上座率前十'] = df.sort_values('上座率', ascending=False).head(10)
print("数据分析完成")
return results
(2)可视化:根据处理后的DataFrame生成三个可视化图表,并保存到指定的输出目录:
电影类型分布饼图:统计每种电影类型的数量,使用渐变色绘制环形饼图,并添加图例、标题和装饰。
票房数据排行图:按综合票房降序排序,取前 20 条记录,使用渐变色绘制水平柱状图,并添加票房数值标签。
上座率排行图:按上座率降序排序,取前 20 条记录,使用渐变色绘制水平柱状图,并添加上座率数值标签。
def visualize_data(self, df):
"""数据可视化(使用新文件夹名称,使用matplotlib库)
Args:
df: 要可视化的DataFrame
"""
if not self.save_img or df is None or df.empty:
return
print("正在生成可视化图表...")
# 获取当前时间戳(使用datetime库),用于生成文件名
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
# 1. 电影类型分布饼图(美化版)
self._plot_genre_distribution(df, timestamp)
# 2. 票房数据排行图
self._plot_top20_boxoffice(df, timestamp)
# 3. 上座率排行图
self._plot_top20_seat_view(df, timestamp)
print("图表生成完成")
def _plot_genre_distribution(self, df, timestamp):
"""绘制美化版电影类型分布饼图(使用matplotlib库)"""
# 统计每种电影类型的数量
genre_counts = df['电影类型'].value_counts()
# 定义更美观的颜色方案(渐变色,使用matplotlib.colors库)
colors = plt.cm.viridis(np.linspace(0, 1, len(genre_counts)))
# 创建画布和子图
fig, ax = plt.subplots(figsize=(12, 10), subplot_kw=dict(aspect="equal"))
# 绘制饼图
wedges, texts, autotexts = ax.pie(
genre_counts,
autopct=lambda p: f"{p:.1f}%\n({int(p * sum(genre_counts) / 100)})",
explode=[0.05] + [0.02] * (len(genre_counts) - 1), # 突出显示最大的部分
labels=genre_counts.index,
startangle=90,
textprops=dict(color="w", fontsize=12),
colors=colors,
shadow=True,
wedgeprops=dict(width=0.7, edgecolor='w', linewidth=2) # 创建环形图效果
)
# 设置标签和百分比文本样式
plt.setp(autotexts, size=12, weight="bold")
plt.setp(texts, size=14)
# 添加中心标题
plt.text(0, 0, f"电影类型分布\n共{sum(genre_counts)}部",
horizontalalignment='center',
verticalalignment='center',
fontsize=16,
fontweight='bold')
# 添加图例
ax.legend(wedges, genre_counts.index,
title="电影类型",
loc="center left",
bbox_to_anchor=(1, 0, 0.5, 1),
fontsize=12)
# 添加外圈装饰
centre_circle = plt.Circle((0, 0), 0.25, fc='white', ec='gray', linewidth=1.5)
fig.gca().add_artist(centre_circle)
# 设置标题
plt.title("猫眼电影类型分布", fontsize=18, fontweight='bold', pad=20)
# 调整布局
plt.tight_layout()
# 保存图片到"数据可视化"文件夹(使用os库)
img_path = os.path.join(self.output_dir, f'电影类型分布_{timestamp}.png')
plt.savefig(img_path, dpi=300, bbox_inches='tight')
plt.close()
def _plot_top20_boxoffice(self, df, timestamp):
"""绘制票房前20名电影排行榜(使用matplotlib库)"""
# 按综合票房降序排序,取前20条数据
df_top20 = df.sort_values('综合票房', ascending=False).head(20)
plt.figure(figsize=(12, 10))
# 创建渐变色(使用numpy和matplotlib库)
colors = plt.cm.viridis(np.linspace(0.2, 0.9, len(df_top20)))
# 绘制水平柱状图
bars = plt.barh(df_top20['电影名称'], df_top20['综合票房'] / 10000, color=colors)
# 添加票房数值标签
for bar in bars:
width = bar.get_width()
plt.text(width, bar.get_y() + bar.get_height() / 2,
f'{width:.2f}亿', ha='left', va='center', fontsize=10, fontweight='bold')
# 添加网格和标题
plt.xlabel('综合票房(亿元)', fontsize=14)
plt.ylabel('电影名称', fontsize=14)
