
02-AI大模型(二)--Transformer框架
1. Transformer的框架
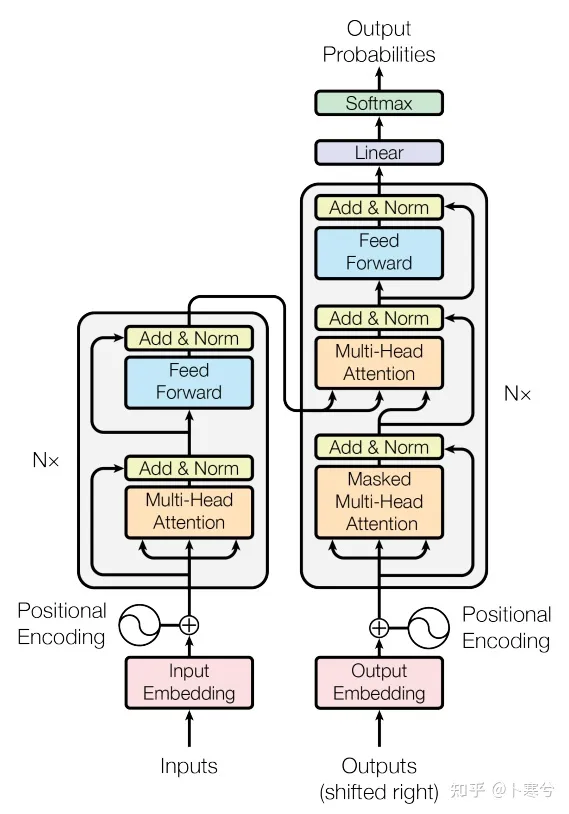
这段描述的基本结构涉及到了Transformer模型中的几个重要组成部分,下面对每个部分进行简要解释:
1. Embedding + Position Embedding
-
Embedding层将输入的token转换为向量表示,通常是通过一个可学习的词嵌入矩阵将每个token映射到一个固定维度的向量空间中。
-
Position Embedding用于表示输入序列中每个位置的信息,以便模型能够识别输入中不同位置的相对距离和顺序信息。
2.Self-Attention:
-
Self-Attention是Transformer中的核心组件,用于在输入序列内部进行交互和信息传递。它允许每个输入位置都能够与所有其他位置进行交互,并计算出每个位置的注意力权重。
-
Self-Attention通过将输入序列的每个位置向量与自身进行点积,然后应用softmax函数,最终得到每个位置对所有位置的注意力分布。
3. Add+LN:
-
Add表示残差连接,它允许模型在学习过程中保留原始输入的信息,有助于缓解梯度消失问题。在Transformer中,残差连接通常与Layer Normalization结合使用。
-
Layer Normalization(LN)用于在每个层的输出上进行归一化,有助于加速模型的训练并提高模型的稳定性。
4. Feed-Forward Network (FN):
-
Feed-Forward Network是Transformer中的一个全连接前馈神经网络,用于对每个位置的表示进行非线性变换和特征提取。
-
在每个位置上,输入通过一个多层感知器(MLP)进行前向传播,并产生一个新的表示。
5.Add + LN:
-
类似于前面的Add + LN结构,这里再次使用残差连接和Layer Normalization,将Feed-Forward Network的输出与其输入相加,并对结果进行归一化。
整体而言,这些基本结构组成了Transformer模型的核心架构,通过多头自注意力机制和前馈神经网络,Transformer能够有效地捕获输入序列中的信息,并生成相应的输出表示。
参考:https://zhuanlan.zhihu.com/p/420820453
2. Transformer的常见问题
Q1:为什么Transformer 需要进行 Multi-head Attention?
