

vue3的优化
更好的代码管理方式:monorepo代码管理
- 相对于vuejs 2.x的源码组织方式,monorepo吧这些模块拆分出来到不同package中
- 每个package有各自的API,类型定义和测试
- 这样是模块拆分更细化,职责划分更加明确,模块之间的依赖关系也更加明确
- 开发人员也更容易阅读理解和更改所有模块的源码,提高代码的可维护性
- package(比如reactivity响应式库)可以独立于vuejs使用
性能优化 vue3.0
- 移除一些冷门feature
- 引入tree-shaking的技术(通过编译阶段的静态分析,找到没有引入的模块并打上标记,没有引入就不会打包)
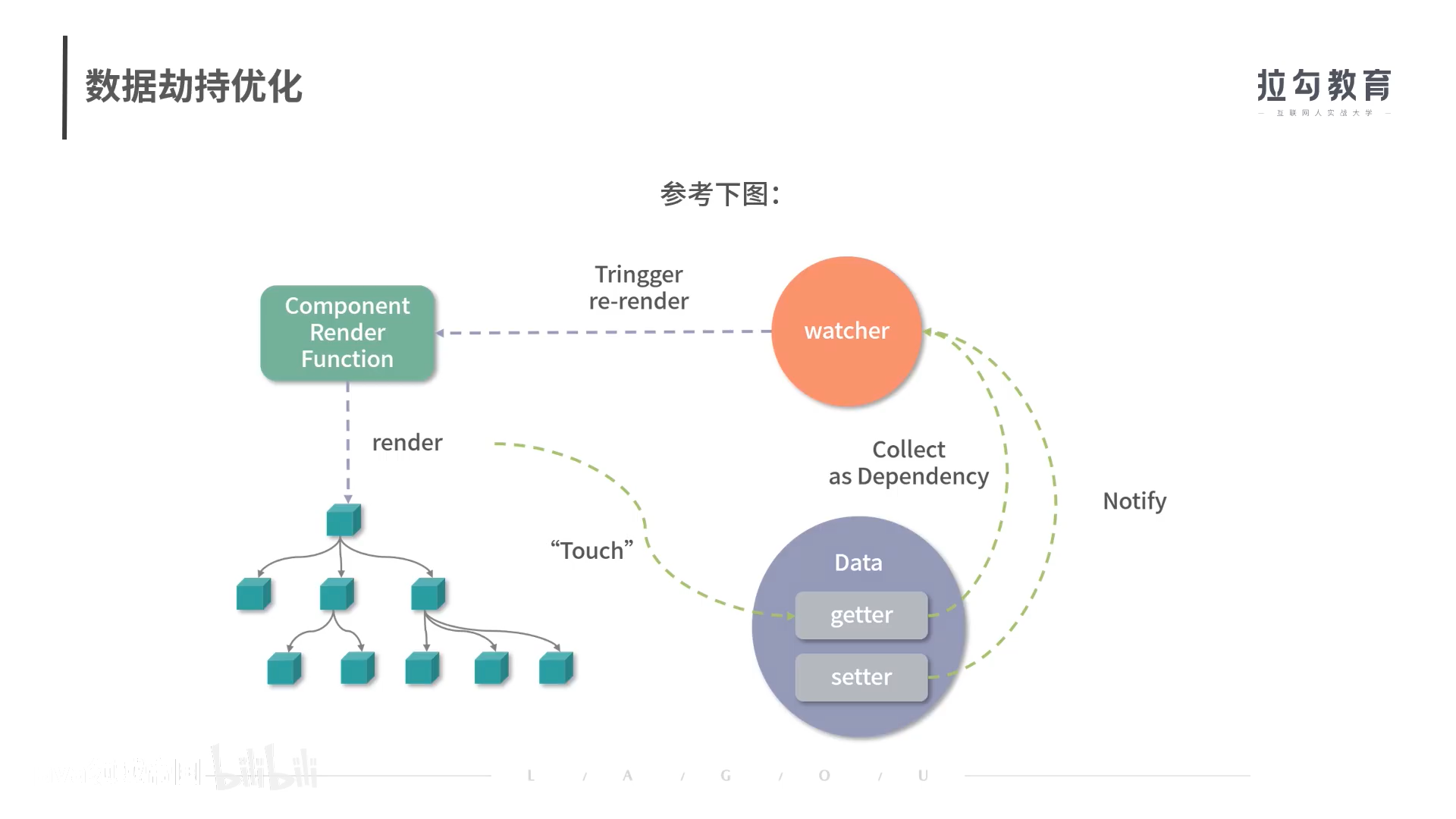
数据劫持优化
-
数据是响应式的,实现DOM功能,必须劫持数据的访问和更新
-
当数据改变后,为了自动更新DOM,那么就必须劫持数据的更新,也就是说当数据发生改变后自动执行一些代码更新DOM
