

ELK之分布式搜索与分析引擎Elasticsearch
日志三剑客ELK
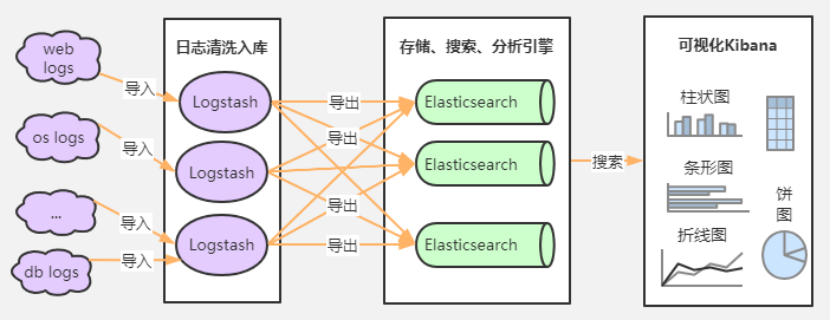
1、Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到elasticsearch服务器上;
2、Elasticsearch是数据的索引搜索和数据分析引擎(也可存储数据);
3、Kibana对Elasticsearch数据的进行可视化展示;
What is Elasticsearch?
Open Source,Distributed.RESTful Search Engine 开源的,分布式,RESTful搜索引擎;
Elasticsearch的诞生故事
2004年,一个叫Shay Banon的宠妻狂魔.因为妻子要去伦敦学习厨师,为妻子开发一个搜索食谱的搜索引擎,基于Lucene开发发布了第一个开源项目.叫做"Compass"
2010年,由于Shay Banon工作需要高性能的,实时的,分布式的搜索,基于Compass重写成为了独立的服务Elasticsearch.
2010年2月,Elasticsearch第一个版本发布
2010年2月,Elasticsearch第一个版本发布;
2012年2月,Elasticsearch 1.0发布,同时成立Elastic公司 (创业)
2015年10月,Elasticsearch 2.0发布
2016年10月,Elasticsearch 5.0发布,至少需要jdk1.8
2017年8月,Elasticsearch 6.0发布
2019年8月,Elasticsearch 7.0发布
现在最新版本,Elasticsearch 7.6.2 (2020年5月)
谁在使用Elasticsearch?
1、维基百科,类似百度百科,全文检索;
2、Stack Overflow国外的程序异常问答网站;
3、GitHub 开源代码管理,搜索上千亿行代码;
4、携程机票
5、去哪儿订单中心
6、滴滴打车地图搜索
......
Github: https://github.com/elastic
基于关系型数据库无法满足日益增加的搜索需求,有诸多不足和局限,搜索引擎框架解决了基于数据库搜索的不足,实现了分布式,高可用,高性能搜索
Elasticsearch VS Solr
Solr是第一个基于Lucene核心库功能完备的搜索引擎产品,诞生早于Elasticsearch,早期在全文搜索领域,Solr有非常大的优势,在近几年大数据发展时代,Elastic由于其分布式特性,满足了很多PB级大数据的处理需求,特别是后面ELK三大组合的流行,Solr使用量逐渐下跌;
ElasticSearch和Solr均起源于Lucene,Lucene是基于Java语言开发的搜索引擎库类(jar包)创建于1999年,2005年成为Apache顶级开源项目,Lucene具有高性能、但易扩展有局限性,只能单机环境,而且只能基于Java语言开发,其他php、python等不能使用;
类库的接口学习曲线陡峭,原生并不支持水平扩展;
自己开发一个完整的搜索引擎工作量比较大,必须要懂一些搜索引擎原理的人才能用好,所以后来elasticsearch基于lucene进行封装,支持分布式,可水平扩展,降低全文检索的学习曲线,基于http restful api可以被任何编程语言调用;
在了解Elasticsearch之前,有必要介绍两个基本概念
倒排索引和分词器(ik分词器)
假设我们数据库存储了三条数据 key:1 value:我是程序猿 分词-> 我 是 程序 程序猿 key:2 value:我爱编程 分词-> 我 爱 编程 key:3 value:我会用Java写增删改查程序代码 分词-> 我 会用 java 写 增删改查 程序 代码
那么全文检索底层是如何做的呢?
首先进行分词,然后把我们分的词当做索引
我 : 1,2,3
程序: 1,3
代码: 3
这样当我们去全文检索 程序,此刻就可以查出 key(或者称作id) 1,3,搜索引擎的思想大致就是这样去实现的
Elasticsearch 7.6.2 Linux环境搭建
下载: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz 解压缩 tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz
下图为解压后的目录结构
下面需要做一系列配置,否则在启动时候日志报错,需要我们注意
修改JDK配置
目录里面包含有JDK,7.6.2版本JDK是13,运行最低需要JDK11的版本,所以我们的配置里面如果配置的是JDK8版本,需要配置一下JDK,
cd elasticsearch-7.6.2/bin/
vim elasticsearch-env

