

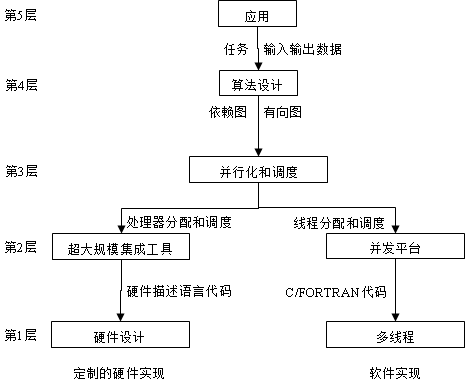
利用并行计算机实现软件和硬件上的并行算法的主要步骤和层次
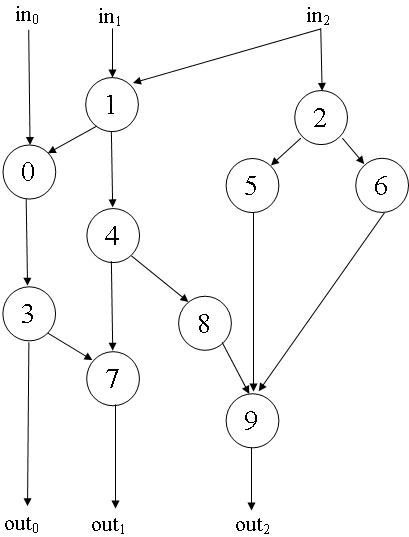
表示某个算法的有向无向图
- 通常用有向图(DG)来直观表示算法的子任务之间的数据依赖关系。DG在描述算法的时候表示依赖图,需要用带箭头的线段强调子任务之间的数据流向关系。
- 定义1:一个依赖图是边和结点的集合。结点表示算的子任务,边表示子任务用到的数据。数据包括输入、输出和中间结果。
- 注意:在一个依赖图中出现的不带箭头的边表示此边连接的两个结点之间没有数据依赖关系,它们只是共用算法中的某一个变量。这个变量可以是输入、输出或者在算法中作为I/O媒介的中间结果。
- 定义2:DG是有向边和结点的集合。结点表示算法需要处理的子任务,有向边表示子任务之间的数据依赖关系。一个子任务的输出在一条边的开端部分,箭头指向的一端表示一个子任务的输入。
- 定义3:有向无环图(DAG)是指一个没有任何环路的DG。
- 定义4:一个DG中的输入边是指只有目标结点而没有任何源结点的边,表述了算法的一个输入。在图中可以看到有3条这样的输入边,分别表示输入in0、in1和in2。
- 定义5:一个DG中的输出边是指只有源结点而没有目标结点的边,表达了算法的一个输出。在图中可以看到有3条这样的输出边,分别表示了输出out0、out1和out2。
- 定义6:一个DG中的内部边是指既有源节点又有目标结点的边,表达了算法的一个内部变量。
- 定义7:一个DG中的输入结点是指所有的入边都是输入边的结点。在图中可以看到0、1、2都表示输入结点。输入结点所表示的子任务在算法输入变量就绪后就被处理。
- 定义8:一个DG中的输出结点是指所有的出边都是输出边的结点。在图中可以看到结点7和9都表示输出结点。但是结点3不是输出结点,因为结点3的一条出边是指向结点7的内部边。
- 定义9:一个DG中的内部结点是有至少一条入边和至少一条出边的结点。
基于任务的依赖关系对算法进行分类
根据子任务的依赖关系可以大致将算法分为如下几类:
- 串行算法
- 并行算法
- 串行-并行算法(SPA)
- 非串行-并行算法(NSPA)
- 正则迭代算法(RIA):可以看做SPA的泛化。
串行算法
- 串行算法的特点是由于相互之间存在数据依赖关系,子任务必须一个一个地按顺序执行。这一类算法的DG是由一系列相互关联的子任务构成的队列。图中展示了一个串行算法的DG。此算法是用来计算斐波那契数列的。为了得到n10,子任务T10进行了如下计算:n10=n8+n9。在此n0=0和n1=1是初始条件已经给出。很明显,为了得到某一位的斐波那契数只能计算在它之前的数。

