scrapy爬虫学习系列四:portia的学习入门
系列文章列表:
scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy01.html
scrapy爬虫学习系列二:scrapy简单爬虫样例学习: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy02.html
scrapy爬虫学习系列三:scrapy部署到scrapyhub上: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_004_scrapyhub.html
scrapy爬虫学习系列四:portia的学习入门: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_010_scrapy04.html
scrapy爬虫学习系列五:图片的抓取和下载: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_011_scrapy05.html
scrapy爬虫学习系列六:官方文档的学习: https://github.com/zhaojiedi1992/My_Study_Scrapy
注意: 我自己新建的一个QQ群(新建的),欢迎大家加入一起学习一起进步 ,群号646187336
portia的简介:
Portia是我们的开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据
scrapyhub上的一些简介视频(需FQ): https://helpdesk.scrapinghub.com/support/solutions/articles/22000201027-learn-portia-video-tutorials-
scrapyhub上的完整入门手册: https://helpdesk.scrapinghub.com/support/solutions/articles/22000200442-using-portia-the-complete-beginner-s-guide
portia官方帮助: http://portia.readthedocs.org/en/2.0-docs/
前言:
本文打算使用scrapy官方提供的demo网页(http://quotes.toscrape.com/page/1/)执行工程创建,这个网页相信大家都很熟悉了。那我们这就开始吧。