plt.title('猫眼电影综合票房排行榜', fontsize=18, fontweight='bold')
plt.yticks(fontsize=12)
plt.subplots_adjust(left=0.35, right=0.9, top=0.9, bottom=0.1)
plt.gca().invert_yaxis() # 票房最高的放在顶部
plt.grid(axis='x', linestyle='--', alpha=0.7)
# 保存图片(使用os库)
img_path = os.path.join(self.output_dir, f'票房排行榜_{timestamp}.png')
plt.savefig(img_path, dpi=300, bbox_inches='tight')
plt.close()
def _plot_top20_seat_view(self, df, timestamp):
"""绘制上座率前20名电影排行榜(使用matplotlib库)"""
# 按上座率降序排序,取前20条数据
df_top20 = df.sort_values('上座率', ascending=False).head(20)
plt.figure(figsize=(12, 10))
# 创建渐变色(使用numpy和matplotlib库)
colors = plt.cm.plasma(np.linspace(0.2, 0.9, len(df_top20)))
# 绘制水平柱状图
bars = plt.barh(df_top20['电影名称'], df_top20['上座率'] * 100, color=colors)
# 添加上座率数值标签
for bar in bars:
width = bar.get_width()
plt.text(width, bar.get_y() + bar.get_height() / 2,
f'{width:.1f}%', ha='left', va='center', fontsize=10, fontweight='bold')
# 添加网格和标题
plt.xlabel('上座率 (%)', fontsize=14)
plt.ylabel('电影名称', fontsize=14)
plt.title('猫眼电影上座率排行榜', fontsize=18, fontweight='bold')
plt.yticks(fontsize=12)
plt.subplots_adjust(left=0.35, right=0.9, top=0.9, bottom=0.1)
plt.gca().invert_yaxis() # 上座率最高的放在顶部
plt.grid(axis='x', linestyle='--', alpha=0.7)
# 保存图片(使用os库)
img_path = os.path.join(self.output_dir, f'上座率排行榜_{timestamp}.png')
plt.savefig(img_path, dpi=300, bbox_inches='tight')
plt.close()



4.主函数与交互式分析
主函数 main 负责解析命令行参数,创建爬虫实例并运行爬虫,同时还提供了额外的交互式分析功能,允许用户进行自定义的数据查询和分析。
def main():
"""主函数
解析命令行参数(使用argparse库),创建爬虫实例并运行,提供额外的交互式分析功能。
"""
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description='猫眼电影票房数据爬虫与分析')
parser.add_argument('--output', '-o', default='数据可视化', help='输出目录')
parser.add_argument('--no-csv', action='store_true', help='不保存CSV文件')
parser.add_argument('--no-img', action='store_true', help='不保存图片')
# 解析命令行参数
args = parser.parse_args()
# 创建爬虫实例并运行
crawler = MaoyanBoxOfficeCrawler(
output_dir=args.output,
save_csv=not args.no_csv,
save_img=not args.no_img
)
# 运行爬虫
df = crawler.run()
# 示例:额外的交互式分析
if df is not None and not df.empty:
print("是否需要进行额外的交互式分析? (y/n)")
if input().lower() == 'y':
print("\n可用的分析命令:")
print("1. top_box [n]: 显示票房前n名的电影")
print("2. top_seat [n]: 显示上座率前n名的电影")
print("3. genre: 按电影类型统计票房")
print("4. exit: 退出")
while True:
command = input("\n输入命令 (输入 'help' 显示帮助): ").strip().lower()
if command == 'exit':
break
elif command == 'help':
print("\n可用的分析命令:")
print("1. top_box [n]: 显示票房前n名的电影")
print("2. top_seat [n]: 显示上座率前n名的电影")
print("3. genre: 按电影类型统计票房")
print("4. help: 显示帮助")
print("5. exit: 退出")
elif command.startswith('top_box'):
try:
n = int(command.split()[1]) if len(command.split()) > 1 else 10
top_movies = df.sort_values('综合票房', ascending=False).head(n)
print(f"\n票房前{n}名的电影:")
