
第一次个人编程作业
https://github.com/zhangzh123455/zzh/tree/main/031902531
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 240 |
| · Design Spec | · 生成设计文档 | 40 | 40 |
| · Design Review | · 设计复审 | 15 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 90 | 180 |
| · Code Review | · 代码复审 | 20 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 15 | 20 |
| Reporting | 报告 | 30 | 40 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 560 | 830 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
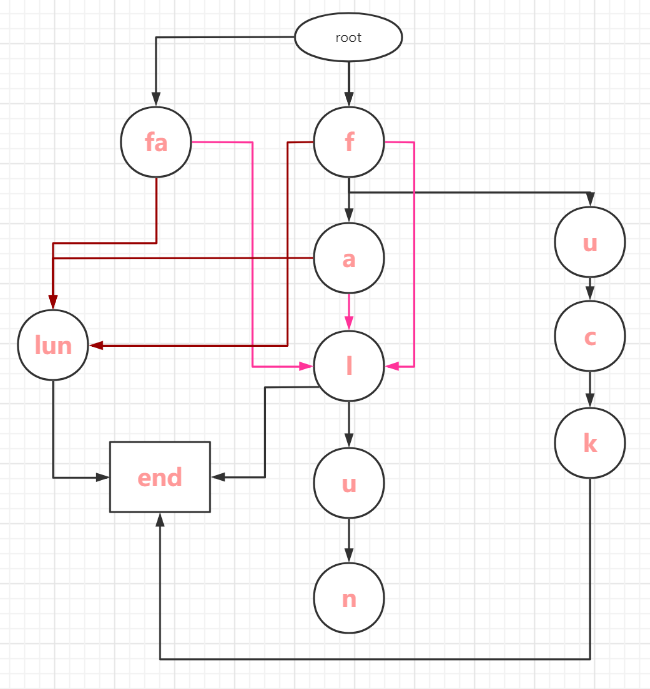
代码中设置了两个类,一个类用来存放类的结点,一个类用来构成一个敏感词树。结点类中有一个son的字典元素,字典的key用来存放敏感词,字典的value用来存放Mgc_treenode(key),即敏感词的结点。
树的类中设置了两个函数,一个函数用于插入敏感词,其中英文敏感词正常插入即可,而中文的敏感词需要考虑拼音、拼音拆分、拼音缩写等情况,建树的情况较为复杂。下面用图片更直观地说明。另一个函数用于查找敏感词并将其输出。关于汉字拆分的功能由于个人能力不足(实在看不大懂),后续有时间看看能不能回来补上吧
下面是“法轮”和“fuck”的建树效果:
查找函数的大致思想就是,创建一个p结点,最开始p->root从文本中一个个字符读取,并把他们拼音化,如果出现拼音化后的字符串在p的son字典中,则记录start,p变成他对应的子节点,遇到无关字符跳过即可,到最后如果遇到尾结点标志,则可以记录end,并检查是否是最长匹配,是则将其存储在一个列表中,方便输出。
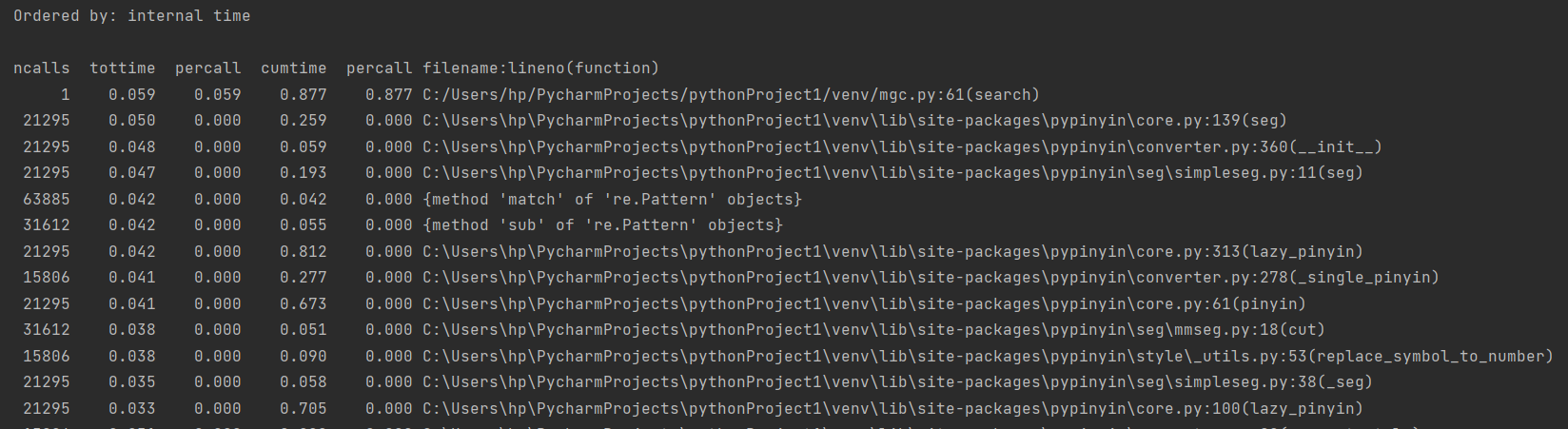
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
从图片中可以看到,程序中消耗最大的函数是lazy_pinyin,优化方法是自己写一个中文转拼音的函数,但是由于lazy_pinyin是Python上可以直接使用的库函数,就没有再特意去自己写了。(主要还是lazy)
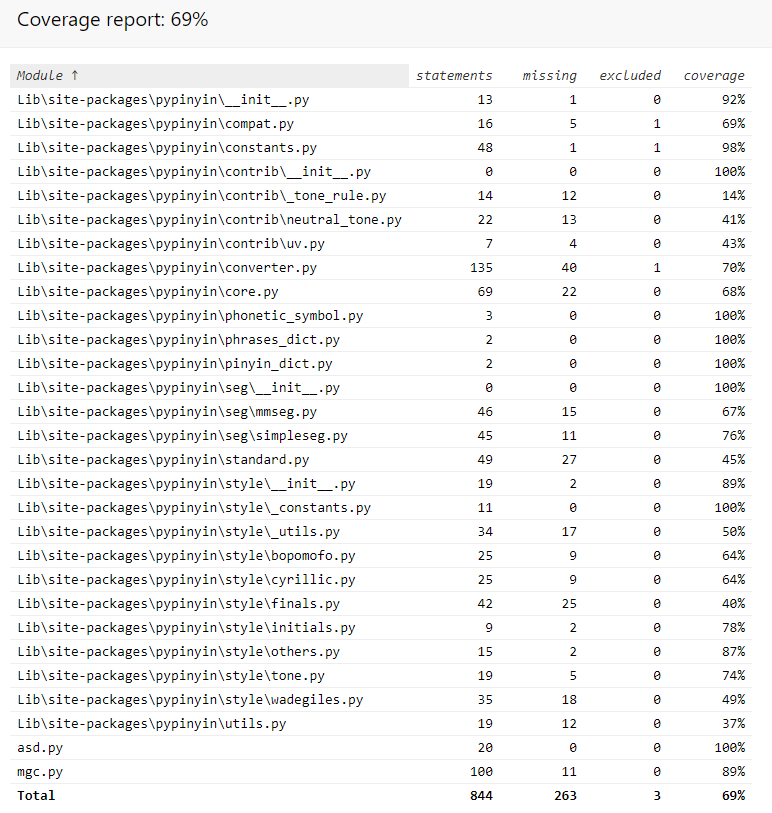
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