这样就配置使用es自带的JDK,而不会使用我们配置的全局环境变量
修改文件所有者
若无非root用户,按下面步骤创建
1.useradd es 创建用户
2.passwd es 给已创建的用户testuser设置密码(密码设置不能少于8个字符,最好不要连续数字或者字符),确认时重输一次密码即可
chown es:es -R /usr/local/elasticsearch
修改JVM配置
config目录下jvm.options修改 -Xms512m -Xmx512m
- -Xms 为jvm启动时分配的内存,比如-Xms512m,表示分配512M
- -Xmx 为jvm运行过程中分配的最大内存,比如-Xms512m,表示jvm进程最多只能够占用512M内存
修改数据和日志目录:
vim elasticsearch.yml
修改数据和日志目录:此处需要给予用户足够权限 chmod -R 777 /home/es
path.data: /home/es/elasticsearch/data # 数据目录位置
path.logs: /home/es/elasticsearch/logs # 日志目录位置
修改绑定的IP
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问
默认只允许本机访问,修改为0.0.0.0后则可以远程访问
修改开启文件数量限制
vim /etc/security/limits.conf 添加到文件最后,若想生效,需重启linux * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096
修改内存权限限制
vim /etc/sysctl.conf 添加vm.max_map_count=655360,永久修改
执行 sysctl -p
配置节点

把 discovery.seed_hosts 注释打开,写上当前主节点的IP;(cluster.name && node.name && cluster.initial_master_nodes后续使用客户端也需要打开)
启动与关闭
在bin目录下启动,启动需要切换非root用户启动
./elasticsearch 前台运行
./elasticsearch -d 后台运行
出现started时启动完成
关闭 kill pid
Elasticsearch端口9300、9200
9300是tcp通讯端口,集群ES节点之间通讯使用;
9200是http协议的RESTful接口
浏览器访问成功界面

Elasticsearch的客户端工具
ealsticsearch只是后端提供各种resulful api,看数据并不直观,所以建议安装客户端插件,elasticsearch-head安装包
下载地址:https://github.com/mobz/elasticsearch-head
zip包下载: https://codeload.github.com/mobz/elasticsearch-head/zip/master
CentOS安装npm
npm: Nodejs下的包管理器;
推荐从此处下载:https://npm.taobao.org/mirrors/ (也可下载12版本,运行过程中本人发现部分版本npm 不支持13版本,改为12也可以 )
直接下载: https://cdn.npm.taobao.org/dist/node/latest-v13.x/node-v13.0.0-linux-x64.tar.gz
解压:tar -zxvf node-v13.0.0-linux-x64.tar.gz
mv node-v13.0.0-linux-x64 node-v13.13.0
配置nodejs环境变量
vim /etc/profile 在path中加入 /usr/local/node-v13.0.0/bin即可; export PATH=/usr/local/node-v13.0.0/bin source /etc/profile 验证:
node -v npm -v
Npm环境准备好了之后,开始安装elasticsearch-head
解压:unzip elasticsearch-head-master
cd elasticsearch-head-master
npm install
(如果执行失败,可以cnpm install,使用cnpm之前需要安装cnpm,通过npm install -g cnpm --registry=https://registry.npm.taobao.org该命令安装;cnpm -v)
npm run start (npm run-script start)
可以后台启动:nohup npm run-script start &
npm -l 显示所有使用帮助信息
然后访问: http://localhost:9100/
此处需要注意 elasticsearch.yml注释需要放开
cluster.name
node.name
cluster.initial_master_nodes
如果一切配置没有问题,我们访问9100端口,客户端的功能就不一一介绍了,多点击点击就能够明白大概