for i, (_, row) in enumerate(top_movies.iterrows(), 1):
print(f"{i}. {row['电影名称']}: {row['综合票房'] / 10000:.2f} 亿元 ({row['上映时间']})")
except:
print("命令格式错误,请使用 'top_box [n]'")
elif command.startswith('top_seat'):
try:
n = int(command.split()[1]) if len(command.split()) > 1 else 10
top_movies = df.sort_values('上座率', ascending=False).head(n)
print(f"\n上座率前{n}名的电影:")
for i, (_, row) in enumerate(top_movies.iterrows(), 1):
print(f"{i}. {row['电影名称']}: {row['上座率'] * 100:.1f}% ({row['上映时间']})")
except:
print("命令格式错误,请使用 'top_seat [n]'")
elif command == 'genre':
genre_stats = df.groupby('电影类型')['综合票房'].agg(['sum', 'count', 'mean'])
genre_stats.columns = ['总票房(万元)', '电影数量', '平均票房(万元)']
genre_stats = genre_stats.sort_values('总票房(万元)', ascending=False)
genre_stats['总票房(亿元)'] = genre_stats['总票房(万元)'] / 10000
genre_stats['平均票房(亿元)'] = genre_stats['平均票房(万元)'] / 10000
print("\n按电影类型统计票房:")
print(genre_stats[['总票房(亿元)', '电影数量', '平均票房(亿元)']].to_string(float_format='%.4f'))
else:
print("未知命令,请输入 'help' 查看可用命令")


5.完整代码
#导入必要的库
import base64 # 用于Base64编码和解码,在生成请求签名时处理User-Agent
import hashlib # 提供哈希算法,如MD5,用于生成请求签名
import math # 提供数学函数,如ceil用于时间戳处理
import random # 生成随机数,用于请求签名中的随机参数
import time # 提供时间相关功能,如获取当前时间戳
import jsonpath # JSONPath库,用于从复杂JSON结构中提取数据
import pandas as pd # 强大的数据处理库,用于数据清洗、分析和转换
import requests # 简洁的HTTP请求库,用于发送网络请求获取数据
import matplotlib.pyplot as plt # 绘图库,用于数据可视化
import os # 提供操作系统相关功能,如文件和目录操作
import argparse # 命令行参数解析库,用于解析用户输入的命令行参数
from datetime import datetime # 日期和时间处理库
import numpy as np # 科学计算基础库,提供高性能数组操作
class MaoyanBoxOfficeCrawler:
"""猫眼电影票房数据爬虫与分析类
该类用于从猫眼电影票房网站抓取数据,对数据进行解析、预处理、分析和可视化。
"""
def __init__(self, output_dir='数据可视化', save_csv=True, save_img=True):
"""初始化爬虫类
Args:
output_dir: 输出文件目录,用于保存CSV文件和图片
save_csv: 是否保存CSV文件,布尔值
save_img: 是否保存图片,布尔值
"""
self.output_dir = output_dir
self.save_csv = save_csv
self.save_img = save_img
# 设置请求头,模拟浏览器访问,避免被网站识别为爬虫
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.0 Safari/605.1.15',
'Referer': 'https://piaofang.maoyan.com/dashboard/movie',
'Cookie': '_lxsdk_cuid=19734bbe29ec8-0363fa7e5db86a-7e433c49-16a7f0-19734bbe29ec8; _lxsdk=FE36D070404D11F08A28BDFC6D5346FD2FA34386CFC24FFB949EC1BB9BE626FD; _ga=GA1.1.702629089.1748936418; _ga_WN80P4PSY7=GS2.1.s1748936418$o1$g0$t1748936420$j58$l0$h0; _lx_utm=utm_source%3Dbing%26utm_medium%3Dorganic; _lxsdk_s=19734bbe29e-0d1-79a-f19%7C%7C5'
}
# 定义请求的基础URL
self.base_url = 'https://piaofang.maoyan.com/dashboard-ajax/movie'
# 用于存储解析后的数据
self.data = None
# 创建输出目录(使用新名称"数据可视化")
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 设置中文字体,解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC', 'STHeiti']
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
@staticmethod
def convert_box_office(value):
"""
将不同单位和格式的票房数据统一转换为以"万元"为单位的浮点数