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
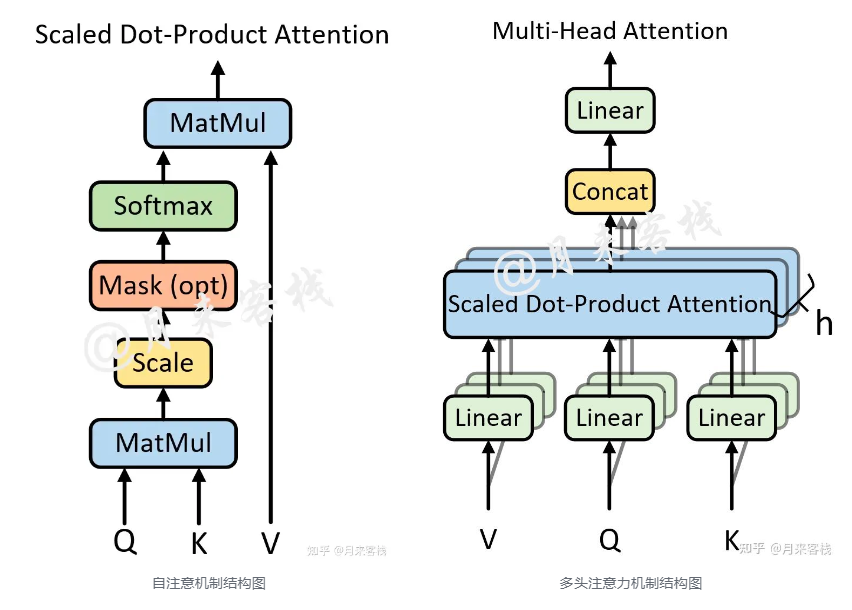
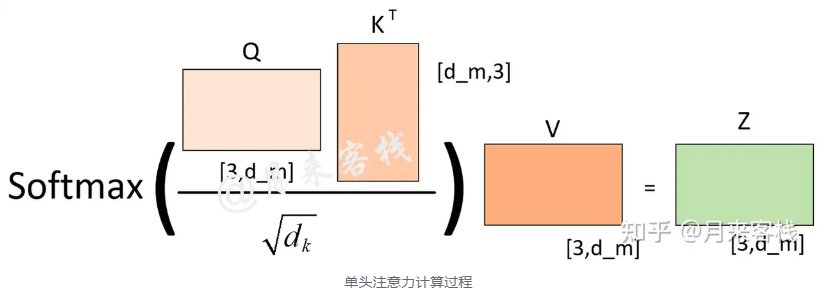
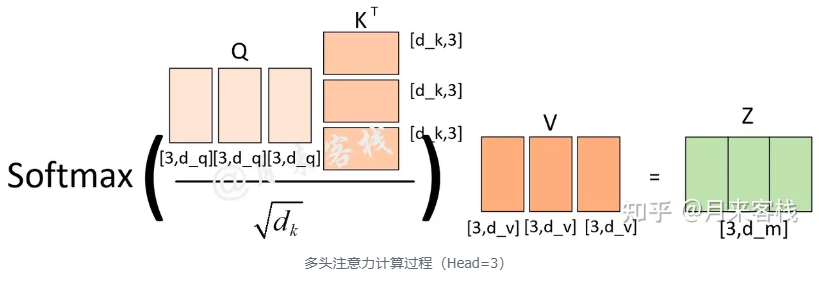
例如:当h不一样时,dk的取值也不一样,进而使得对权重矩阵的scale的程度不一样。例如,如果d_m=768,那么当h=12时,则dk=64;当h=1时,则d_k=768。所以,当模型的维度𝑑𝑚确定时,一定程度上ℎ越大整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
参考:https://www.zhihu.com/question/341222779
Q2: Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
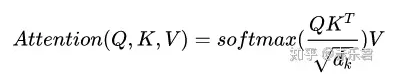
1.) 点乘的物理意义说,两个向量的点乘表示两个向量的相似度;
2.)K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
这里解释下我理解的泛化能力,因为K和Q使用了不同的W_k, W_Q来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。
但是如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。这样的矩阵导致对V进行提纯的时候,效果也不会好。
参考:https://www.zhihu.com/question/319339652
Q3: Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
-
K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为 有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
-
为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。
Q4:为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根)
-
这取决于softmax函数的特性,如果softmax内计算的数数量级太大,会输出近似one-hot编码的形式,导致梯度消失的问题,所以需要scale;
参考:https://www.zhihu.com/question/339723385
Q5: 为什么在进行多头注意力的时候需要对每个head进行降维?
-
增加模型的表达能力: 多头注意力允许模型在不同的注意力空间中学习不同的表示。每个注意力头都可以专注于输入的不同方面,从而提高了模型的表达能力。通过引入降维操作,可以确保每个头的注意力权重矩阵的大小相对较小,从而限制模型的参数数量,并确保模型的计算效率。
-
减少计算成本: 在多头注意力中,如果每个头的注意力权重矩阵大小过大,将导致计算成本显著增加。通过降维操作,可以降低每个头的注意力权重矩阵的维度,从而减少计算成本,提高模型的效率。
-
增强模型的稳定性: 通过降维操作,可以降低每个头的注意力权重矩阵的维度,使得模型更加稳定。较小的注意力权重矩阵通常更容易学习,并且对噪声和数据变化具有更好的鲁棒性。
总之,将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息。基本结构:Embedding + Position Embedding,Self-Attention,Add + LN,FN,Add + LN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号