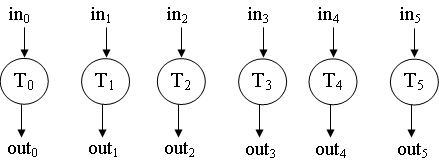
并行算法
- 并行算法的特点是由于相互之间不存在数据依赖关系,子任务可以同时并发执行。此算法的DG就像是许多独立的子任务组成的一组任务,相互之间没有联系。图中展示了一个并行算法的DG。Web服务器上的数据处理应用就是一种简单的并行算法,每一次数据请求都被看做独立的任务交给不同的处理器来响应。同时运行浏览器,字处理程序等多个程序时操作系统的多任务调度算法也是一种并行算法。
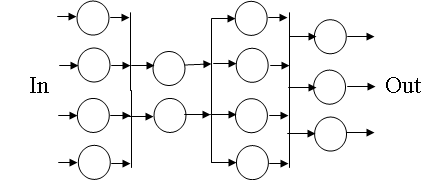
串行-并行算法(SPA)
- SPA的特点是子任务被分配至不同层次,每个层次之内的子任务可以并发执行,但是各个层次需按照一定的顺序执行。当需要执行的层次只有一层时,这个SPA就是并行算法。当每一层都只有一个子任务时,这个SPA是串行算法。图中展示了CORDIC算法的DG,CORDIC算法就是一个典型的SPA,它有n层迭代,在第i次迭代时需要执行以下运算:
- xi+1=xi+myiδi
- yi+1=yi-xiδi
- zi+1=zi+θi
- 在此等式中x,y和z都是进行迭代的数据,每次迭代之后都会被更新。δi和θi是存在表单中的常量。m是用来控制计算类型的参数,θi的数值是预设的,与i有关。此算法每次迭代都会进行这三项操作。
非串行-并行算法(NSPA)
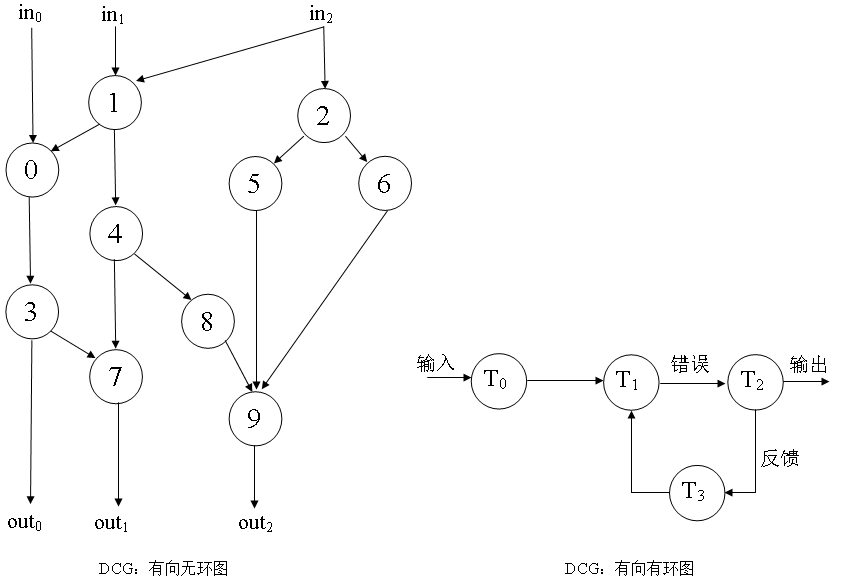
- NSPA不属于上述分类中的任何一种,NSPA算法的DG也没有规律可循。根据算法DG是否有环将NSPA分为两类:①DAG;②有向有环图(DCG)。
- 图中分别展示了一个DAG算法和一个DCG算法。DCG算法常见于离散时间回馈控制系统。输入信号作为子任务T0的初始滤波或者输入信号条件。子任务T1的输出通常是错误信号,然后这个信号会作为一种反馈输入子任务T2中。
- NSPA的依赖图有两种典型构造:结点用来表示构成算法的子任务,有向边则表示子任务之间的数据流向。一个结点的一条出线表示输出,入线表示输入。若Ti的输出指向Tj,则表明Tj依赖于Ti。在图中则用“结点i的一条有向边指向结点j”来表示这种依赖关系。
一个算法的DG有如下3个重要属性:
- Work任务数(W)表示算法完成需要处理的子任务总数。
- Depth深度(d)表示任意一个输入结点到任意一个输出结点之间的最大路径长度,也被称为关键路径。
- Parallelism并行度(P),也称为并行程度,表示可以并发执行的最大结点数。由此数据可以决定该算法需要的处理器的数目不会超过P,保证算法执行过程中不会出现不必要的处理器。
正则迭代算法(RIA)
- Karp等介绍了RIA的概念。这类算法的涵盖范围很广,包括信号处理,图像和视频处理,线性代数应用,以及基于网格结构的数字模拟程序。上图是一个RIA的依赖图,用做示例的是图像匹配算法。对于RIA算法,此处不使用DAG来表示,而是用依赖图的概念来表示。
- 依赖图和DAG类似,但是依赖图中的连接边是无向边而非有向边。
- RIA中的任务之间的依赖关系图十分复杂。串行算法和并行算法,甚至SPA算法的并行度计算都不复杂。且RIA算法的并行计算非常困难。
矩阵相乘算法就是一种简单的RIA算法:
要求:输入矩阵A和B
1 for i=0:I-1 do 2 for j=0:J-1 do 3 temp=0 4 for k=0:K-1 do 5 temp=temp+A(i,k)×B(k,j) 6 end for 7 C(i,j)=temp 8 end for 9 end for 10 RETURN C
- 该算法中出现的变量和算法的因子i、j、k有着正则依赖关系。一般情况下此类算法通过依赖图来进行研究,依赖图能展示需要执行的子任务之间的关系。当算法只有1个或者2个因子时,依赖图的展示非常直观。但是矩阵相乘的算法中出现了3个因子,因此它的依赖图是三维的,很难直观表示。

设计并行计算系统
- 在设计并行计算系统时需要注意的一些重要问题。
- 处理器之间的通信应该采用内部互联网络。此网络应该有能力支持任意两个处理器之间的即时通信。
- 任务分割表示将原始程序或应用分为几个程序段,以便稍后将这些程序段分配至各个处理器上。
- 粗粒度分割是指分配至各个处理器的程序段体积较大。
- 细粒度分割则是指程序段的体积较小。
- 程序段可以是不同的软件进程或者是线程。由程序员或者是编译器决定分割方式。程序员或操作系统必须要确保子任务的同步执行以保证程序的正确性和数据的完整性。
进步是留给时间最美的礼物

 浙公网安备 33010602011771号
浙公网安备 33010602011771号