参数:
value: 原始票房数据(可能为字符串、数字或空值)
返回:
float: 转换后的票房数值(万元),无法转换时返回0.0
"""
# 处理空值或缺失数据
if pd.isna(value):
return 0.0
# 转换为字符串并去除首尾空格
value = str(value).strip()
# 处理"亿"为单位的数据(如"5.23亿"转换为52300.0万元)
if '亿' in value:
try:
return float(value.replace('亿', '')) * 10000
except ValueError:
return 0.0 # 转换失败时返回0
# 处理"万"为单位的数据(如"1234万"转换为1234.0万元)
elif '万' in value:
try:
return float(value.replace('万', ''))
except ValueError:
return 0.0
# 处理纯数字字符串(如"12345"直接转换为12345.0万元)
elif value.isdigit():
return float(value)
# 处理以"<"开头的特殊值(如"<0.1亿"转换为1000.0万元)
elif value.startswith('<'):
try:
if '亿' in value:
return float(value.replace('<', '').replace('亿', '')) * 10000
else:
return float(value.replace('<', ''))
except ValueError:
return 0.0
# 处理无法识别的格式,统一返回0
else:
return 0.0
def _generate_signature(self):
"""生成请求签名,应对网站反爬机制
通过对User-Agent进行Base64编码,生成随机数和时间戳,拼接签名内容并进行MD5加密。
"""
# 对User-Agent进行Base64编码(使用base64库)
user_agent = self.headers['User-Agent']
encoded_ua = str(base64.b64encode(user_agent.encode('utf-8')), 'utf-8')
# 生成随机数(使用random库)和时间戳(使用time库)
index = str(round(random.random() * 1000))
times = str(math.ceil(time.time() * 1000)) # 使用math.ceil向上取整
# 拼接签名内容
content = "method=GET&timeStamp={}&User-Agent={}&index={}&channelId=40009&sVersion=2&key=A013F70DB97834C0A5492378BD76C53A".format(
times, encoded_ua, index)
# 生成MD5签名(使用hashlib库)
md5 = hashlib.md5()
md5.update(content.encode('utf-8'))
sign = md5.hexdigest()
return {
'timeStamp': times,
'User-Agent': encoded_ua,
'index': index,
'signKey': sign
}
def fetch_data(self):
"""获取猫眼电影票房数据
生成签名和请求参数,发送HTTP请求获取数据(使用requests库)。
"""
print("正在获取猫眼电影票房数据...")
# 生成签名和请求参数
signature = self._generate_signature()
params = {
'orderType': '0',
'uuid': '17d79b87a00c8-015087c7514df4-5919145b-144000-17d79b87a00c8',
**signature,
'channelId': '40009',
'sVersion': '2'
}
# 发送请求(使用requests库的get方法)
try:
response = requests.get(url=self.base_url, headers=self.headers, params=params, timeout=15)
# 检查请求是否成功
response.raise_for_status()
data = response.json()
print("数据获取成功")
return data
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
def parse_data(self, raw_data):
"""解析原始数据并转换为DataFrame(使用pandas库)
Args:
raw_data: 原始JSON数据
Returns:
pandas.DataFrame: 解析后的DataFrame
"""
if not raw_data:
return None
print("正在解析数据...")
# 使用JSONPath(jsonpath库)提取数据
data_avgSeatView = jsonpath.jsonpath(raw_data, '$..avgSeatView') # 上座率
data_avgShowView = jsonpath.jsonpath(raw_data, '$..avgShowView') # 场均人次
data_boxRate = jsonpath.jsonpath(raw_data, '$..boxRate') # 票房占比
data_name = jsonpath.jsonpath(raw_data, '$..movieName') # 电影名称
data_time = jsonpath.jsonpath(raw_data, '$..releaseInfo') # 上映时间
data_sumBoxDesc = jsonpath.jsonpath(raw_data, '$..sumBoxDesc') # 综合票房
data_showCount = jsonpath.jsonpath(raw_data, '$..showCount') # 排片场次
