

关于Ollama多容器部署Deepseek大模型集群访问的负载均衡方案
起因: 公司资金有限, 只采购一台大模型服务器, 上边配置有5块L20显卡, 开发通过ollama的接口来调用DeepSeek, 多并发访问时服务会频繁报错499和500.
解决方案:
1. 利用现有资源, 通过openresty(nginx)来实现多个ollama容器(每个容器指定一块L20)的负载均衡, 提高并发访问效率.
2. 为每个ollama容器都复制出一份独立的大模型文件, 提高磁盘I/O效率.
拓扑图:
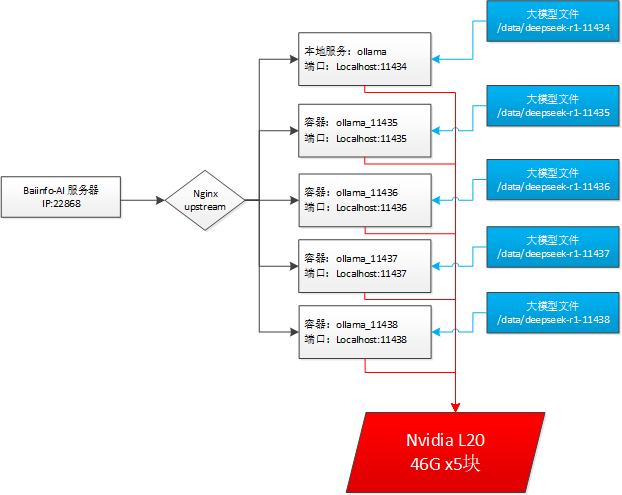
1. openresty(nginx)的容器配置如下:
docker-compse.yaml 文件如下:
version: '3'
services:
openresty:
image: openresty/openresty:latest
privileged: true
container_name: openresty
restart: always
network_mode: host
volumes:
- ./nginx/conf/nginx.conf:/usr/local/openresty/nginx/conf/nginx.conf
- ./nginx/conf.d:/etc/nginx/conf.d
- /etc/localtime:/etc/localtime
- ./nginx/logs:/usr/local/openresty/nginx/logs
2. openresty(nginx)的负载均衡配置如下:
ollama.conf文件配置如下:
# ollama负载均衡
upstream ollama_cluster {
zone ollama_cluster_zone 64k; # 共享内存区域多Worker负载均衡状态同步
least_conn;
keepalive 32;
server 127.0.0.1:11434 weight=1 max_fails=1 fail_timeout=15s;
server 127.0.0.1:11435 weight=1 max_fails=1 fail_timeout=15s;
server 127.0.0.1:11436 weight=1 max_fails=1 fail_timeout=15s;
server 127.0.0.1:11437 weight=1 max_fails=1 fail_timeout=15s;
server 127.0.0.1:11438 weight=1 max_fails=1 fail_timeout=15s;
}
# ollama_cluster 集群站点配置
server {
listen 22868 reuseport;
server_name localhost;
access_log logs/ollama_cluster_access.log main;
error_log logs/ollama_cluster_error.log;
location / {
proxy_pass http://ollama_cluster;
proxy_read_timeout 600s;
proxy_connect_timeout 75s;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header Host $host;
# 启用响应缓冲(大模型必备)
proxy_buffering on;
proxy_buffers 16 32k;
proxy_buffer_size 64k;
proxy_busy_buffers_size 128k;
}
}
3. 启动脚本如下:
1) 安装好容器的nvidia支持:
# 安装docker容器的 Nvidia GPU 模式支持
# 1). Apt 的安装
# a.配置仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
# b.安装
sudo apt-get install -y nvidia-container-toolkit
# 2).Yum or Dnf 的安装方式
# a.配置仓库
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
# b.安装
sudo yum install -y nvidia-container-toolkit
# 配置 Docker 共享使用 Nvidia 显存
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker2) run-ollama-cluster.sh文件脚本内容如下:
#!/bin/bash
# 清理容器,重启新的Ollama容器集群
docker stop ollama_11434 && docker rm ollama_11434
docker stop ollama_11435 && docker rm ollama_11435
docker stop ollama_11436 && docker rm ollama_11436
docker stop ollama_11437 && docker rm ollama_11437
docker stop ollama_11438 && docker rm ollama_11438
docker run -d --gpus device=0 -e OLLAMA_NUM_PARALLEL=8 -e OLLAMA_KEEP_ALIVE=-1 -v /data/deepseed-r1-11434:/root/.ollama -p 11435:11434 --name ollama_11434 ollama/ollama
docker run -d --gpus device=1 -e OLLAMA_NUM_PARALLEL=8 -e OLLAMA_KEEP_ALIVE=-1 -v /data/deepseed-r1-11435:/root/.ollama -p 11435:11434 --name ollama_11435 ollama/ollama
docker run -d --gpus device=2 -e OLLAMA_NUM_PARALLEL=8 -e OLLAMA_KEEP_ALIVE=-1 -v /data/deepseed-r1-11436:/root/.ollama -p 11436:11434 --name ollama_11436 ollama/ollama
docker run -d --gpus device=3 -e OLLAMA_NUM_PARALLEL=8 -e OLLAMA_KEEP_ALIVE=-1 -v /data/deepseed-r1-11437:/root/.ollama -p 11437:11434 --name ollama_11437 ollama/ollama
docker run -d --gpus device=4 -e OLLAMA_NUM_PARALLEL=8 -e OLLAMA_KEEP_ALIVE=-1 -v /data/deepseed-r1-11438:/root/.ollama -p 11438:11434 --name ollama_11438 ollama/ollama
# 重启openresty容器
docker-compose down && docker-compose up -d
# 预热模型
curl -X POST http://127.0.0.1:11434/api/generate -d '{
"model": "qwq:latest",
"prompt": "为什么天空是蓝色的?",
"stream": false
}'
curl -X POST http://127.0.0.1:11435/api/generate -d '{
"model": "qwq:latest",
"prompt": "为什么天空是蓝色的?",
"stream": false
}'
curl -X POST http://127.0.0.1:11436/api/generate -d '{
"model": "qwq:latest",
"prompt": "为什么天空是蓝色的?",
"stream": false
}'
curl -X POST http://127.0.0.1:11437/api/generate -d '{
"model": "qwq:latest",
"prompt": "为什么天空是蓝色的?",
"stream": false
}'
curl -X POST http://127.0.0.1:11438/api/generate -d '{
"model": "qwq:latest",
"prompt": "为什么天空是蓝色的?",
"stream": false
}'
4. ab工具压测
request.json文件内容如下:
{
"model": "qwq:latest",
"prompt": "详细分析2024年全球人工智能发展趋势,包括技术突破、政策监管和产业应用三个维度,要求每个维度不少于200字。",
"stream": false,
"options": {
"temperature": 0.5,
"num_predict": 1024
}
}测试命令如下:
ab -n 100 -c 20 -p request.json -T 'application/json' -e result.csv -s 60 -k -l -v 2 http://IP:22868/api/generate > debug.log 2>&1 &测试结果如下: 100请求, 并发20, 还算可以.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号