

zookeeper(一):简介
前言
在很多时候,我们都可以在各种框架应用中看到ZooKeeper的身影,比如Kafka中间件,Dubbo框架,Hadoop等等。所以Zookeeper到底是什么呢?
一、zookeeper是什么?
ZooKeeper由Yahoo开发的一个分布式服务协调框架,后来捐赠给了Apache,现已成为Apache顶级项目。
ZooKeeper提供了分布式数据一致性的解决方案,其一致性是通过基于Paxos算法的ZAB协议完成的。
主要功能包括:
- 命名服务/注册中心
- 软负载均衡
- 统一配置管理
- 主节点选举
- 等
但ZooKeeper没有直接提供这些服务,而是提供 API 供开发者实现自己需要的服务。
二、为什么使用zookeeper?
Zookeeper最早起源于雅虎研究院的一个研究小组,在当时,研究人员发现,在雅虎内部的很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题,所以他们就试图开发一个通用的无单点问题的分布式协调框架。
分布式系统服务单点问题的探讨 - 简书 (jianshu.com)
ZooKeeper能保证:
-
更新请求顺序进行:来自同一个client的更新请求按其发送顺序依次执行
-
数据更新原子性:一次数据更新要么成功,要么失败
-
全局唯一数据视图:client无论连接到哪个server,数据视图都是一致的
-
实时性:在一定时间范围内,client读到的数据是最新的
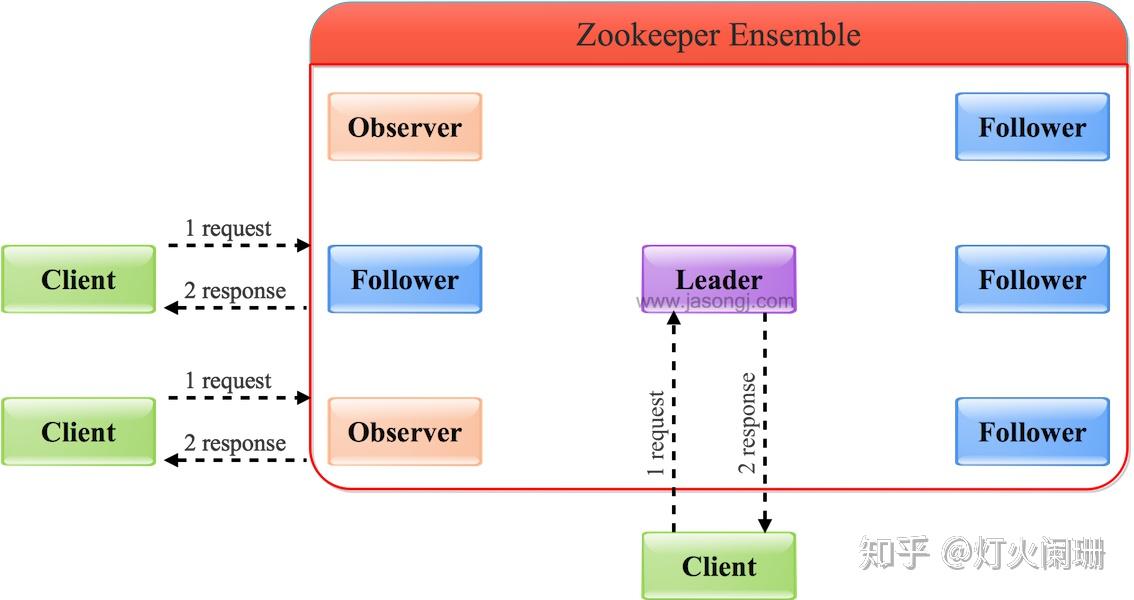
三、技术架构
ZooKeeper 集群分为 Leader 、 Follower和Observer
- Leader:整个Zookeeper集群工作机制的核心,主要工作包括:
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性。
- 集群内部各服务器的调度者。
- Follower:是Zookeeper整个集群状态的跟随者,主要工作包括:
- 处理客户端非事务请求,转发事务请求给Leader。
- 参与事务请求Proposal的投票。
- 参与Leader选举投票。
- Observer:和Follower的区别是不参与任何形式的投票,只提供非事务能力。用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
四、数据模型
ZooKeeper的数据结构和Linux文件系统类似,都是树形结构,每个节点称为一个ZNode,每一个ZNode默认存储1M数据。
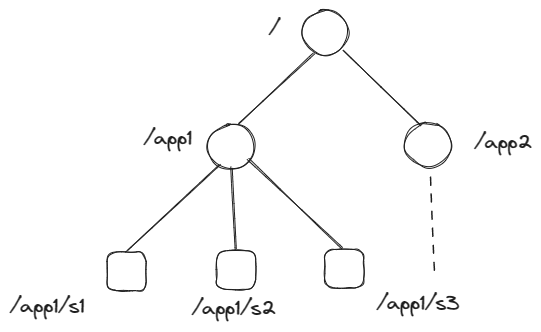
每个 znode 都有自己所属的节点类型和节点状态。
其中节点类型可以分为 持久节点、持久顺序节点、临时节点 和 临时顺序节点。
持久节点:一旦创建就一直存在,直到将其删除。
持久顺序节点:一个父节点可以为其子节点维护一个创建的先后顺序 ,这个顺序体现在节点名称上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
临时节点:临时节点的生命周期是与 客户端会话 绑定的,会话失效则节点消失 。临时节点 只能做叶子节点 ,不能创建子节点。
临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
节点状态中包含了很多节点的属性比如 czxid 、mzxid 等等,在 zookeeper 中是使用 Stat 这个类来维护的。
-