Elasticsearch测试工具之Kibana
Kibana的版本要和elasticsearch版本一致;测试工具其实可以用很多种:postman、curl、head、浏览器插件、kibana; Github https://github.com/elastic/kibana 下载:https://www.elastic.co/downloads/kibana 下载下来是一个压缩包,解压即可; 启动,进入bin目录 ./kibana 汉化:./config/kibana.yml 里面修改i18n.locale: "zh-CN"
kibana也不允许root启动,指定centos用户启动 chown es:es -R /usr/local/kibana ./kibana -h 命令帮助 启动命令: ./kibana 或者 ./kibana serve 后台启动: nohup /usr/local/kibana-7.6.2/bin/kibana & 访问: http://192.168.194.128:5601 远程访问kibana界面被拒绝 将$KIBANA/config/kibaba.yml下的 server.host: "localhost" 更改为server.host: "0.0.0.0" 即可;
Elasticsearch基操(Kibana左侧展开Dev Tools控制台)
PUT /test PUT /test/_doc/1 { "name" : "doc1", "desc" : "this is doc1" } PUT /test/_doc/2 { "name" : "doc2", "desc" : "this is doc2" } 查询 GET /test/_doc/doc1 GET /test/_doc/doc2
我们想要使用Elasticsearch,就必须对以下概念有所了解

Elasticsearch之DSL语言
Elasticsearch基于JSON提供完整的Query DSL(Domain Specified Language)来定义查询
在Elasticsearch中,字段类型有以下几种
字符串类型 text 、 keyword 数值类型 (8种) long, integer, short, byte, double, float, half_float, scaled_float 日期类型 date 布尔值类型 boolean 二进制类型 binary 等等......
指定字段的类型(使用mapping)


