

scarpy架构组成和工作原理
汽车之间案例:
import scrapy class CarSpider(scrapy.Spider): name = 'car' allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html'] # 注意如果你的请求的接口是html为结尾的 那么是不需要加/的 start_urls = ['https://car.autohome.com.cn/price/brand-15.html'] def parse(self, response): name_list = response.xpath('//div[@class="main-title"]/a/text()') price_list = response.xpath('//div[@class="main-lever"]//span/span/text()') for i in range(len(name_list)): name = name_list[i].extract() price = price_list[i].extract() print(name,price)
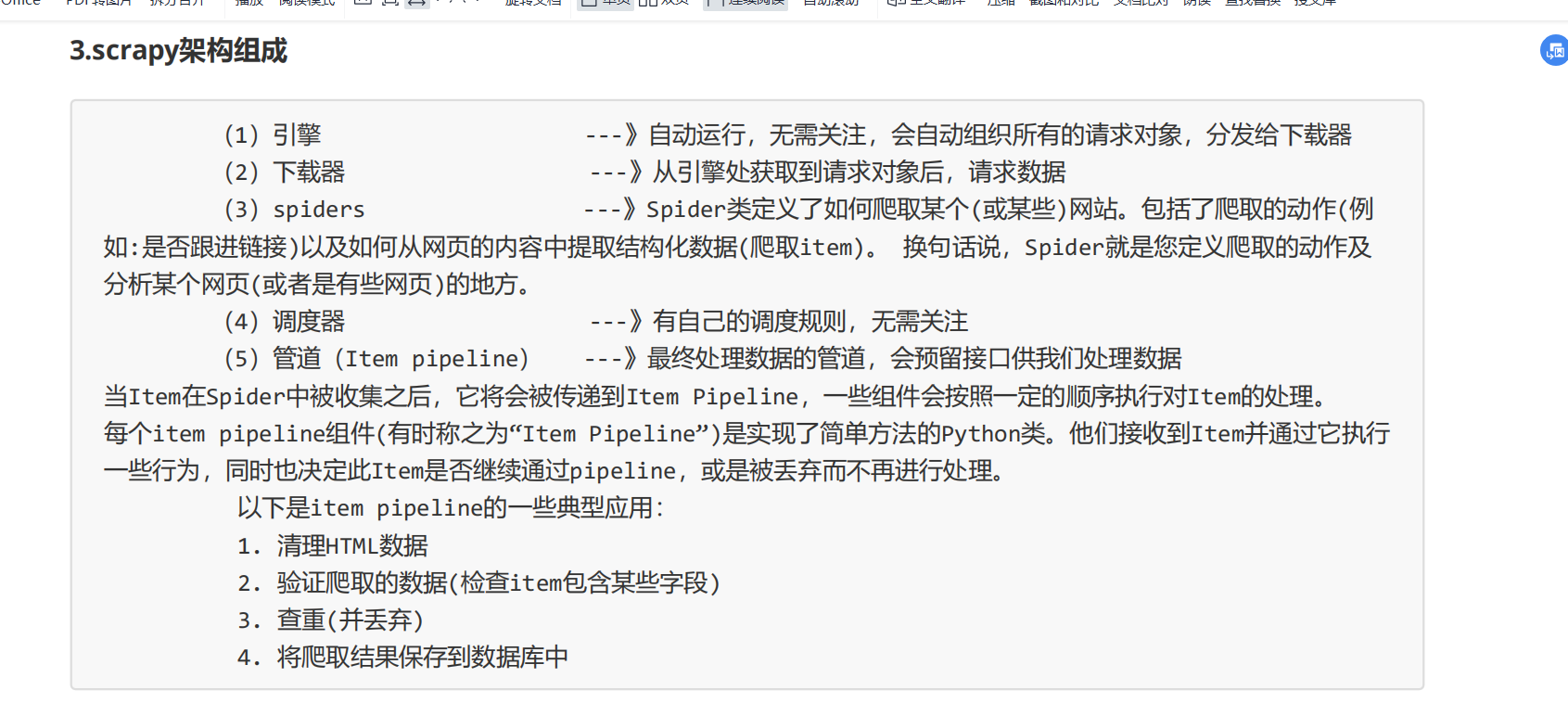
scrapy架构组成:
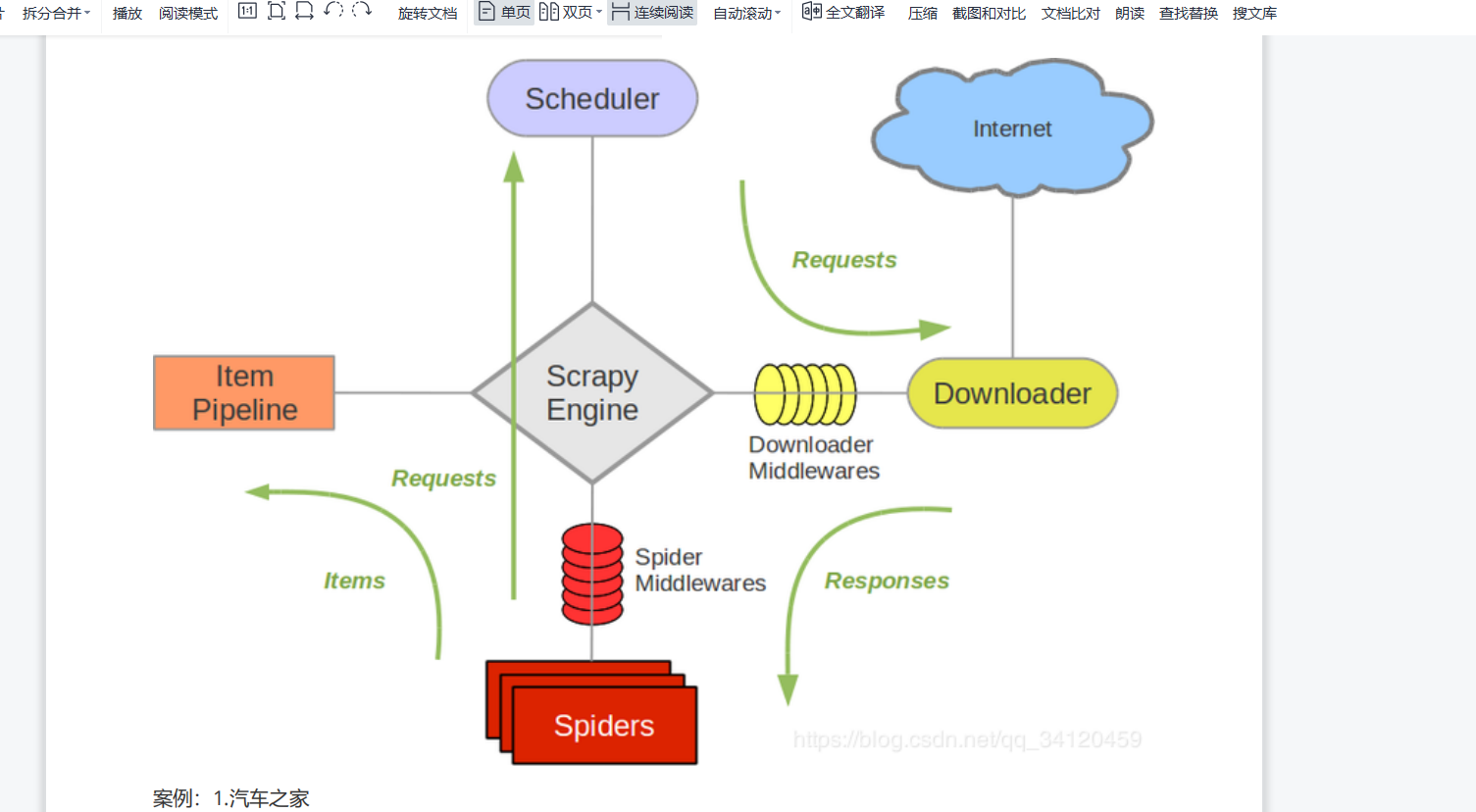
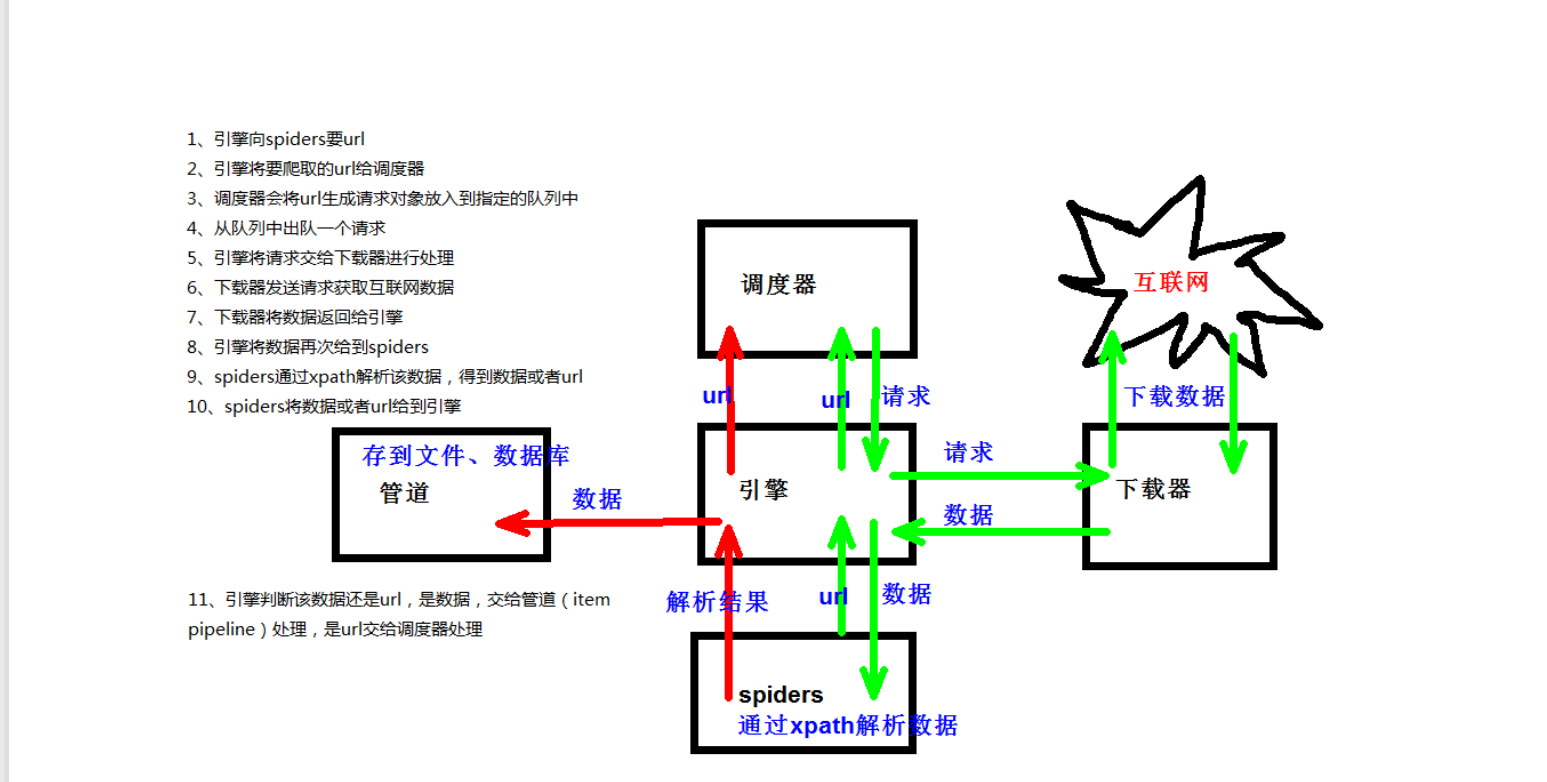
工作原理:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号