注意: 下面图片很多, 难免看不清楚的, 可以使用ctrl+鼠标滚轮缩放网页,方便你更清楚看清图片。
1.打开官网https://app.scrapinghub.com/
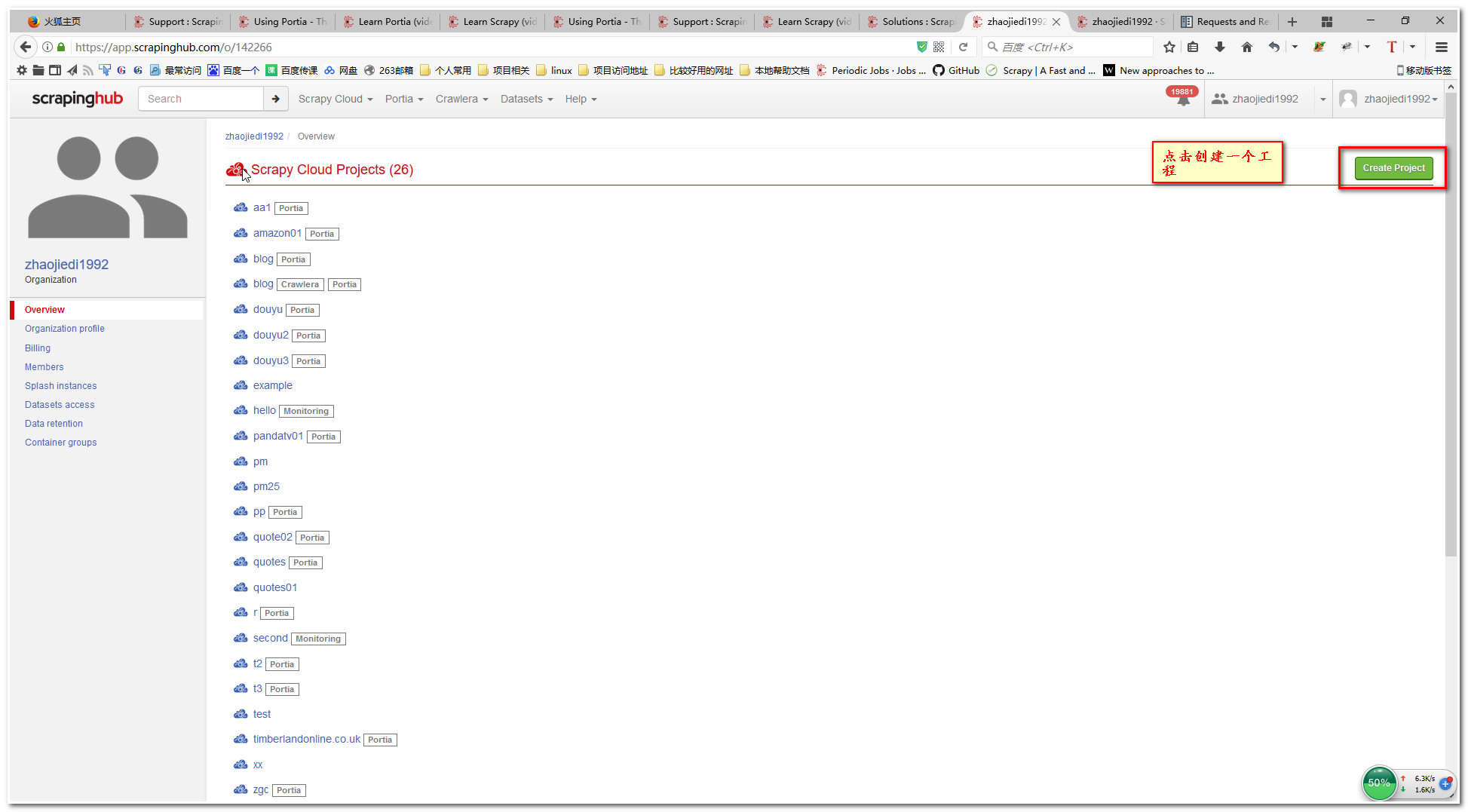
2.创建工程
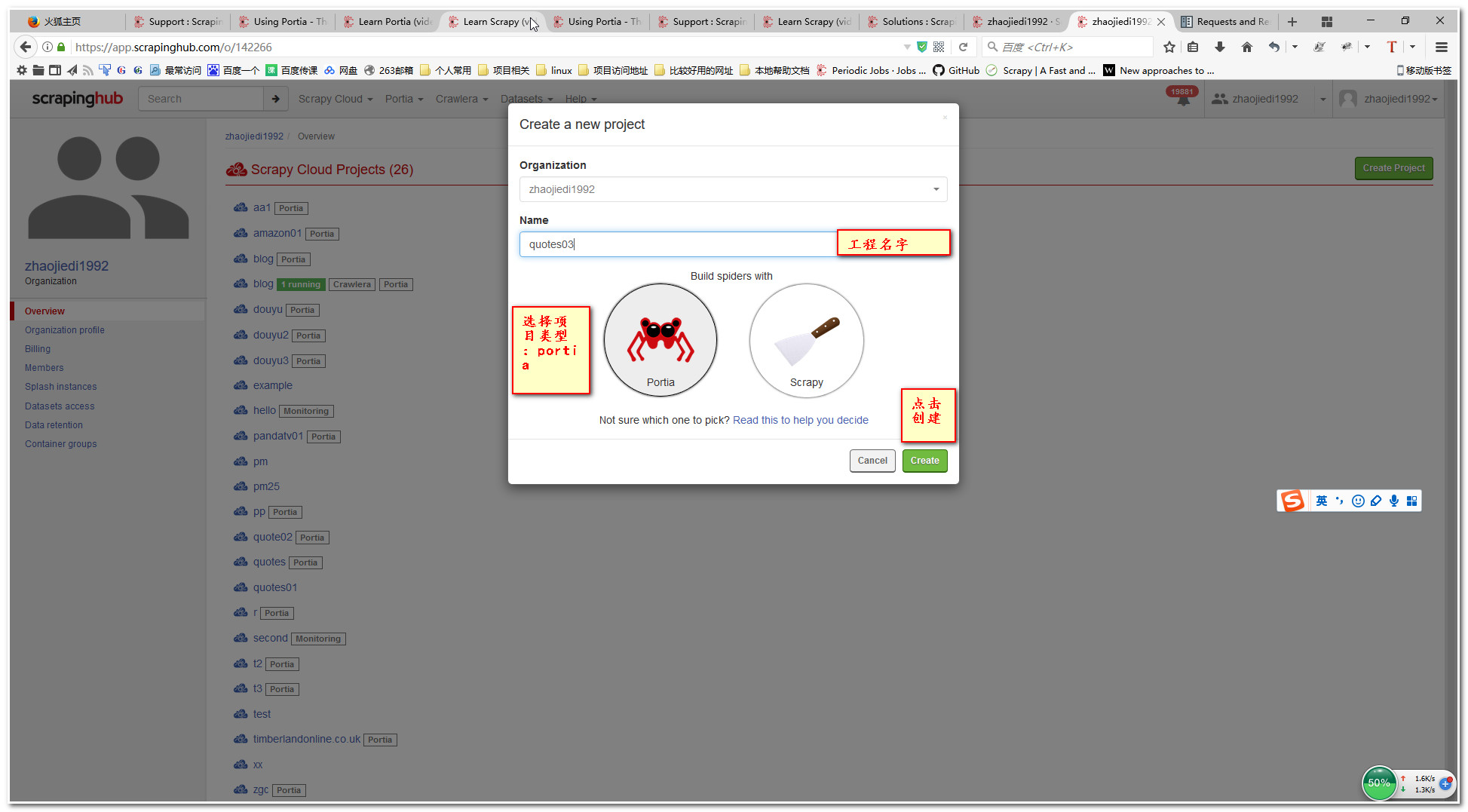
3.设置开始抓取网页
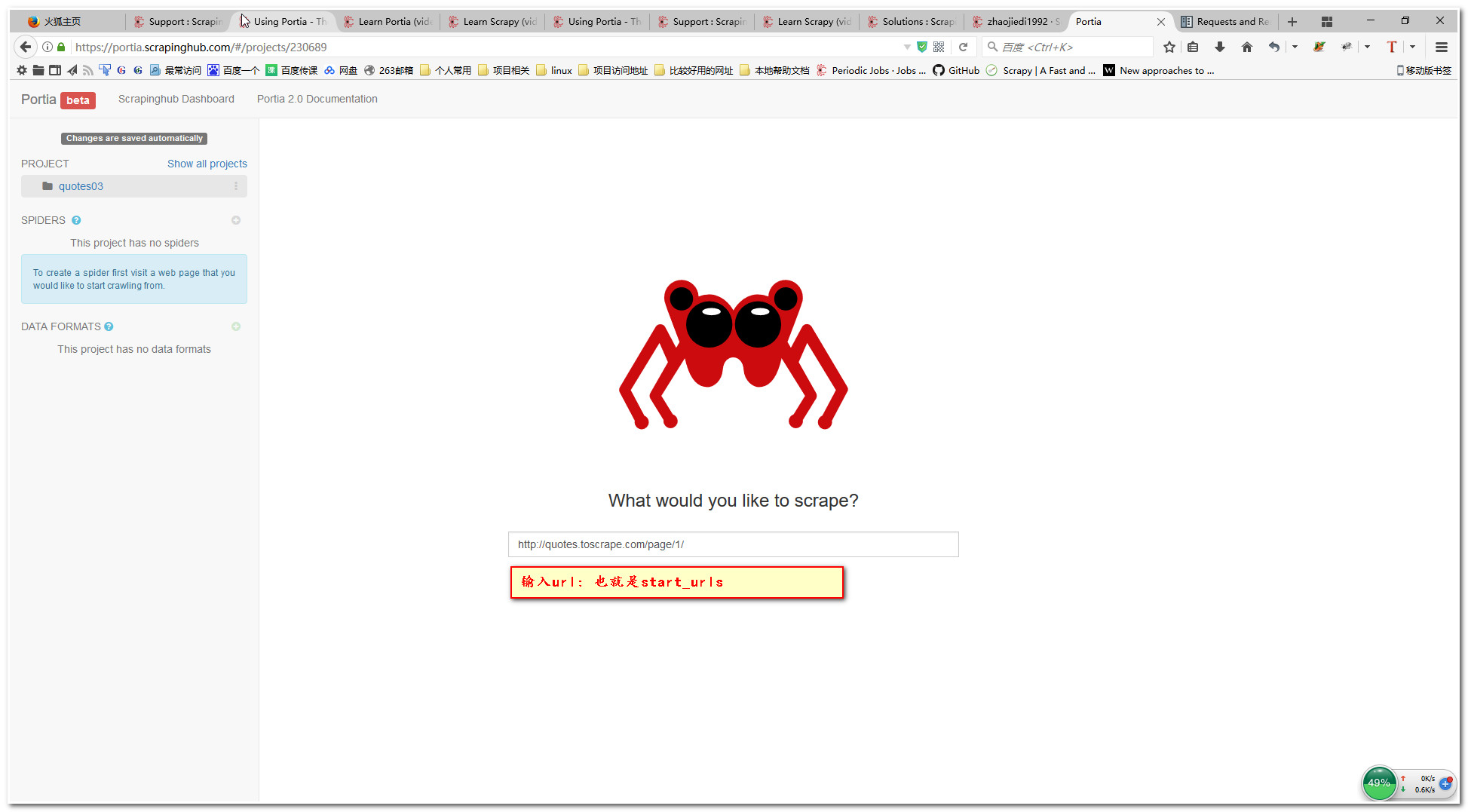
4.创建爬虫