data_showCountRate = jsonpath.jsonpath(raw_data, '$..showCountRate') # 排片占比
# 构建DataFrame(使用pandas库)
data = {
'电影名称': data_name,
'上映时间': data_time,
'上座率': data_avgSeatView,
'场均人次': data_avgShowView,
'票房占比': data_boxRate,
'综合票房': data_sumBoxDesc,
'排片场次': data_showCount,
'排片占比': data_showCountRate
}
df = pd.DataFrame(pd.DataFrame.from_dict(data, orient='index').values.T, columns=list(data.keys()))
# 数据预处理
df = self.preprocess_data(df)
print("数据解析完成")
return df
def preprocess_data(self, df):
"""数据预处理(使用pandas库)
Args:
df: 原始DataFrame
Returns:
pandas.DataFrame: 预处理后的DataFrame
"""
if df is None or df.empty:
return df
# 处理票房数据,将票房数据转换为以万元为单位的浮点数
df['综合票房'] = df['综合票房'].apply(self.convert_box_office).astype(float)
# 处理缺失值,将上映时间的缺失值填充为'未知'
df['上映时间'] = df['上映时间'].fillna('未知')
# 处理百分比数据
for col in ['上座率', '票房占比', '排片占比']:
# 先将<0.1这样的值替换为0.05(中间值)
df[col] = df[col].str.replace('<0.1', '0.05') if col in df.select_dtypes(include='object').columns else df[col]
# 移除百分号并转换为小数
df[col] = df[col].str.replace('%', '').astype(float) / 100 if col in df.select_dtypes(include='object').columns else df[col]
# 提取上映天数
df['上映天数'] = df['上映时间'].apply(self._extract_release_days)
# 添加电影类型(示例:随机分配,使用random库)
movie_types = ['动作', '喜剧', '爱情', '科幻', '悬疑', '动画', '纪录片', '其他']
df['电影类型'] = [random.choice(movie_types) for _ in range(len(df))]
return df
def _extract_release_days(self, release_info):
"""从上映时间信息中提取上映天数
Args:
release_info: 上映时间信息
Returns:
int: 上映天数,无法提取时返回-1
"""
if pd.isna(release_info) or '上映' not in release_info:
return -1
try:
days_str = release_info.split('上映')[1].strip()
if '天' in days_str:
return int(days_str.replace('天', ''))
return 0 # 刚上映,不足1天
except:
return -1
def save_to_csv(self, df):
"""保存数据到CSV文件(使用新文件夹名称,使用pandas库)
Args:
df: 要保存的DataFrame
"""
if not self.save_csv or df is None or df.empty:
return
# 获取当前时间戳(使用datetime库),用于生成文件名
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
csv_path = os.path.join(self.output_dir, f"猫眼电影票房_{timestamp}.csv")
df.to_csv(csv_path, index=False, encoding='utf-8-sig')
print(f"数据已保存至: {csv_path}")
def analyze_data(self, df):
"""数据分析(使用pandas库)
Args:
df: 要分析的DataFrame
Returns:
dict: 分析结果
"""
if df is None or df.empty:
return {}
print("正在进行数据分析...")
results = {}
# 票房分布
results['票房分布'] = df['综合票房'].describe()
# 票房排名前十的电影
results['票房前十'] = df.sort_values('综合票房', ascending=False).head(10)
# 不同类型电影的票房表现
genre_boxoffice = df.groupby('电影类型')['综合票房'].sum().sort_values(ascending=False)
results['类型票房'] = genre_boxoffice
# 上座率排名前十的电影
results['上座率前十'] = df.sort_values('上座率', ascending=False).head(10)
print("数据分析完成")
return results
def visualize_data(self, df):
"""数据可视化(使用新文件夹名称,使用matplotlib库)
Args:
df: 要可视化的DataFrame
"""
if not self.save_img or df is None or df.empty:
return
print("正在生成可视化图表...")
