

10.循环
(1)for循环依次把list或tuple的每个元素迭代出来
格式:

name 这个变量是在 for 循环中定义的,意思是,依次取出list中的每一个元素,并把元素赋值给 name,然后执行for循环体(就是缩进的代码块)
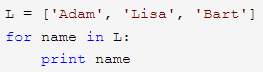
这样一来,遍历一个list或tuple就非常容易了。
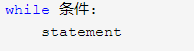
(2)while循环,不会迭代 list 或 tuple 的元素,而是根据表达式判断循环是否结束。
(3)中断循环 break和continue
(4)range()的用法
range(1,5) #代表从1到5(不包含5) [1, 2, 3, 4]
range(1,5,2) #代表从1到5,间隔2(不包含5) [1, 3]
range(5) #代表从0到5(不包含5) [0, 1, 2, 3, 4]
(5)Python中,迭代永远是取出元素本身,而非元素的索引。
对于有序集合,元素确实是有索引的。使用enumerate()函数拿到索引

使用 enumerate() 函数,我们可以在for循环中同时绑定索引index和元素name。但是,这不是 enumerate() 的特殊语法。实际上,enumerate() 函数把:['Adam', 'Lisa', 'Bart', 'Paul']
变成了类似:[(0, 'Adam'), (1, 'Lisa'), (2, 'Bart'), (3, 'Paul')]
因此,迭代的每一个元素实际上是一个tuple
(6)好用的zip()方法

(7)列表生成式
假如要生成[1x1, 2x2, 3x3, ..., 10x10]

列表生成式的 for 循环后面还可以加上 if 判断。
例如:
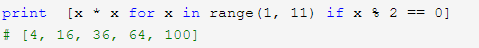
(8)迭代器
它为类序列对象提供了一个类序列的接口。
迭代非序列集合(例如映射和文件)时, 可以创建更简洁可读的代码。

11字典
(1)字典的元素没有顺序。你不能通过下标引用元素。字典是通过键来引用,用大括号
查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降。
dict的缺点是占用内存大,还会浪费很多内容
dict是按 key 查找,所以,在一个dict中,key不能重复
作为 key 的元素必须不可变
(2)已知两个列表,一个是名字,一个是成绩,要根据名字找到对应的成绩用两个list不方便,如果把名字和分数关联起来,组成类似的查找表,即 Python中的dict
用 dict 表示“名字”-“成绩”的查找表如下:

(3)我们把名字称为key,对应的成绩称为value,dict就是通过 key 来查找 value。
(4)花括号 {} 表示这是一个dict,然后按照 key: value, 写出来即可。最后一个 key: value 的逗号可以省略。
(5)由于dict也是集合,len()函数可以计算任意集合的大小:

一个 key-value 算一个,因此,dict大小为3。
(6)可以简单地使用 d[key] 的形式来查找对应的 value,这和 list 很像,不同之处是,list 必须使用索引返回对应的元素,而dict使用key:

注意: 通过 key 访问 dict 的value,只要 key 存在,dict就返回对应的value。如果key不存在,会直接报错:KeyError。
要避免 KeyError 发生,有两个办法:
一是先判断一下 key 是否存在,用 in 操作符:
二是使用dict本身提供的一个 get 方法,在Key不存在的时候,返回None:

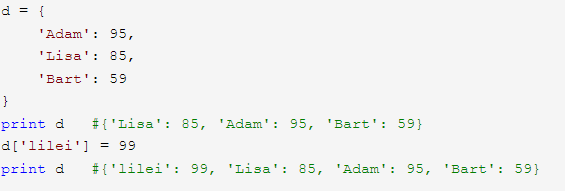
(7)在字典中增添一个新元素的方法:
(8)循环调用

(9)字典的常用方法
print d.keys() # 返回d所有的键
print d.values() # 返回d所有的值
print d.items() # 返回d所有的元素(键值对)
d.clear() # 清空d,dict变为{}
del d[‘xxx’] # 删除 d 的‘xxx’元素
(10)cmp()比较
先比较字典长度
再比较字典的键
最后比较字典的值
都一样就相等
12.集合(set)
(1)dict的作用是建立一组 key 和一组 value 的映射关系,dict的key是不能重复的
有的时候,我们只想要 dict 的 key,不关心 key 对应的 value,目的就是保证这个集合的元素不会重复,这时,set就派上用场
(2)set 持有一系列元素,这一点和 list 很像,但是set的元素没有重复,而且是无序的,这点和 dict 的 key很像。
(3)创建 set 的方式是调用 set() 并传入一个 list,list的元素将作为set的元素:

(4)添加和删除

13.函数
(1)定义一个函数要使用 def 语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用 return 语句返回。

(2)如果没有return语句,函数执行完毕后也会返回结果,只是结果为 None。
(3)函数返回多个值

其实这只是一种假象,Python函数返回的仍然是单一值,是一个tuple:但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,但写起来更方便。
(4)在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。

(5)定义函数的时候,还可以有默认参数。

由于函数的参数按从左到右的顺序匹配,所以默认参数只能定义在必需参数的后面:
(6)由于函数的参数按从左到右的顺序匹配,所以默认参数只能定义在必需参数的后面:

可变参数的名字前面有个 * 号,我们可以传入0个、1个或多个参数给可变参数:
(7)基本数据类型的参数:值传递
表作为参数:指针传递
14.pass del exec eval
(1)pass语句
pass代表该语句什么都不做,因为python中空代码是非法的,比如一个if语句要求什么内容都不做,我们就可以使用pass语句
(2)del语句
一般来说python会删除那些不在使用的对象(因为使用者不会再通过任何变量或者数据结构引用它们)
(3)exec语句(运行字符串中的程序)

(4)eval函数(会计算python表达式(以字符串形式书写),并且返回结果)

15.内建函数
(1)cmp(obj1, obj2) 比较 obj1 和 obj2, 根据比较结果返回整数 i:
if obj1 < obj2 返回i < 0
if obj1 > obj2 返回i > 0
if obj1 == obj2 返回i == 0
如果是用户自定义对象, cmp()会调用该类的特殊方法__cmp__()
(2)str() 强制转换成字符串
(3)type() :详见(3)数据类型 - 3、
(4)help():通过用函数名作为 help()的参数就能得到相应的帮助信息
(5)isinstance(变量名,类型): 判断是否是这个类型的元素,可以用if语句
(6)abs():取绝对值
(7)enumerate():详见(10)循环 - 5、
(8)len(seq):返回seq的长度
(9)sorted(iter):排序,会调用cmp()
(10)zip(a1,a2……):详见(10)循环 - 6、
(11)range():详见(10)循环 - 4、
(12)string.lower():转换字符串中所有大写字符为小写
(13)string.upper():转换字符串中所有小写字符为大写
(14)string.strip():删去字符串开头和结尾的空格
(15)string.capitalize():把字符串第一个字符大写
(16)string.title():所有单词都以大写开头
(17)max()和min():找出最大和最小值
(18)sum():求和
(19)reversed():倒序输出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号