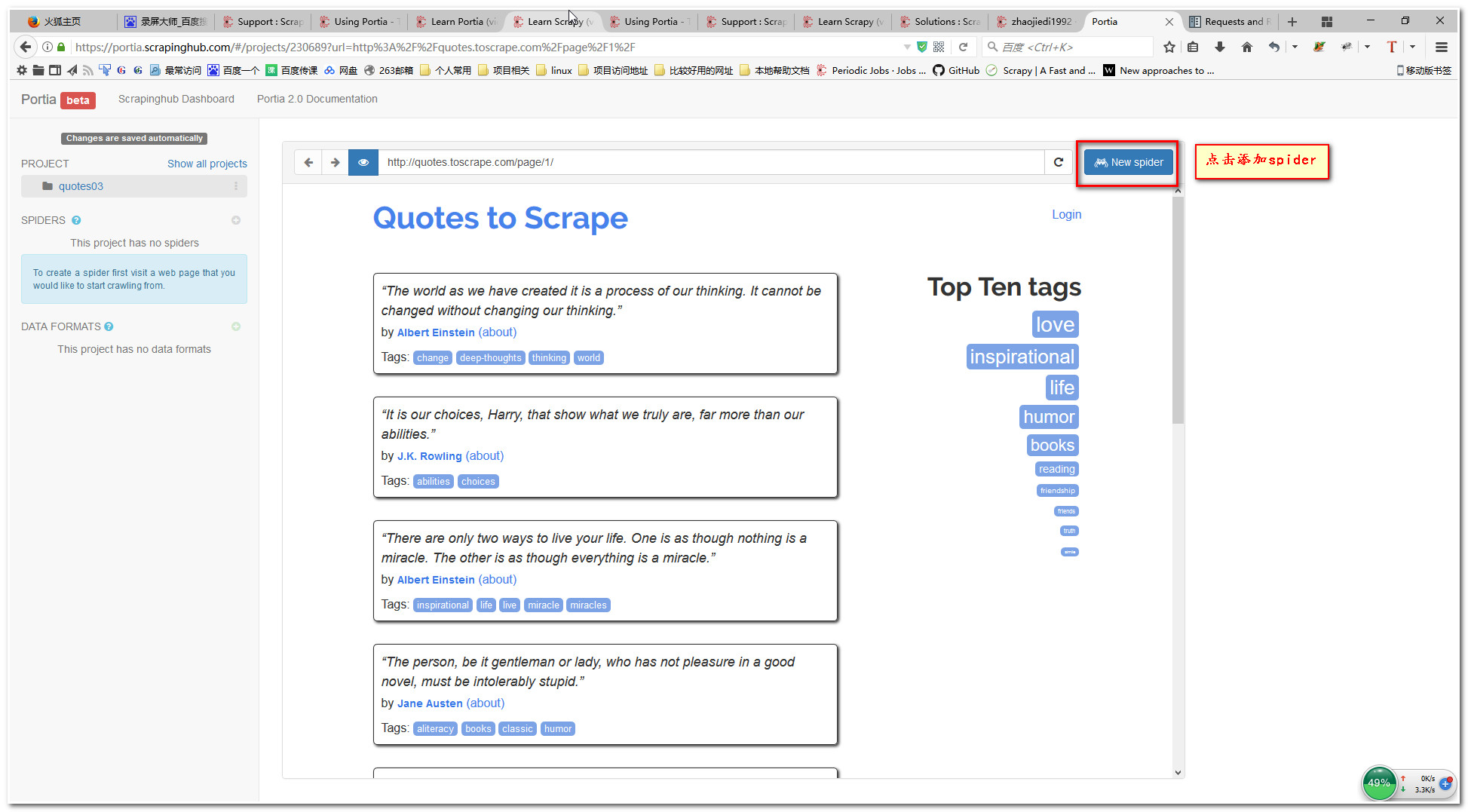
5.创建样例页
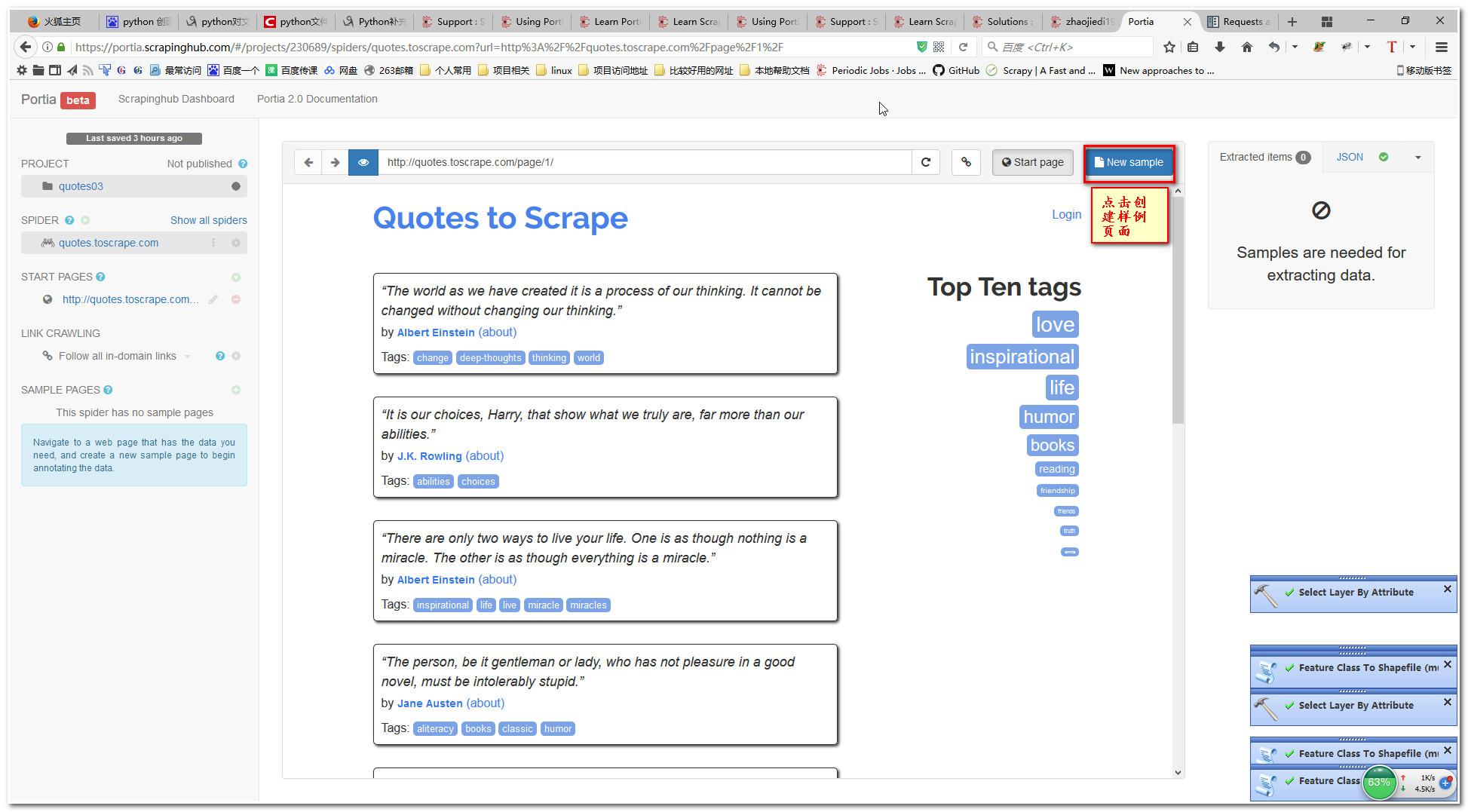
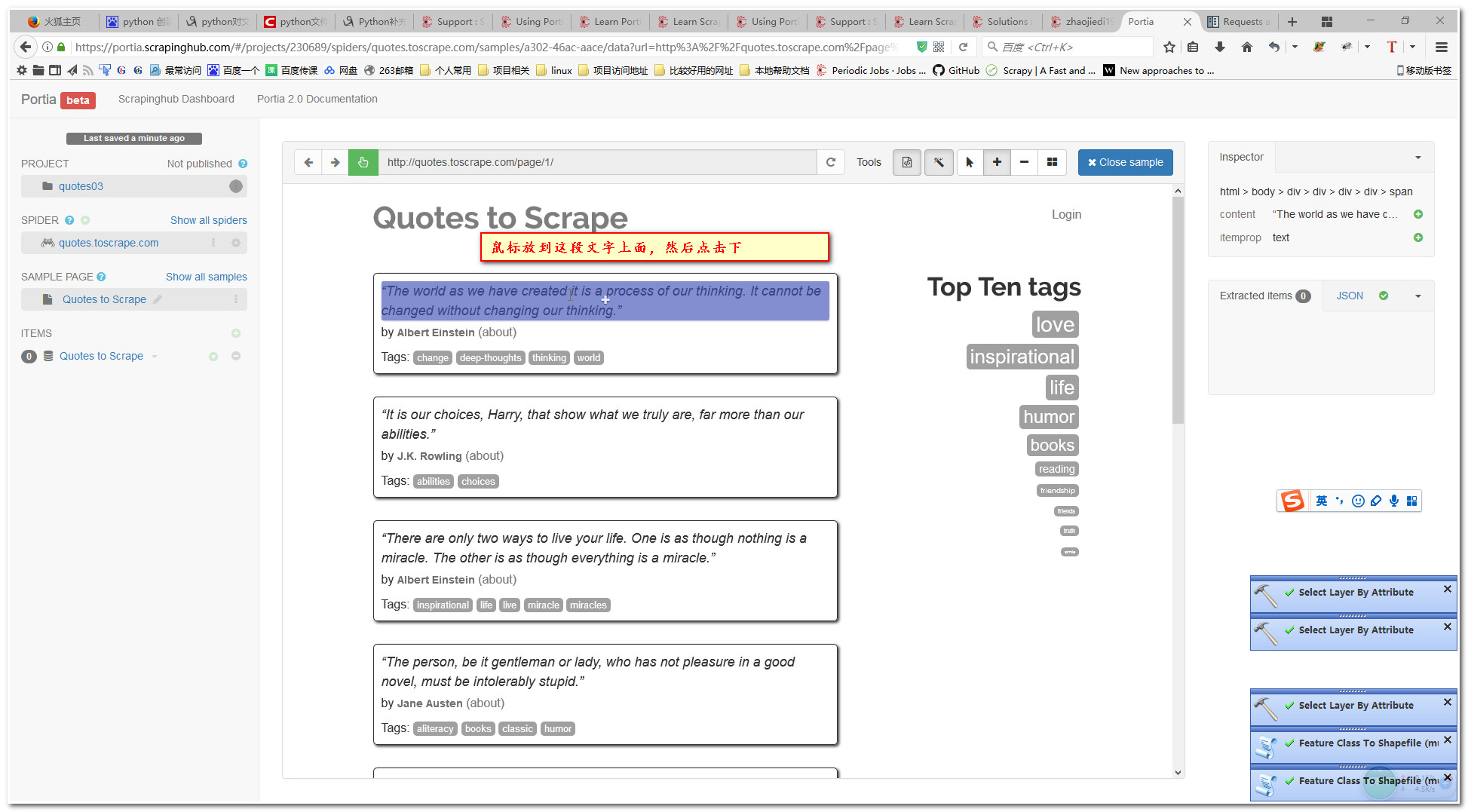
6.设置元素获取方式
6.1添加content字段
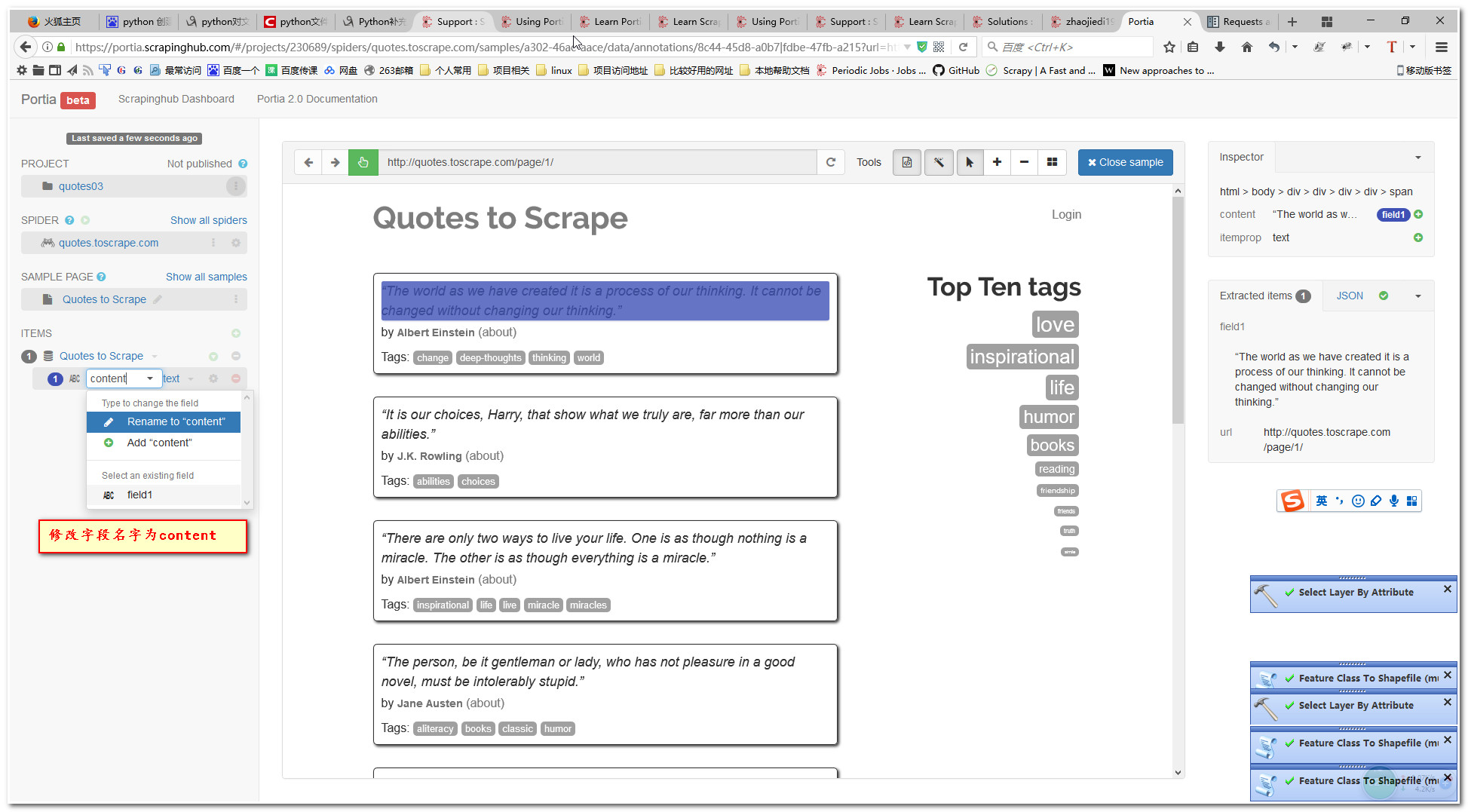
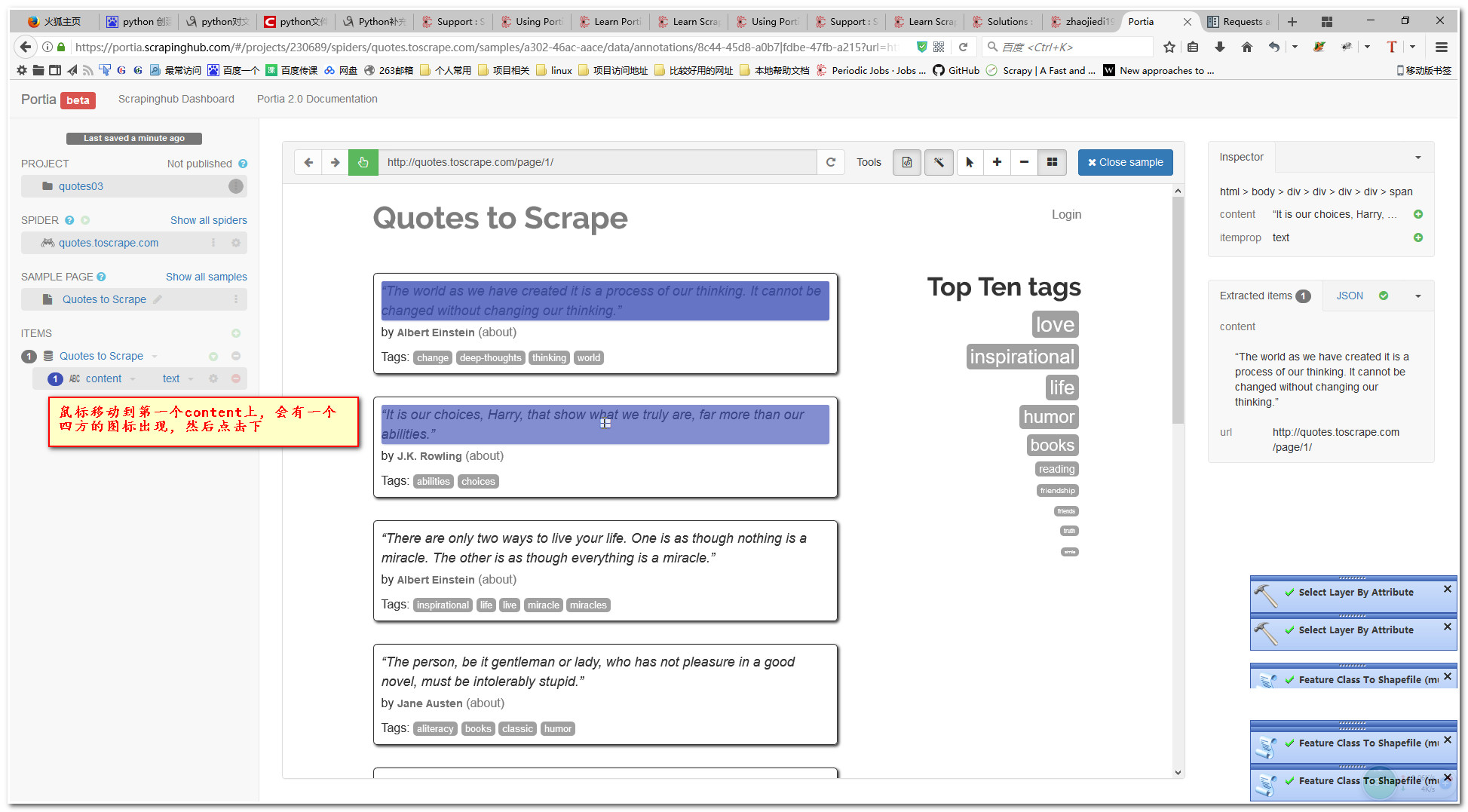
6.2添加author字段
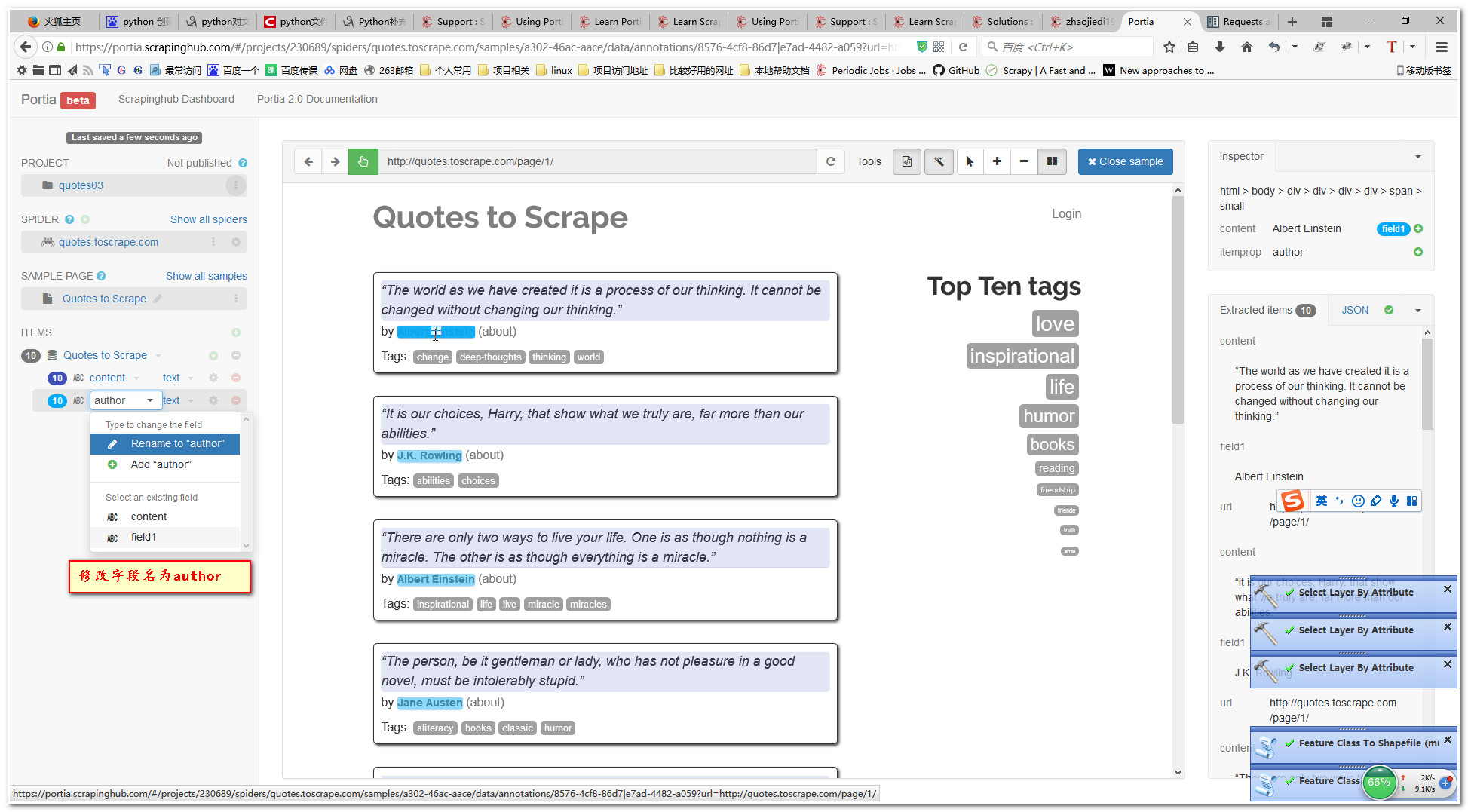