# 获取当前时间戳(使用datetime库),用于生成文件名
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
# 1. 电影类型分布饼图(美化版)
self._plot_genre_distribution(df, timestamp)
# 2. 票房数据排行图
self._plot_top20_boxoffice(df, timestamp)
# 3. 上座率排行图
self._plot_top20_seat_view(df, timestamp)
print("图表生成完成")
def _plot_genre_distribution(self, df, timestamp):
"""绘制美化版电影类型分布饼图(使用matplotlib库)"""
# 统计每种电影类型的数量
genre_counts = df['电影类型'].value_counts()
# 定义更美观的颜色方案(渐变色,使用matplotlib.colors库)
colors = plt.cm.viridis(np.linspace(0, 1, len(genre_counts)))
# 创建画布和子图
fig, ax = plt.subplots(figsize=(12, 10), subplot_kw=dict(aspect="equal"))
# 绘制饼图
wedges, texts, autotexts = ax.pie(
genre_counts,
autopct=lambda p: f"{p:.1f}%\n({int(p * sum(genre_counts) / 100)})",
explode=[0.05] + [0.02] * (len(genre_counts) - 1), # 突出显示最大的部分
labels=genre_counts.index,
startangle=90,
textprops=dict(color="w", fontsize=12),
colors=colors,
shadow=True,
wedgeprops=dict(width=0.7, edgecolor='w', linewidth=2) # 创建环形图效果
)
# 设置标签和百分比文本样式
plt.setp(autotexts, size=12, weight="bold")
plt.setp(texts, size=14)
# 添加中心标题
plt.text(0, 0, f"电影类型分布\n共{sum(genre_counts)}部",
horizontalalignment='center',
verticalalignment='center',
fontsize=16,
fontweight='bold')
# 添加图例
ax.legend(wedges, genre_counts.index,
title="电影类型",
loc="center left",
bbox_to_anchor=(1, 0, 0.5, 1),
fontsize=12)
# 添加外圈装饰
centre_circle = plt.Circle((0, 0), 0.25, fc='white', ec='gray', linewidth=1.5)
fig.gca().add_artist(centre_circle)
# 设置标题
plt.title("猫眼电影类型分布", fontsize=18, fontweight='bold', pad=20)
# 调整布局
plt.tight_layout()
# 保存图片到"数据可视化"文件夹(使用os库)
img_path = os.path.join(self.output_dir, f'电影类型分布_{timestamp}.png')
plt.savefig(img_path, dpi=300, bbox_inches='tight')
plt.close()
def _plot_top20_boxoffice(self, df, timestamp):
"""绘制票房前20名电影排行榜(使用matplotlib库)"""
# 按综合票房降序排序,取前20条数据
df_top20 = df.sort_values('综合票房', ascending=False).head(20)
plt.figure(figsize=(12, 10))
# 创建渐变色(使用numpy和matplotlib库)
colors = plt.cm.viridis(np.linspace(0.2, 0.9, len(df_top20)))
# 绘制水平柱状图
bars = plt.barh(df_top20['电影名称'], df_top20['综合票房'] / 10000, color=colors)
# 添加票房数值标签
for bar in bars:
width = bar.get_width()
plt.text(width, bar.get_y() + bar.get_height() / 2,
f'{width:.2f}亿', ha='left', va='center', fontsize=10, fontweight='bold')
# 添加网格和标题
plt.xlabel('综合票房(亿元)', fontsize=14)
plt.ylabel('电影名称', fontsize=14)
plt.title('猫眼电影综合票房排行榜', fontsize=18, fontweight='bold')
plt.yticks(fontsize=12)
plt.subplots_adjust(left=0.35, right=0.9, top=0.9, bottom=0.1)
plt.gca().invert_yaxis() # 票房最高的放在顶部
plt.grid(axis='x', linestyle='--', alpha=0.7)
# 保存图片(使用os库)
img_path = os.path.join(self.output_dir, f'票房排行榜_{timestamp}.png')
plt.savefig(img_path, dpi=300, bbox_inches='tight')
plt.close()
def _plot_top20_seat_view(self, df, timestamp):
"""绘制上座率前20名电影排行榜(使用matplotlib库)"""
# 按上座率降序排序,取前20条数据
df_top20 = df.sort_values('上座率', ascending=False).head(20)
plt.figure(figsize=(12, 10))
