

11.数学与随机数
(1)math包主要处理数学相关的运算。math包定义了两个常数:
math.e # 自然常数e
math.pi # 圆周率pi
(2)math包运算
math.ceil(x) # 对x向上取整,比如x=1.2,返回2
math.floor(x) # 对x向下取整,比如x=1.2,返回1
math.pow(x,y) # 指数运算,得到x的y次方
math.log(x) # 对数,默认基底为e。可以使用base参数,来改变对数的基地。
math.sqrt(x) # 平方根
(3)math包三角函数:
math.sin(x), math.cos(x), math.tan(x), math.asin(x), math.acos(x), math.atan(x)
这些函数都接收一个弧度(radian)为单位的x作为参数。
角度和弧度互换: math.degrees(x), math.radians(x)
(4)random包
1.随机挑选和排序
random.choice(seq) # 从序列的元素中随机挑选一个元素
比如random.choice(range(10)) #从0到9中随机挑选一个整数。
random.sample(seq,k) # 从序列中随机挑选k个元素
random.shuffle(seq) # 将序列的所有元素随机排序
2.随机生成实数
random.random() # 随机生成下一个实数,它在[0,1)范围内。
random.uniform(a,b) # 随机生成下一个实数,它在[a,b]范围内。
(5)decimal 十进制浮点运算类 Decimal
12.正则表达式
(1)匹配字符串
str.startswith()和str.endswith()
一个句子结尾是\n来结束的,所以用endswith(‘’)方法匹配时要注意传入的变量带有\n
或者用切片操作,str[:-1].endswith()

(2)正则表达式概念
使用单个字符串来描述匹配一系列符合某个句法规则的字符串,是对字符串操作的一种逻辑公式,应用场景在处理文本和数据。
re 模块使Python语言拥有全部的正则表达式功能。
(3)导入re模块 #import re
利用re.compile(正则表达式)返回pattern
利用pattern.match(待匹配字符串)返回match
match.group()返回子串
match.string()返回主串
match.span()返回子串在主串中的位置

(4)re.match 尝试从字符串的开始匹配一个模式。

pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写, 多行匹配等等
匹配成功re.match方法返回一个匹配的对象,否则返回None。
(5)group(num)或groups()匹配对象函数来获取匹配表达式。
group(num=0)匹配的整个表达式的字符串,group()可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups()返回一个包含所有小组字符串的元组。
(6)基本匹配符
①. 匹配任意字符(除了\n),一个点只是一个字符
②[…] 匹配字符集 如[a-z][A-Z][0-9][a-zA-Z0-9]
③[^…] 匹配不在[]中的任意字符
④\d 匹配数字等价于[0-9]
⑤\D 匹配非数字
⑥\s 匹配空白,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]
⑦\S 匹配非空白
⑧\w 匹配单词字符,匹配包括下划线的任何单词字符。等价于[A-Za-z0-9_]
⑨\W 匹配非单词字符

(7)特殊匹配符
①* 匹配前一个字符0次或无限次
②+ 匹配前一个字符1次或无限次
③? 匹配前一个字符0次或1次
④{m} 匹配前一个字符m次
⑤{m,n} 匹配前一个字符m到n次
⑥*?或+?或?? 匹配模式变为非贪婪(尽可能减少匹配字符)

(8)高级匹配符
①^ 匹配字符串开头
②$ 匹配字符串结尾
③\A 指定的字符串必须出现在开头
④\Z 指定的字符串必须出现在结尾
⑤| 或,匹配左右任意一个表达式
⑥(ab) 括号中表达式作为一个分组
⑦\<number> 引用编号为num的分组匹配到的字符串
⑧(?P<name>) 分组起一个别名
⑨(?P=name) 引用别名为name的分组匹配字符串
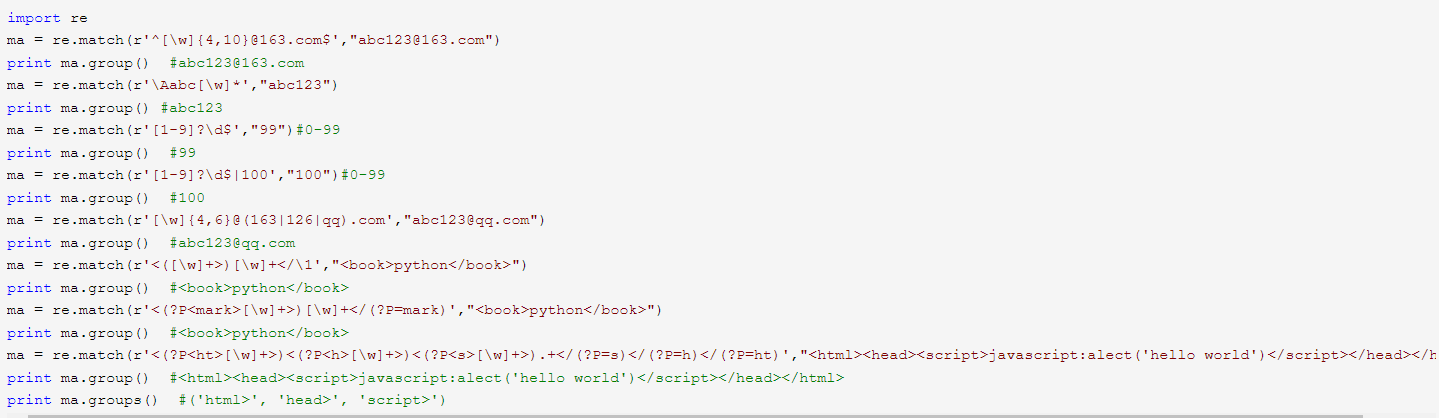
(9)其他方式
①search(pattern,string,flags=0)
会在字符串内查找模式匹配,直到找到第一个匹配
匹配成功re.search方法返回一个匹配的对象,否则返回None
②findall(pattern,string,flags=0)
找到匹配,返回所有匹配部分的列表
③sub(pattern,repl,string,count=0,flags=0)
将字符串中匹配正则表达式的部分替换为其他值
④split(pattern,string,maxsplit=0,flags=0)
根据匹配分割字符串,返回分割字符串组成的列表

(10)修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。
①re.I 使匹配对大小写不敏感
②re.M 多行匹配,影响 ^和$
③re.S 使.匹配包括换行在内的所有字符
(11)抓取网页中的图片到本地
1:抓取网页
2:获取图片地址
3:抓取图片内容并保存到本地


 浙公网安备 33010602011771号
浙公网安备 33010602011771号