-
因为在渲染DOM的时候访问了数据,我们就可以对他进行访问劫持。这样在内部建立依赖关系,也就知道数据对应DOM是什么了
![]()
-
vue2.js通过Object.defineProperty() 这个API劫持数据的getter和setter
-
他必须知道拦截的key是什么,并不能检测添加和删除
Object.defineProperty(data,'a',{
get(){
// track 跟踪
},
set(){
// trigger 触发
}
})
- 嵌套层级比较深的对象,要把每一层对象都变成响应式的
- vue3 使用Proxy API 做数据劫持的他的内部
Observed = new Proxy(data,{
get(){
// track 跟踪
},
set(){
// trigger 触发
}
})
- 注意的是,proxyAPI并不能监听到内部深层次的对象变化
- 因此vue3处理方式在getter中递归响应式,这样的好处是真正访问到内部对象才会变成响应式,而不是无脑递归,这样无疑也在很大程度提升性能。
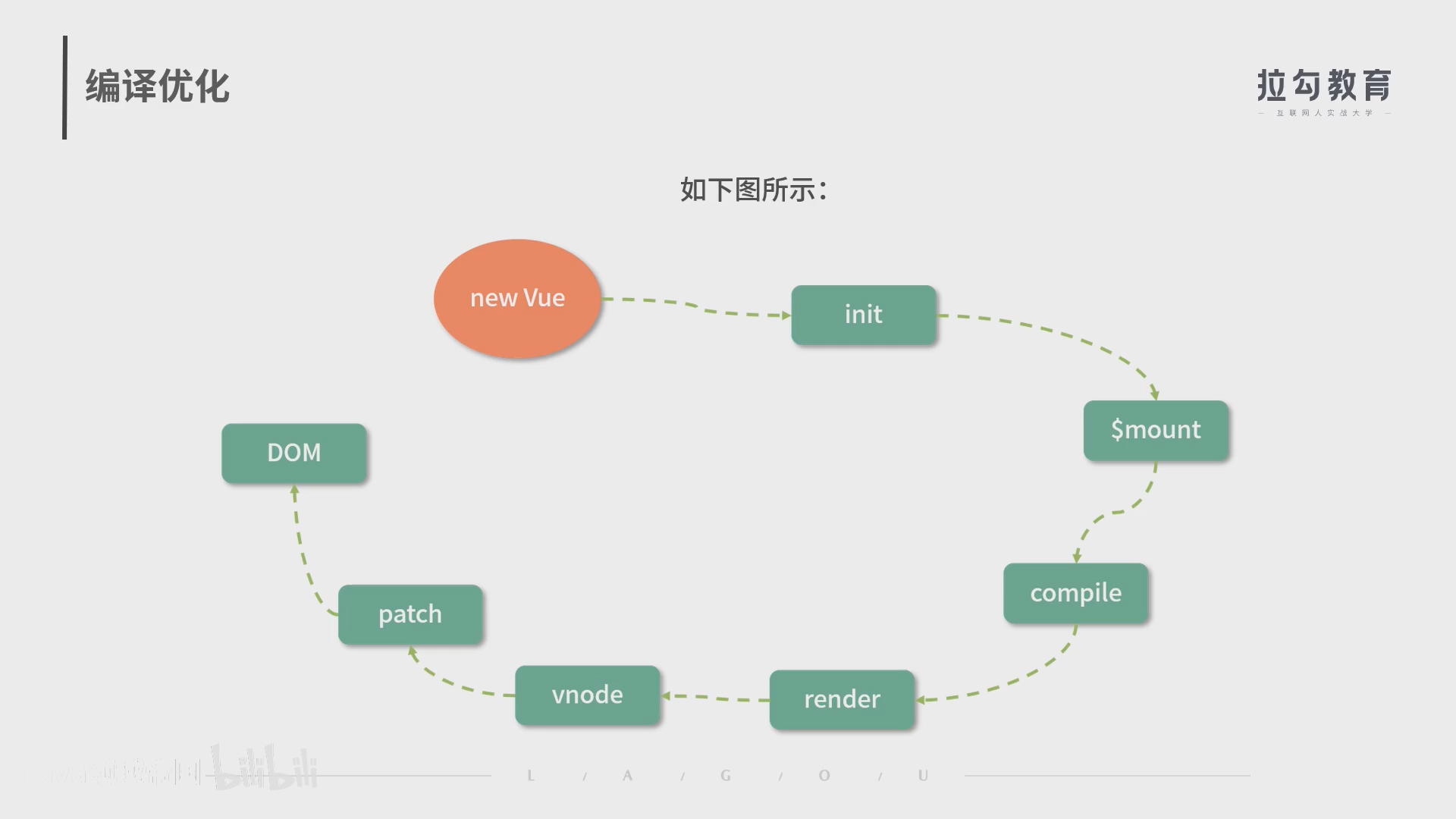
编译优化
- vue3操作DOM流程
![]()
- 除了数据劫持部分优化,我们可以在耗时相对较多的patch阶段想办法,通过编译阶段优化编译的结果,实现运行时patch过程的优化。
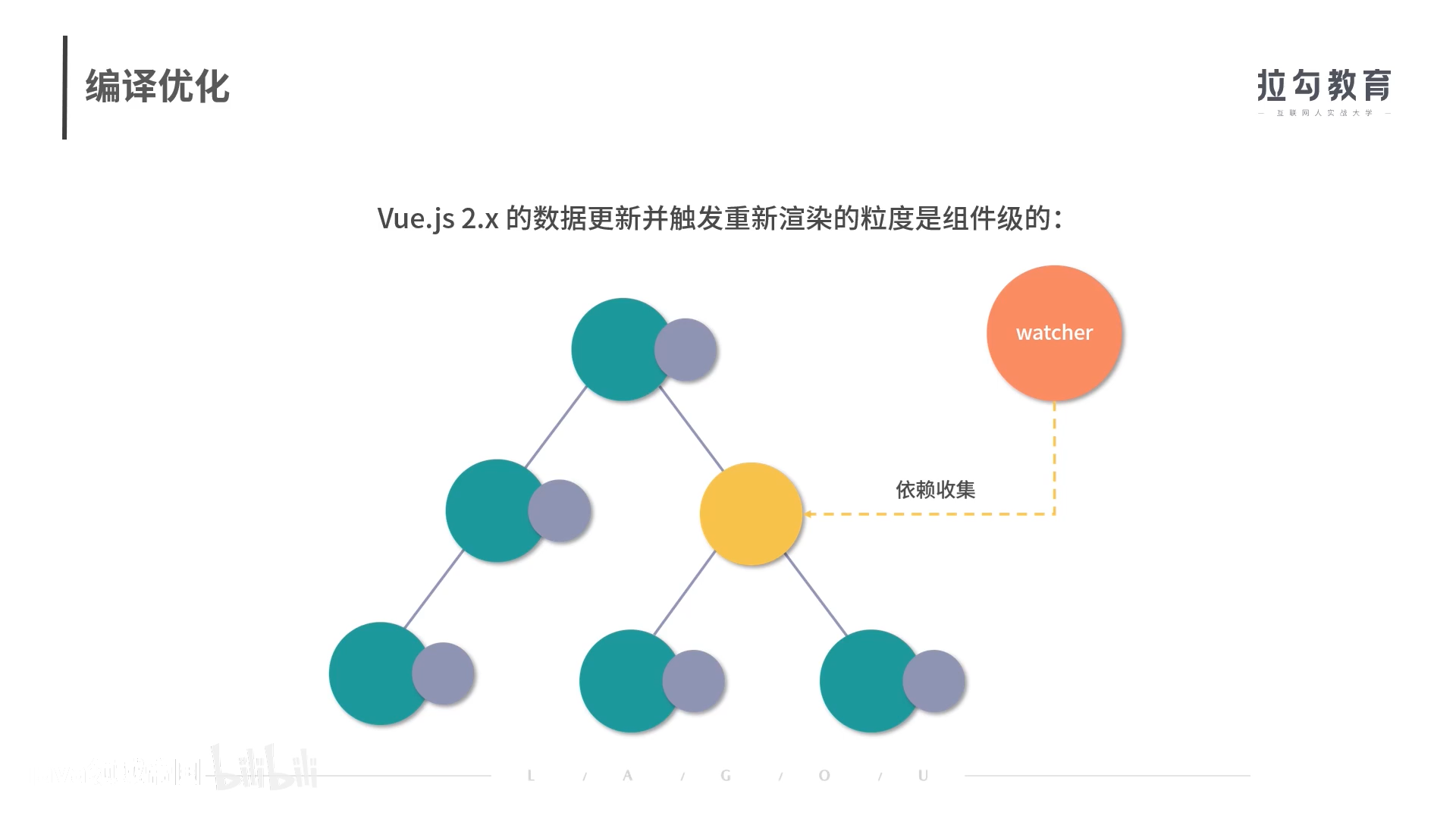
- vue2的数据更新并触发重新渲染的粒度时组件级
![]()
<template>
<div id="content>
<p class="text">static text</p>
<p class="text">static text</p>
<p class="text">static text</p>
<p class="text">{{message}}</p>