6.3添加tag字段

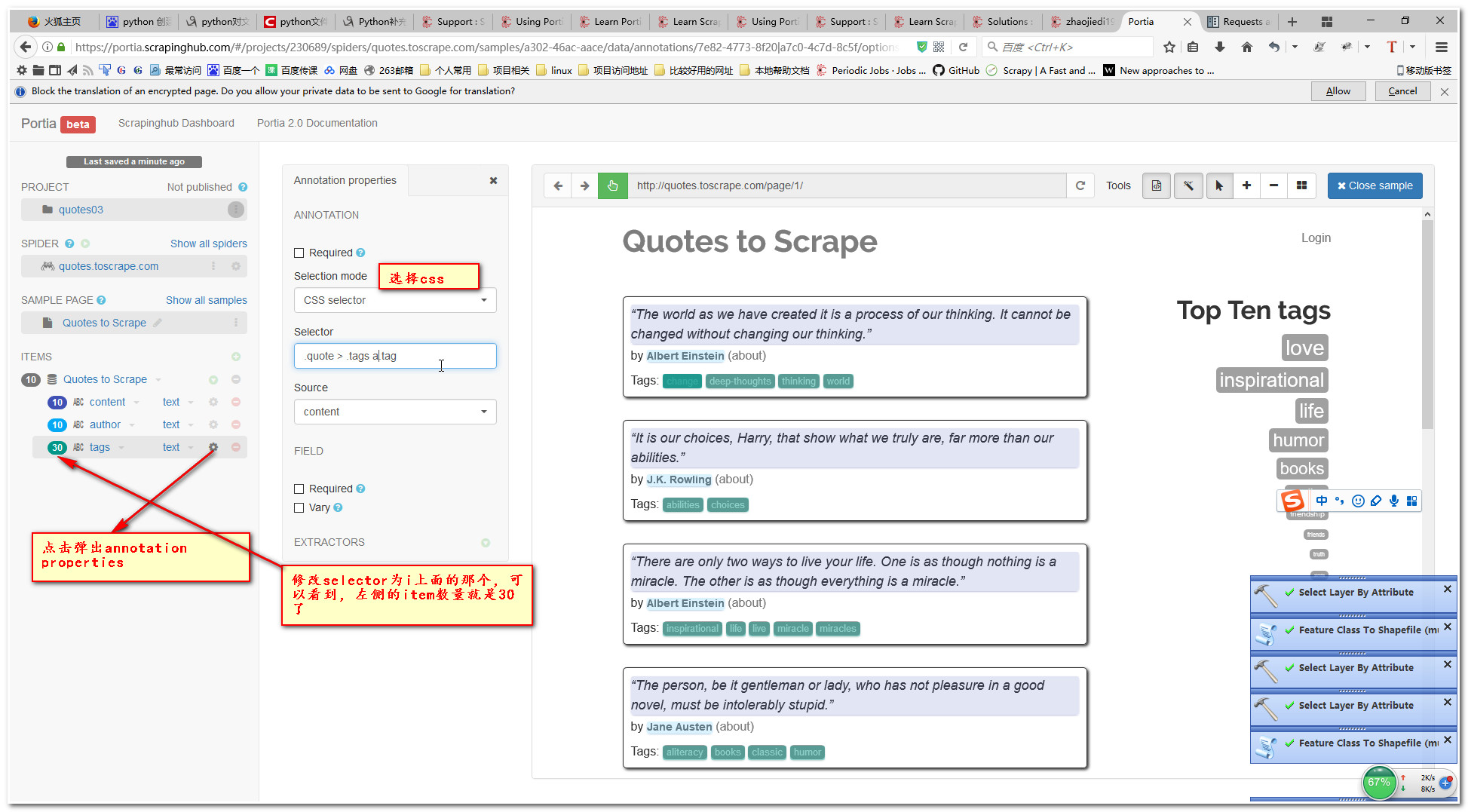
7.运行爬虫
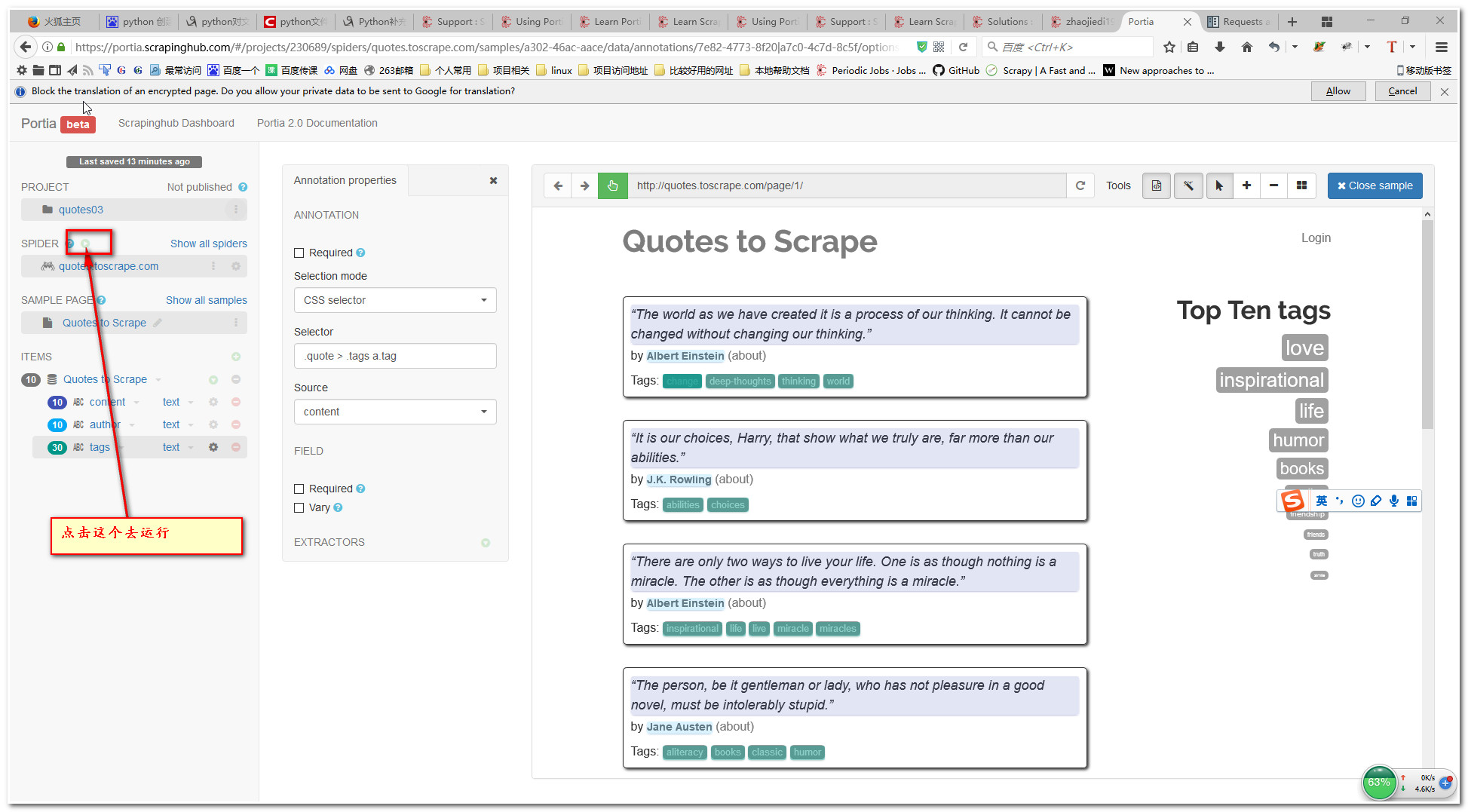
8.查看爬虫结果
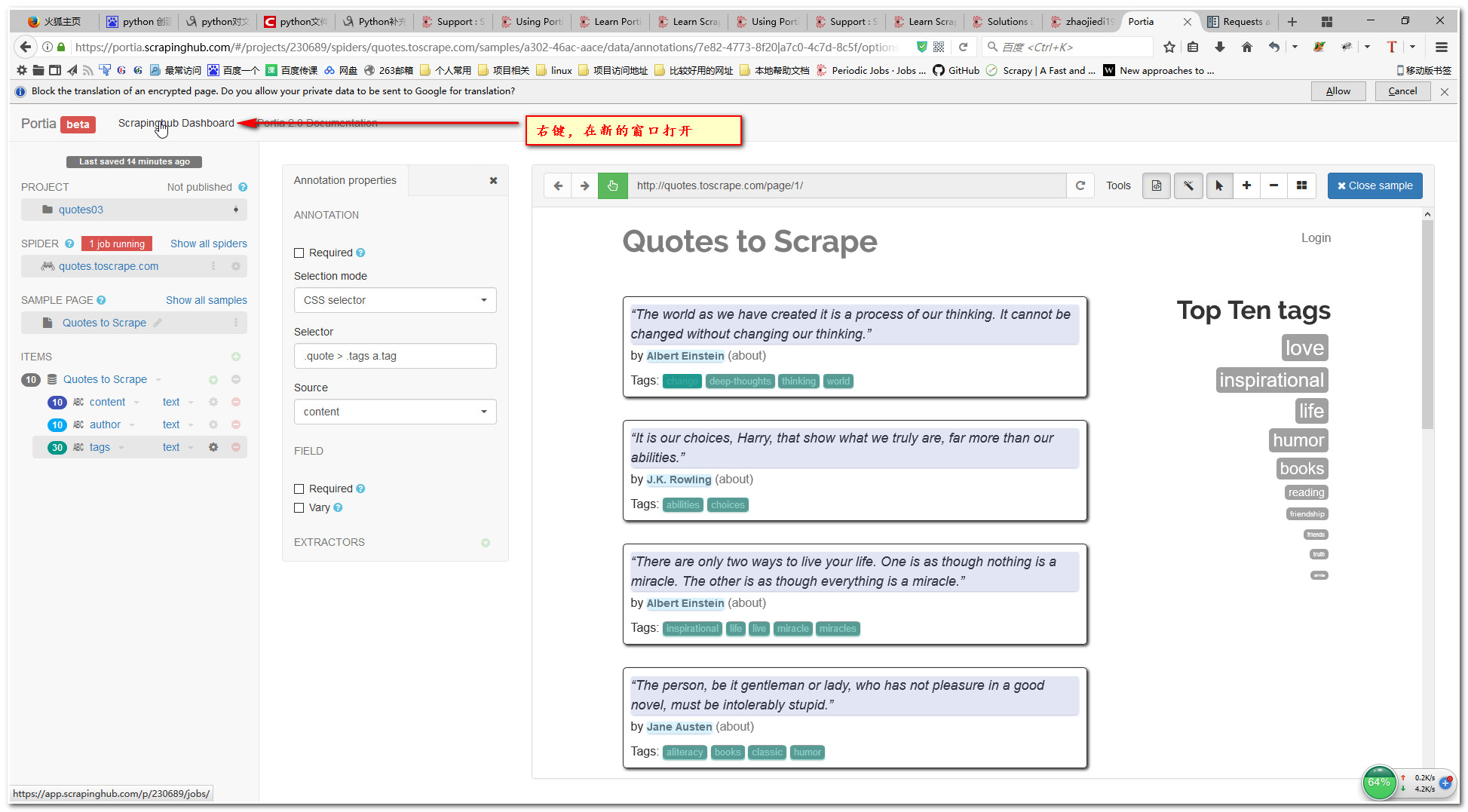
9.查看爬虫运行结果

10.查看item结果
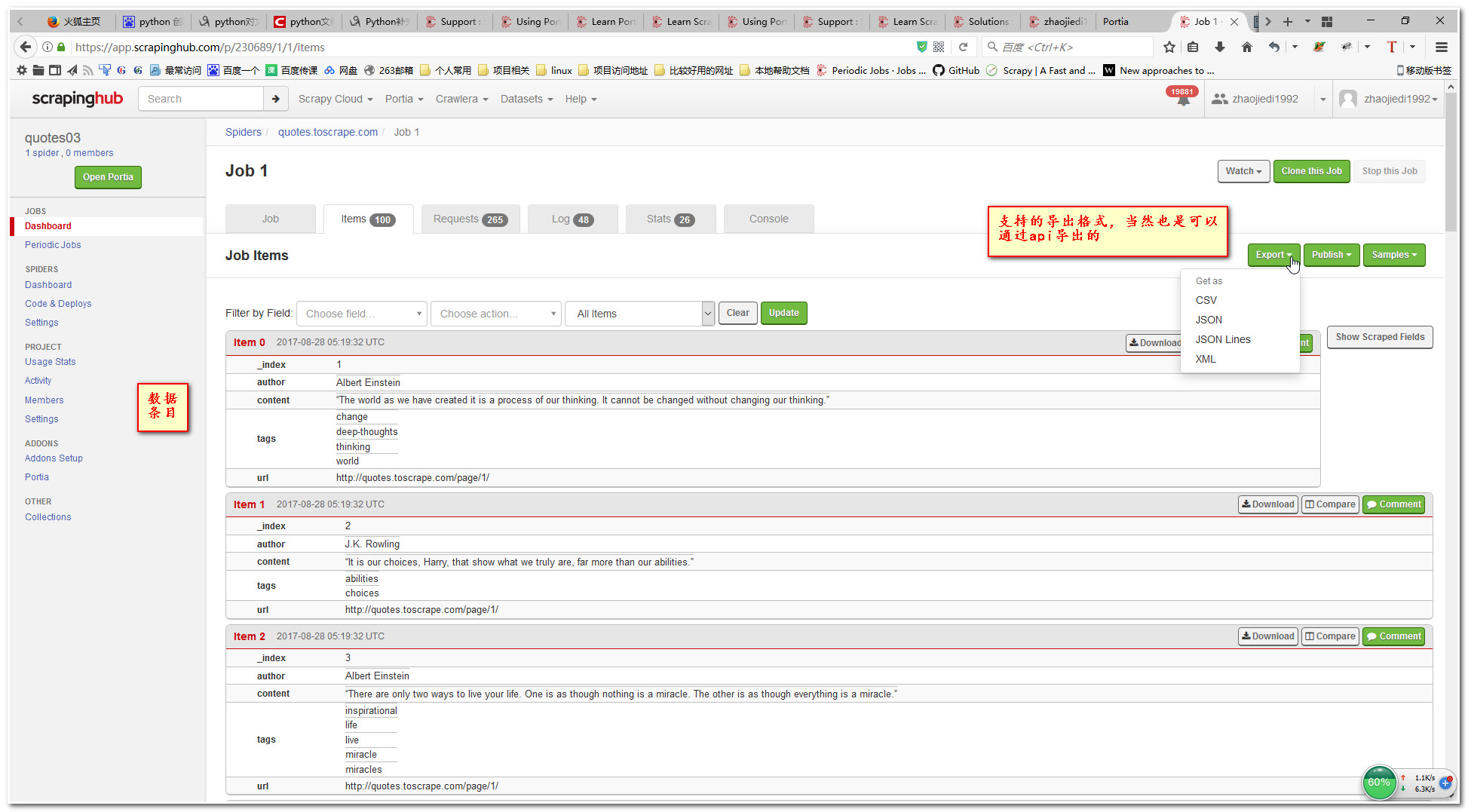
11.下载我们可视化的源码吧
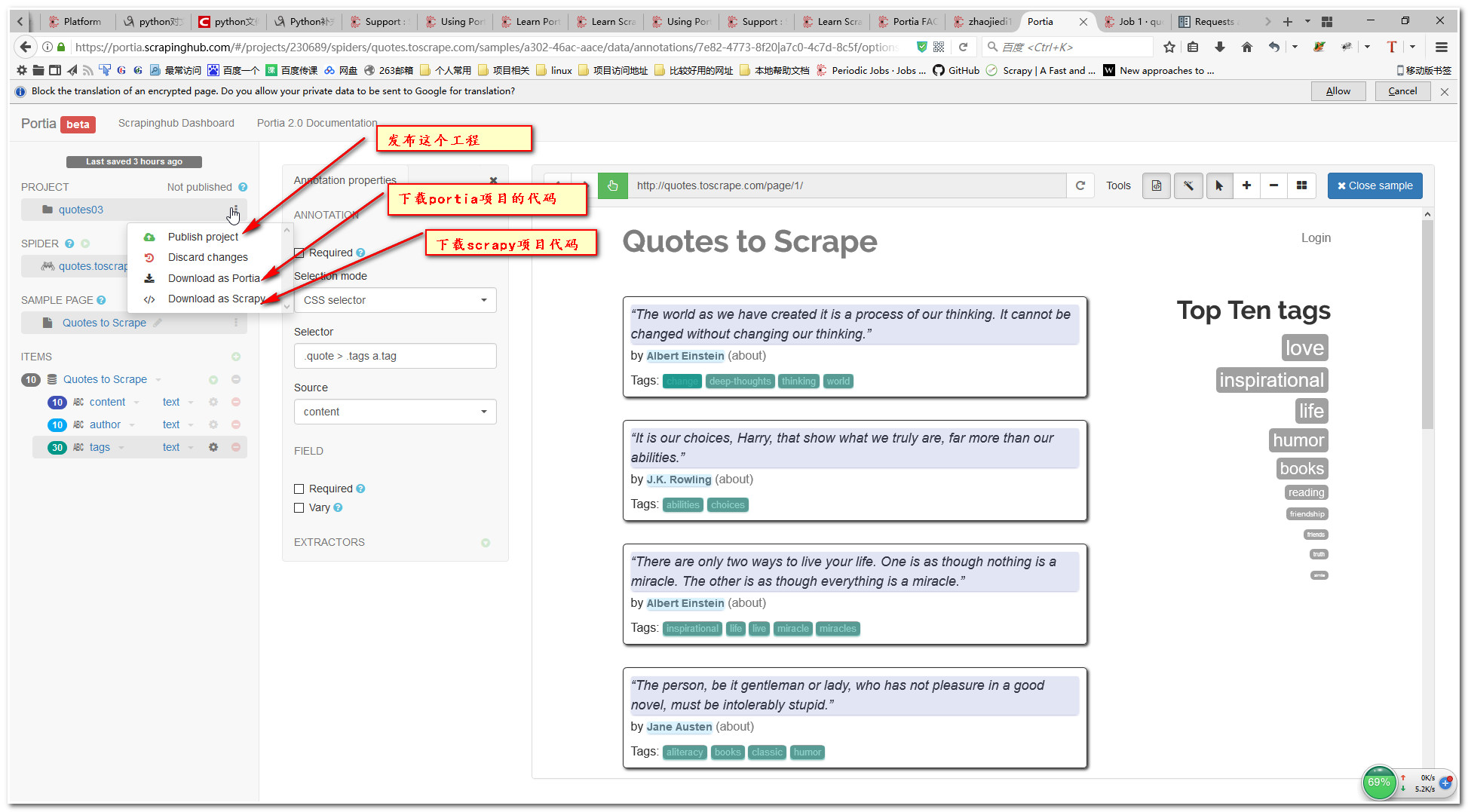
我这个时间下载到的scrapy貌似没法运行,貌似官方网址有点问题,但是portia是可以用的。当然我们可以使用portia2code去转换portia代码为scrapy代码。
好了。我们使用的portia就是可以获取指定网页的数据,详细的大家可以自己摸索摸索。
注意: 现在官方修复了这个问题, 今天我再去下载的时候可以直接使用了。 也就不用protia2code转换了。
posted on 2017-08-28 08:50 LinuxPanda 阅读(9432) 评论(0) 编辑 收藏 举报

