
03. 检索和重排序
1.Query在文档库中的检索
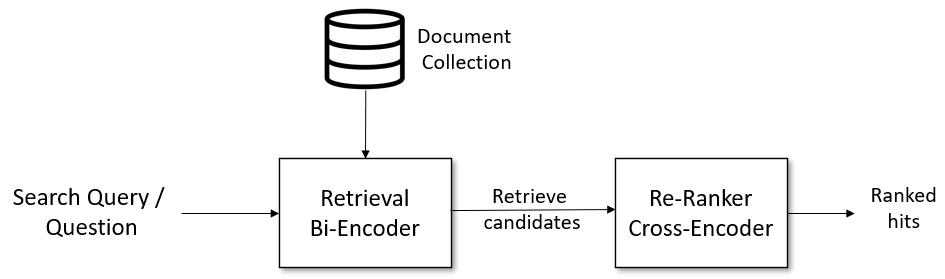
对于复杂的搜索任务,例如问答检索,使用“检索与重排序”可以显著提升搜索效果。对于给定的query,首先在检索系统中初步检索出多个和query相关性较强的chunk块,然后将这多个chunk块再经过重排序算法进行精排。最终得到较为准确的召回结果。在检索问答领域,检索方法一般有:基于Bi-Encoder模型的密集检索和基于ElasticSearch(BM25)的稀疏检索。重排序方法一般有:基于Cross-Encoder排序模型和RRF排序算法。
2. 文档的切分
对于给出的某个query,其答案不可能是整篇文档全部内容,并且当前的Embedding嵌入模型的 max_input_tokens 有限制,所以要对文档进行切分。切分方法:1)固定字符数量切分。2)滑窗法:按标点符号和字符数量切分。3)按照段落结构等其它切分方法。
3. 文本的向量化
3.1 为什么文本向量的余弦相似度能够代表语义相似度
我们在用语言模型无监督训练时,是开了窗口的,通过前n个字预测下一个字的概率,这个n就是窗口的大小,同一个窗口内的词语,会有相似的更新,这些更新会累积,而可替换位置的词语就会把这些相似更新累积到可观的程度。例如,“忐”、“忑”这两个字,几乎是连在一起用的,更新“忐”的同时,几乎也会更新“忑”,因此它们的更新几乎都是相同的,这样“忐”、“忑”的字向量必然几乎是一样的。"我喜欢吃苹果"、"我喜欢吃橘子",这两句话只有宾语不一致,在语料中,"苹果"和"橘子"相较于其它词语更可能获得相似梯度的更新。另外,在一般的泛化语料中,“我喜欢你”中的“喜欢”,以及一般语境下的“喜欢”,替换为“讨厌”后还是一个成立的句子,因此“喜欢”与“讨厌”必然具有相似的词向量,但如果词向量是通过情感分类任务训练的,那么“喜欢”与“讨厌”就会有差异较大的词向量。可以说:文本的向量化模型效果是和训练任务关联的。
3.2 向量化模型
最开始的文本向量化模型是Word2Vector,后面的文本向量化模型权重主要来源于 基于Bert结构的NLP任务的副产物。
接3.1结尾,这也是为什么:在Rag中,经过retriever之后,得到的召回结果还需要 精排&rank模型微调 的原因。
4. 快速检索
为了加快检索速度,降低响应时长。在Rag问答中,可以 1)优先检索存储的问答对,然后用 rag 兜底。2)在rag中,用Redis存储历史查询结果。另外,在检索中,如果必要的话,完全可以关联多个知识库。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号