<p class="text">static text</p>
</div>
</template>
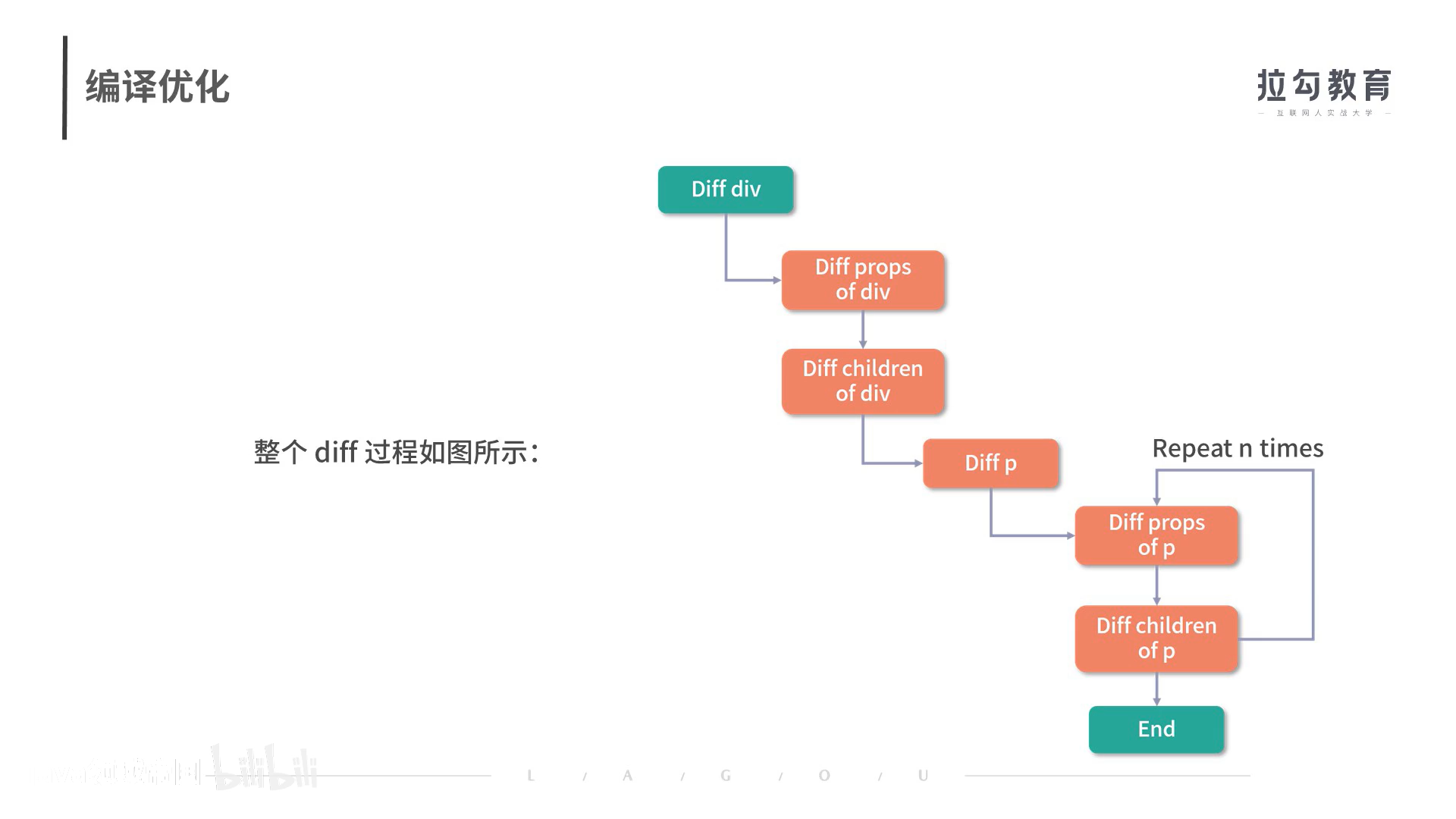
- 有很多vnode遍历是浪费的
- vue3 通过编译阶段对静态模板的分析,编译生成了Block tree
Block tree
- Block tree 是一个将模板基于动态节点的指令切割嵌套区块,每个区块内部的节点结构是固定的,每个区块只需要以一个Array来追踪自身包含的动态节点
- 借助Block tree将vnode更新性能由与模板整体大小相关提升为与动态内容的数量相关
- 在编译阶段还包含对Slot的编译优化,事件监听的缓存优化并且在运行时重写了diff算法
语法API优化 Composition API
- 之前版本使用 OptionAPI 写法符合直觉思维。
- 组件小时候一目了然,但是在大型组件中一个组件可能由多个逻辑关注点,就需要在单文件上下寻找
- Composition API 就是将逻关注相关代码辑放在一个函数中,就不需要挑来跳去
逻辑复用mixin问题
- 当有大量mixin 会出现命名冲突和数据来源不清晰的问题
- 首先每个mixin都可以定义自己的props,data,他们之间是无感的所以很容易定义相同变量,导致命名冲突
- 对于组件而言,如果模板中使用不在当前组件中定义的变量,那么就会不太容易知道这些变量在哪里定义的,这就是数据来源不清晰
- vue3js 改变是用用hooks函数来代替,更加清晰直观
- 除了逻辑方面优势,也有更好的类型支持
- 因为他们都是一些函数,在调用函数时,自然所有的类型就被推导出来了,不像optionsAPI所有东西使用this
- 另外CompositionAPI对tree-shaking友好,代码也更容易压缩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号