PUT /test/_doc/3 { "mapping" : { "properties" : { "name" : { "type" : "keyword" }, "marketPrice" : { "type": "double" }, "mallPrice" : { "type" : "double" }, "store" : { "type" : "integer" }, "nameDesc" : { "type" : "text" } } }, "name" : "Apple-11", "marketPrice" : 9999.99, "mallPrice" : 6666.66, "store" : 22, "nameDesc" : "苹果11" }
如果不指定字段类型,则会给我们默认配置
文档操作
文档替换: PUT /test/_doc/1 { "name" : "huawei phone 2", "initPrice" : 3998.01, "nowPrice" : 3989.01, "store" : 200, "nameDesc" : "华为手机huawei phone 2" } (相当于是先删除后插入) 替换需要带上全部的字段,否则就会丢失掉字段; 文档更新 POST /test/_update/1 { "doc" : { "nameDesc" : "华为手机huawei phone 2x3" } } 删除数据: DELETE /test/_doc/1 数据查询 GET /test/_search { "query": { "match_all": {} } } GET /test/_search { "query": { "match_phrase": { "name" : "phone" } } } match_phrase会精确匹配查询的短语,需要全部单词和顺序要完全一样,标点符号除外; GET /test/_search { "query": { "match_phrase_prefix": { "name" : "huawei" } } } match_phrase_prefix 和 match_phrase 用法是一样的,区别就在于它允许对最后一个词进行前缀匹配,比如查询 I like sw 就能匹配到 I like swimming and riding. GET /test/_search { "query": { "match": { "nameDesc" : "huawei" } }, "_source": ["name","nowPrice"] } 使用_source,让结果只显示某几个字段; match任何一个匹配上即可; 分页排序 GET /test/_search { "query": { "match": { "nameDesc" : "huawei" } }, "sort": [ { "store": { "order": "desc" } } ], "_source": ["name","nowPrice"], "from": 0, "size": 1 } must 查询,相当于sql的and查询,所有的条件满足 where id = 1 and phone= xxx才可以; GET /test/_search { "query": { "bool": { "must": [ { "match": { "nameDesc" : "huawei" } }, { "match": { "name": "huawei" } } ] } }, "_source": ["name","nowPrice"] } should查询,相当于SQL的or查询, where id = 1 or name = xxx; GET /test/_search { "query": { "bool": { "should": [ { "match": { "nameDesc" : "huawei" } }, { "match": { "name": "huawei" } } ] } }, "_source": ["name","nowPrice"] } must_not 不满足条件的查询结果返回,满足条件的结果不返回; GET /test/_search { "query": { "bool": { "must_not": [ { "match": { "nameDesc" : "huawei" } }, { "match": { "name": "huawei" } } ] } }, "_source": ["name","nowPrice"] } filter条件过滤 GET /test/_search { "query": { "bool": { "must": [ { "match": { "nameDesc" : "huawei" } }, { "match": { "name": "huawei" } } ], "filter": [ { "range": { "store": { "gte": 10, "lte": 20000 } } } ] } }, "_source": ["name","nowPrice"] } 高亮显示 GET /test/_search { "query": { "bool": { "should": [ { "match": { "nameDesc" : "huawei" } } ] } }, "highlight": { "pre_tags": "<span style='color:red'>", "post_tags": "</span>", "fields": { "nameDesc": {} } } }
Kibana的SQL查询
我们上面那些是DSL查询,DSL查询可以改造成SQL查询,比如:;
POST /_sql?format=txt
{
"query": "select * from powermall"
}
注意:如果index库中没有数据,查询会报错;
ElasticHD工具
下载:https://github.com/360EntSecGroup-Skylar/ElasticHD
下载linux zip:下载zip
ElasticHD 支持ES监控、实时搜索、索引列表信息查看、SQL转换成DSL等功能;
下载下来是一个zip压缩包;
解压:unzip elasticHD_linux_amd64.zip
Linux下: ./ElasticHD -p 0.0.0.0:9800 启动
如果发生错误: exec: "xdg-open": executable file not found in $PATH
安装xdg-utils:
yum install xdg-utils -y
然后浏览器访问 IP:9800
注意如果ElasticHD版本不匹配elasticsearch版本,可能转换后的DSL语句有问题;
IK分词插件
Elasticsearch官方自带elasticsearch-analysis-ik分词器,这是一个将Lucence IK分词器集成到elasticsearch的ik分词器插件,并且支持自定义词典,源代码托管在github.com上:https://github.com/medcl/elasticsearch-analysis-ik,是elasticsearch中国社区负责人维护的项目,中国人维护的项目;
7.6.2版本IK下载:zip
安装
1、在github上下载同elasticsearch匹配的版本;
2、将下载的zip包解压到elasticsearch安装目录/plugin/ik下
3、重启elasticsearch;
测试IK分词器
IK分词安装后有两种分词策略:ik_max_word和ik_smart; ik_max_word:对输入文本根据词典穷尽各种分割方法是细力度分割策略;ik_smart:对输入文本根据词典以及歧义判断等方式进行一次最合理的粗粒度分割; 分词策略ik/ik_max_word GET _analyze { "analyzer": "ik_max_word", "text": ["中华人民共和国国歌"] } 分词策略ik_smart GET _analyze { "analyzer": "ik_smart", "text": ["中华人民共和国国歌"] }
Elasticsearch Java API客户端
文档:https://www.elastic.co/guide/index.html
Elasticsearch的Java API客户端分为两种:
(1)原生的Java API;
(2)REST API (推荐使用);
REST API又分为两种:
(1)Java Low Level REST Client
低级客户端,采用http与es通信,对所有es版本兼容;
(2)Java High Level REST Client
高级客户端,底层封装了Java Low Level REST Client客户端,使用更方便;
Java高级REST客户端对低级客户端进行了封装,它的主要目的是公开API特定的方法,这些方法接受请求对象作为参数并返回响应对象,以便请求编码和响应解码由客户端本身处理,每个API可以同步或异步调用,同步方法返回一个响应对象,而名称以async后缀结尾的异步方法则需要一个监听器参数,一旦接收到响应或错误,该监听器就会被通知(工作在低级客户端管理的线程池上);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号