czxid:Created ZXID,该数据节点被 创建 时的事务ID。
-
mzxid:Modified ZXID,节点 最后一次被更新时 的事务ID。
-
ctime:Created Time,该节点被创建的时间。
-
mtime: Modified Time,该节点最后一次被修改的时间。
-
version:节点的版本号。
-
cversion:子节点 的版本号。
-
aversion:节点的 ACL 版本号。
-
ephemeralOwner:创建该节点的会话的 sessionID ,如果该节点为持久节点,该值为0。
-
dataLength:节点数据内容的长度。
-
numChildre:该节点的子节点个数,如果为临时节点为0。
-
pzxid:该节点子节点列表最后一次被修改时的事务ID,注意是子节点的 列表 ,不是内容。
五、会话
我想这个对于后端开发的朋友肯定不陌生,不就是 session 吗?只不过 zk 客户端和服务端是通过 TCP 长连接 维持的会话机制,其实对于会话来说你可以理解为保持连接状态 。
在 zookeeper 中,会话还有对应的事件,比如 CONNECTION_LOSS 连接丢失事件 、SESSION_MOVED 会话转移事件 、SESSION_EXPIRED 会话超时失效事件 。
六、权限控制
ACL 为 Access Control Lists ,和Linux的ACL机制很像。在 zookeeper 中定义了5种权限,它们分别为:
- CREATE :创建子节点的权限。
- READ:获取节点数据和子节点列表的权限。
- WRITE:更新节点数据的权限。
- DELETE:删除子节点的权限。
- ADMIN:设置节点 ACL 的权限。
七、监听通知机制
Watcher是基于观察者模式实现的一种机制。
当我们需要观察Zookeeper的数据状态变化时,可以向Zookeeper服务端针对想观察的节点注册监视点。这样,我们就不需要在自己的应用内维护节点旧数据,主动轮询Zookeeper频繁获取数据,并和旧数据对比差异来判断是否变化。相反,Zookeeper当节点发生变化时,会通过建立的会话主动通知客户端。
如下图所示:
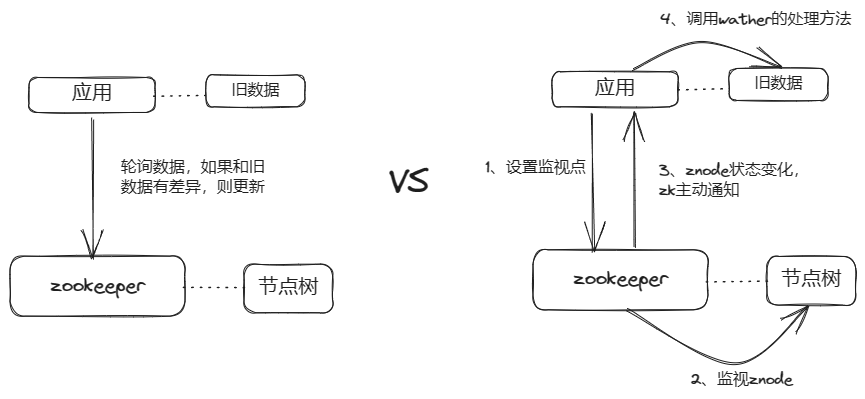
监视点是一次性的。一旦监视点被触发,ZooKeeper就会将其删除。如果需要不断监听ZNode的变化,可以在收到通知后再设置新的watcher注册到ZooKeeper。
监视点的类型有很多,如监控ZNode数据变化、监控ZNode子节点变化、监控ZNode 创建或删除。
八、选举机制
ZooKeeper在集群状态下,需要有一个主节点才能够正常工作。这个主节点,并不是依赖配置文件来指定的,而是在ZooKeeper服务器初始化时就在内部进行选举,产生一台做为Leader,多台做为Follower,并且遵守半数可用原则。
半数可用原则的含义是,集群中服务正常的节点必须超过集群总节点数的一半,该集群才是正常可用的。所以一般而言,ZooKeeper集群的节点数量都是奇数。例如,5个节点和6个节点的集群,都是最多只能故障2个节点,其容错率是一样的,所以偶数个节点是浪费资源了。
如果在运行时,如果长时间无法和Leader保持连接的话,则会再次进行选举,产生新的Leader,以保证服务的可用。
Zookeeper——选举机制原理与Leader和Follower作用_zookeeper leader follower_庄小焱的博客-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号