构造了两个测试韩式,第一个函数用于测试汉字敏感词的搜索匹配情况;第二个函数用于测试英文敏感词的搜索匹配情况。测试代码与运行结果如下。import unittest import mgc from mgc import * class testmgc(unittest.TestCase): def test_search1(self): s=['牛逼','吃屎'] t=['我叫马牛123逼,你知道我有多niu逼吗?,我敢c时!'] b=['Total: 3','Line1: <牛逼> 牛123逼','Line1: <牛逼> niu逼','Line1: <吃屎> c时'] m=mgc.Mgc_tree(s) l=len(t) self.assertEqual(b,m.search(t,l)) def test_search2(self): s = ['fuck', 'shit'] t = ['我叫fuc__k,你知道我有多FUC@@k吗?,我敢吃shi他,吃shi,。。t!'] b = ['Total: 3', 'Line1: <fuck> fuc__k', 'Line1: <fuck> FUC@@k', 'Line1: <shit> shi,。。t'] m = mgc.Mgc_tree(s) l = len(t) self.assertEqual(b, m.search(t, l)) if __name__ == '__main__': unittest.main()

(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
- 命令行参数数量不对时:
if len(sys.argv)!=4: print("命令行参数错误!") exit(0)
- 当读取文件失败时:
word_path=sys.argv[1] org_path=sys.argv[2] ans_path=sys.argv[3] if os.access(word_path, os.F_OK)!=True: print("word_path is not exist.")#敏感词库不存在 exit(0) if os.access(org_path, os.F_OK)!=True: print("org_path is not exist.")#测试文本不存在 exit(0) if os.access(ans_path, os.F_OK)!=True: print("ans_path is not exist.")#输出文本不存在 exit(0)
三、心得
(4.1)在完成本次作业过程的心得体会
本次作业是我使用Python这门语言写的第一个完整的程序(除去那些简单的hello world)。
通过本次作业也让我感受到了Python这门语言的方便(相对c)但是方便的同时有时候却影响了运行效率(就比如上方对程序分析时发现的lazy_pinyin函数占用资源过多的问题)
通过本次作业,我认识到了对题目分析和对代码功能提前设计的重要性,最开始没有考虑拼音的问题,导致后面书建了又删,删了又建,耗费了很多时间(虽然这些时间让我对dfa算法更加理解了)。所以说下次做题一定要好好把题目多看几遍,分析设计好程序的大概功能后再开始写代码。
最后是接触了代码性能分析、单元测试等以前没接触的东西,感觉就是打开了新世界的大门吧,这些都是大一大二的代码课不能接触到的东西,更坚定了要好好学这门课的想法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号