
2023.3.09
今天学习了下python爬虫并简单尝试了一下,现在绝大部分的网站都会反对拒绝来自程序的直接访问,会报错418。那么我们如何使用程序访问呢,那就是骗过去,给自己的headers信息加上网站的user—Agent,这样的话,想要爬的那个网站就会以为你是从某个网址跳转过去的,就不会拒绝你的访问了,因为一般能从网址进入的都会是正常真人。具体怎么操作呢?
首先打开网站,按F12按键可以进入开发模式,或者右键点击检查按钮,也可以进入同样的页面,点击network选项,中文名字叫网络
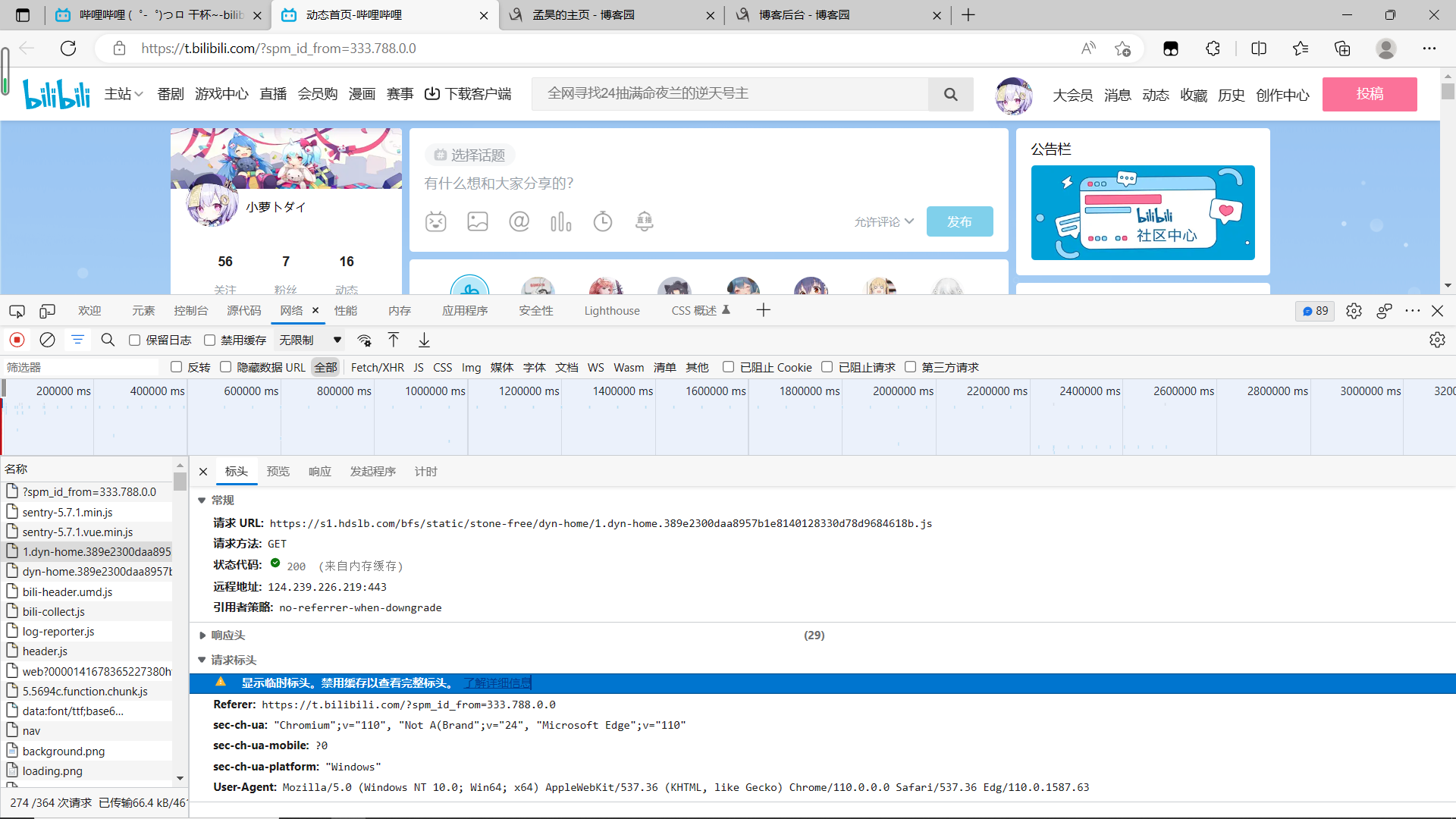
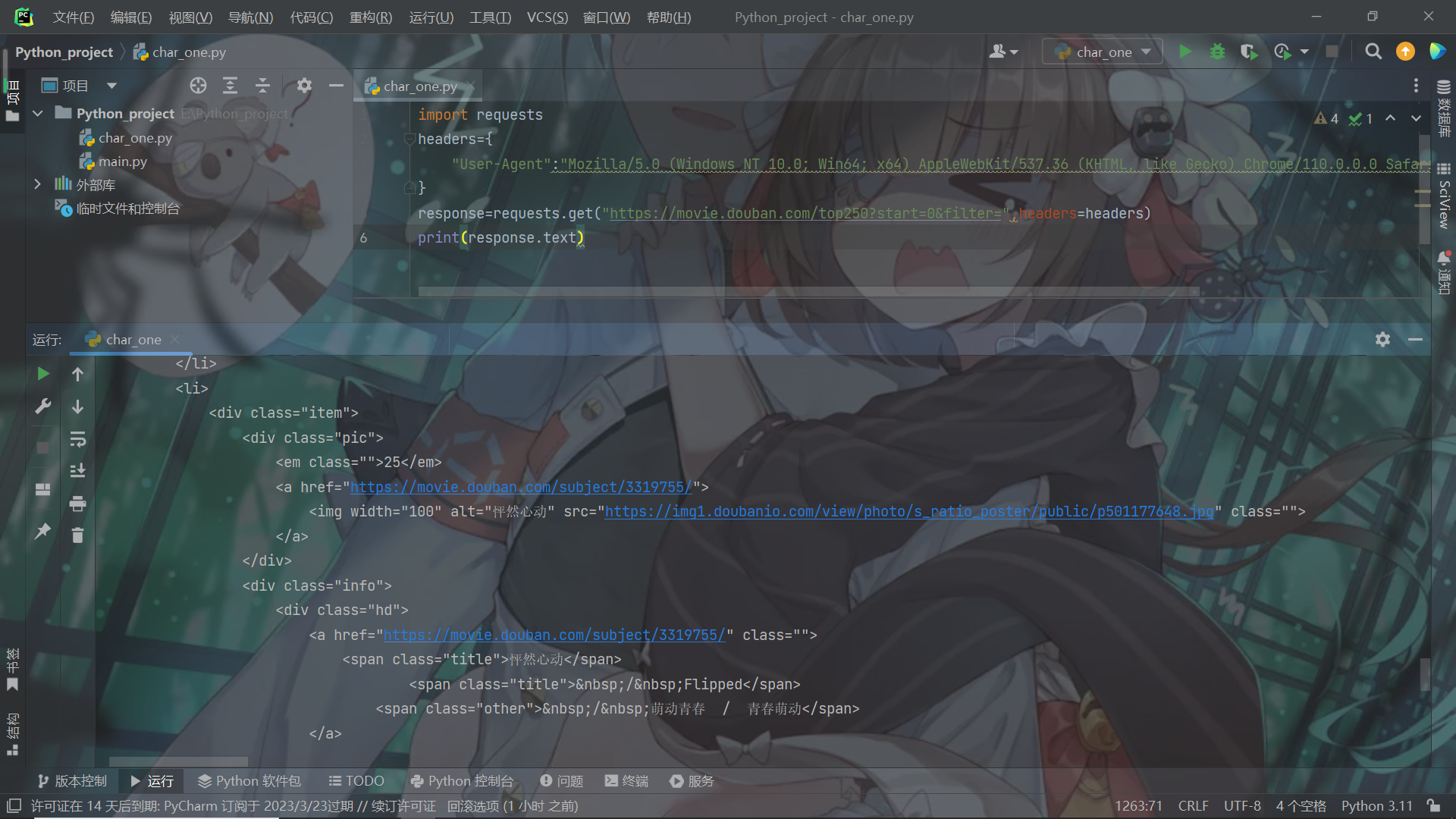
然后刷新当前界面,随机找个http的请求文件,然后打开下拉,找到他的user——Agent,复制后面的内容到自己的代码,就可以使用啦。下面是运行截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号