# 创建渐变色(使用numpy和matplotlib库)
colors = plt.cm.plasma(np.linspace(0.2, 0.9, len(df_top20)))
# 绘制水平柱状图
bars = plt.barh(df_top20['电影名称'], df_top20['上座率'] * 100, color=colors)
# 添加上座率数值标签
for bar in bars:
width = bar.get_width()
plt.text(width, bar.get_y() + bar.get_height() / 2,
f'{width:.1f}%', ha='left', va='center', fontsize=10, fontweight='bold')
# 添加网格和标题
plt.xlabel('上座率 (%)', fontsize=14)
plt.ylabel('电影名称', fontsize=14)
plt.title('猫眼电影上座率排行榜', fontsize=18, fontweight='bold')
plt.yticks(fontsize=12)
plt.subplots_adjust(left=0.35, right=0.9, top=0.9, bottom=0.1)
plt.gca().invert_yaxis() # 上座率最高的放在顶部
plt.grid(axis='x', linestyle='--', alpha=0.7)
# 保存图片(使用os库)
img_path = os.path.join(self.output_dir, f'上座率排行榜_{timestamp}.png')
plt.savefig(img_path, dpi=300, bbox_inches='tight')
plt.close()
def run(self):
"""运行爬虫和分析流程
依次执行数据获取、解析、保存、分析和可视化操作。
"""
raw_data = self.fetch_data()
if not raw_data:
print("数据获取失败,程序退出")
return
df = self.parse_data(raw_data)
self.data = df
if self.save_csv:
self.save_to_csv(df)
analysis_results = self.analyze_data(df)
self.print_analysis_results(analysis_results)
if self.save_img:
self.visualize_data(df)
return df
def print_analysis_results(self, results):
"""打印分析结果
Args:
results: 分析结果字典
"""
if not results:
return
print("\n===== 数据分析结果 =====")
# 票房分布
print("\n1. 票房分布:")
print(results['票房分布'])
# 票房前十
print("\n2. 票房前十的电影:")
for i, (_, row) in enumerate(results['票房前十'].iterrows(), 1):
print(f"{i}. {row['电影名称']}: {row['综合票房'] / 10000:.2f} 亿元")
# 类型票房
print("\n3. 不同类型电影的总票房:")
for genre, boxoffice in results['类型票房'].items():
print(f"{genre}: {boxoffice / 10000:.2f} 亿元")
# 上座率前十
print("\n4. 上座率前十的电影:")
for i, (_, row) in enumerate(results['上座率前十'].iterrows(), 1):
print(f"{i}. {row['电影名称']}: {row['上座率'] * 100:.1f}%")
print("\n======================\n")
def main():
"""主函数
解析命令行参数(使用argparse库),创建爬虫实例并运行,提供额外的交互式分析功能。
"""
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description='猫眼电影票房数据爬虫与分析')
parser.add_argument('--output', '-o', default='数据可视化', help='输出目录')
parser.add_argument('--no-csv', action='store_true', help='不保存CSV文件')
parser.add_argument('--no-img', action='store_true', help='不保存图片')
# 解析命令行参数
args = parser.parse_args()
# 创建爬虫实例并运行
crawler = MaoyanBoxOfficeCrawler(
output_dir=args.output,
save_csv=not args.no_csv,
save_img=not args.no_img
)
# 运行爬虫
df = crawler.run()
# 示例:额外的交互式分析
if df is not None and not df.empty:
print("是否需要进行额外的交互式分析? (y/n)")
if input().lower() == 'y':
print("\n可用的分析命令:")
print("1. top_box [n]: 显示票房前n名的电影")
print("2. top_seat [n]: 显示上座率前n名的电影")
print("3. genre: 按电影类型统计票房")
print("4. exit: 退出")
while True:
command = input("\n输入命令 (输入 'help' 显示帮助): ").strip().lower()
if command == 'exit':
break
elif command == 'help':
print("\n可用的分析命令:")
print("1. top_box [n]: 显示票房前n名的电影")
print("2. top_seat [n]: 显示上座率前n名的电影")
print("3. genre: 按电影类型统计票房")
print("4. help: 显示帮助")
print("5. exit: 退出")
elif command.startswith('top_box'):
try:
n = int(command.split()[1]) if len(command.split()) > 1 else 10
top_movies = df.sort_values('综合票房', ascending=False).head(n)
print(f"\n票房前{n}名的电影:")
for i, (_, row) in enumerate(top_movies.iterrows(), 1):
print(f"{i}. {row['电影名称']}: {row['综合票房'] / 10000:.2f} 亿元 ({row['上映时间']})")
except:
print("命令格式错误,请使用 'top_box [n]'")
elif command.startswith('top_seat'):
try:
n = int(command.split()[1]) if len(command.split()) > 1 else 10
top_movies = df.sort_values('上座率', ascending=False).head(n)
print(f"\n上座率前{n}名的电影:")
for i, (_, row) in enumerate(top_movies.iterrows(), 1):
print(f"{i}. {row['电影名称']}: {row['上座率'] * 100:.1f}% ({row['上映时间']})")
except:
print("命令格式错误,请使用 'top_seat [n]'")
elif command == 'genre':
genre_stats = df.groupby('电影类型')['综合票房'].agg(['sum', 'count', 'mean'])
genre_stats.columns = ['总票房(万元)', '电影数量', '平均票房(万元)']
genre_stats = genre_stats.sort_values('总票房(万元)', ascending=False)
genre_stats['总票房(亿元)'] = genre_stats['总票房(万元)'] / 10000
genre_stats['平均票房(亿元)'] = genre_stats['平均票房(万元)'] / 10000
print("\n按电影类型统计票房:")
print(genre_stats[['总票房(亿元)', '电影数量', '平均票房(亿元)']].to_string(float_format='%.4f'))
else:
print("未知命令,请输入 'help' 查看可用命令")
if __name__ == '__main__':
main()
6.将完整代码上传至Gitee
https://gitee.com/zhaoshaoning/python.git
三、实验中遇到的问题和解决方法
1.无法直接在命令行中使用pip指令安装第三方库

解决方法
询问AI后得知由于MacBook 使用 Homebrew 或系统自带的 Python,这类 Python 环境不允许用户随意安装第三方库,防止破坏系统依赖,所以需要使用虚拟环境在其中安装库。
在PyCharm命令行中输入指令:
python3 -m venv myenv
source myenv/bin/activate
再在PyCharm中配置解释器,使用该虚拟环境

就可以直接在PyCharm的命令行中输入pip install 来安装需要的第三方库了
2.网络请求失败,爬虫无法获取数据,请求超时
解决方法
完善请求头信息,添加随机延迟避免频繁请求
3.数据处理错误,票房单位转换失败,上映天数字提取异常
解决方法
在convert_box_office中增加正则表达式处理特殊字符
4.可视化图表中的中文显示为乱码
解决方法
matplotlib中未正确配置中文字体,要在代码中明确指定系统中存在的中文字体文件:
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
5.保存的CSV文件打开后中文显示乱码
解决方法
使用utf-8-sig编码保存 CSV 文件:
df.to_csv('data.csv', encoding='utf-8-sig')
6.图片保存失败
解决方法
使用图片目录的绝对路径,同时明确指定图片的格式
plt.savefig('chart.png', dpi=300, bbox_inches='tight')
四、参考资料
《零基础学Python》
bilibili相关视频
询问大模型
五、实验感悟
实验四的大作业想了很久不知道要做什么程序,最后还是决定做一个爬虫程序。Python爬虫技术是Python里最重要的部分之一,在今天这样数据和信息爆炸的时代,爬虫可以帮助我们很有效地处理数据和信息。老师上课讲到爬虫时带我们写了一个简单的爬取豆瓣电影的程序,再加上我有时候想想了解最新上映的电影但是又有点懒得点开看,于是我就写了这个程序。它可以帮助我直观地看到猫眼上还在上映的电影的票房数据等,帮助我决策要不要去看某部电影。第一次编写这么复杂的程序,花费了很多时间和精力,中间PyCharm报了无数错误(点击运行满屏红色的救赎感),不断的查找相关视频资料和询问AI,但最终运行成功的时候真的成就感满满。这次实验过程也极大的提高了我的编程能力,编写程序的过程也是一个不断探索的过程,我对编程的兴趣也多了很多。
六、课程感悟
“人生苦短,我用Python!”
王志强老师的Python选修课真的带给我很大的惊喜!Python作为排名第一的语言简洁智能而优雅美丽,在经历了一学期C语言语法折磨的我在第一节课看到一行无比简单的print("Hello World")而且不需要其他任何东西就能直接输出时被惊呆了,Python的功能也是无比强大,可以把脑子里的奇思妙想都实现出来。王志强老师的人格魅力更是折服所有人!上第一堂课前就在课程群里看到了用卡卡西头像的强哥在群里跟同学们打成一片,老师上课也是深入浅出,总是用生动的比喻和例子帮助我们了解看似抽象的东西。蛋炒饭和盖浇饭的例子让我对面向过程编程和面向对象编程的区别有了很深的记忆。上课的程序和实验的程序强哥也手把手的带我们写,真的让零基础的我学会了很多Python知识。更不用说老师特别体谅同学,合理的要求就可以请假,各种加分机会、还总是帮我们推迟实验报告提交时间……真的很庆幸当初突出重围抢到了王志强老师的Python课,这门课不仅教会了我很多Python编程知识,更教会了我很多在大学里应该要学会的能力和素质。
“脚踏实地时,抬头看路!”
“那些看似波澜不惊的日复一日,终将在某一天,让我们看到坚持的意义。”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号