
MySQL 数据分析
📘 第一部分 MySQL 数据分析
目标:掌握 MySQL 的基本操作,并能用 SQL 进行数据分析
所需工具:MySQL、Navicat / 命令行
第 1 步:安装与连接
1.1 安装 MySQL(略)
- Ubuntu/Debian:
sudo apt install mysql-server - 启动服务后,运行
mysql -u root -p登录
1.2 创建专用用户(略)
CREATE USER 'analyst'@'localhost' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON *.* TO 'analyst'@'localhost';
FLUSH PRIVILEGES;
第 2 步:创建数据库与表(模拟学生成绩数据)
2.1 创建数据库
CREATE DATABASE school_analysis
DEFAULT CHARACTER SET utf8mb4
DEFAULT COLLATE utf8mb4_unicode_ci;
USE school_analysis;
2.2 创建学生表 students
CREATE TABLE students (
student_id INT PRIMARY KEY,
name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci,
gender CHAR(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci,
class VARCHAR(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
2.3 创建成绩表 scores
CREATE TABLE scores (
score_id INT AUTO_INCREMENT PRIMARY KEY,
student_id INT,
subject VARCHAR(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci,
score DECIMAL(5,2),
exam_date DATE,
FOREIGN KEY (student_id) REFERENCES students(student_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
2.4 插入示例数据
-- 学生数据
INSERT INTO students VALUES
(1, '张三', 'M', 'ClassA'),
(2, '李四', 'F', 'ClassA'),
(3, '王五', 'M', 'ClassB'),
(4, '赵六', 'F', 'ClassB');
-- 成绩数据
INSERT INTO scores (student_id, subject, score, exam_date) VALUES
(1, 'Math', 88.5, '2025-12-01'),
(1, 'English', 92.0, '2025-12-01'),
(2, 'Math', 76.0, '2025-12-01'),
(2, 'Science', 85.5, '2025-12-01'),
(3, 'Math', 95.0, '2025-12-01'),
(4, 'English', 88.0, '2025-12-01');
第 3 步:MySQL 基本操作(CRUD + 查询)
3.1 查看数据(SELECT)
-- 查看所有学生
SELECT * FROM students;
-- 查看数学成绩
SELECT * FROM scores WHERE subject = 'Math';
3.2 新增数据(INSERT)
INSERT INTO scores (student_id, subject, score, exam_date)
VALUES (3, 'English', 82.5, '2025-12-01');
3.3 修改数据(UPDATE)
-- 张三的数学成绩更正为 90.0
UPDATE scores
SET score = 90.0
WHERE student_id = 1 AND subject = 'Math';
3.4 删除数据(DELETE)
-- 删除某次错误录入的成绩
DELETE FROM scores WHERE score_id = 10;
⚠️ 注意:生产环境中建议先
SELECT确认再DELETE!
第 4 步:数据分析常用查询技巧
4.1 聚合函数(统计分析核心)
-- 平均分
SELECT AVG(score) AS avg_score FROM scores;
-- 每科最高分
SELECT subject, MAX(score) FROM scores GROUP BY subject;
-- 每班人数
SELECT class, COUNT(*) AS student_count FROM students GROUP BY class;
4.2 多表连接(JOIN)
-- 查看学生姓名及其数学成绩
SELECT s.name, sc.score
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
WHERE sc.subject = 'Math';
4.3 条件筛选(WHERE + HAVING)
-- 找出平均分 > 85 的学生
SELECT student_id, AVG(score) AS avg_score
FROM scores
GROUP BY student_id
HAVING AVG(score) > 85;
4.4 排序与限制(ORDER BY, LIMIT)
-- 全校成绩排名前3
SELECT s.name, sc.subject, sc.score
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
ORDER BY sc.score DESC
LIMIT 3;
4.5 分类统计(CASE WHEN)
-- 给成绩打标签:优秀(≥90),良好(80-89),及格(60-79),不及格(<60)
SELECT
name,
subject,
score,
CASE
WHEN score >= 90 THEN '优秀'
WHEN score >= 80 THEN '良好'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END AS level
FROM students s
JOIN scores sc ON s.student_id = sc.student_id;
第 5 步:导出数据(用于进一步分析)
5.1 导出查询结果(命令行)
mysql -u analyst -p -e "SELECT * FROM scores;" school_analysis > scores.csv
5.2 或在 Navicat 中:
- 运行查询 → 右键结果 → “Export Recordset to External File” → 选择 CSV
💡 导出后可用 Excel、Python (pandas) 或 Power BI 进行可视化。
第 6 步:常见问题排查
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
| 无法连接数据库 | 服务未启动 / 密码错误 | sudo systemctl start mysql(Linux) |
| 插入中文乱码 | 字符集非 UTF8 | 创建表时加 CHARACTER SET utf8mb4 |
| JOIN 结果重复 | 一对多关系未处理 | 检查主外键,使用 DISTINCT 或聚合 |
✅ 总结:MySQL 在数据分析中的角色
| 功能 | 说明 |
|---|---|
| 数据存储 | 结构化保存原始数据 |
| 数据清洗 | 用 UPDATE/DELETE 修正错误 |
| 初步分析 | 用 GROUP BY + 聚合函数快速统计 |
| 数据准备 | 用 JOIN 整合多表,导出给高级工具 |
📘 第二部分 练习题
--
📝 配套练习题(MySQL 数据分析)
说明:以下题目基于以上创建的
school_analysis数据库中的students和scores表。
🔹 A:基础操作(CRUD)
Q1. 查询所有女生(gender = 'F')的姓名和班级。
-- 你的答案:
✅ 答案:
SELECT name, class FROM students WHERE gender = 'F';
Q2. 为学生“李四”(student_id=2)添加一次物理成绩:78.5 分,考试日期为 2025-12-01。
-- 你的答案:
✅ 答案:
INSERT INTO scores (student_id, subject, score, exam_date)
VALUES (2, 'Physics', 78.5, '2025-12-01');
Q3. 将“王五”的英语成绩更正为 85.0。
-- 你的答案:
✅ 答案:
UPDATE scores
SET score = 85.0
WHERE student_id = 3 AND subject = 'English';
🔹 B:聚合与分组
Q4. 计算每个学生的总分(所有科目成绩之和),并按总分降序排列。
-- 你的答案:
✅ 答案:
SELECT s.name, SUM(sc.score) AS total_score
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
GROUP BY s.student_id, s.name
ORDER BY total_score DESC;
💡 注意:必须
GROUP BY student_id(或 name),否则 SUM 会报错。
Q5. 找出平均分低于 85 的班级(先关联成绩,再按班级分组)。
-- 你的答案:
✅ 答案:
SELECT s.class, AVG(sc.score) AS avg_class_score
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
GROUP BY s.class
HAVING AVG(sc.score) < 85;
🔹 C:高级查询技巧
Q6. 统计每个等级(优秀/良好/及格/不及格)的人次数量(使用 CASE WHEN)。
-- 你的答案:
✅ 答案:
SELECT
CASE
WHEN score >= 90 THEN '优秀'
WHEN score >= 80 THEN '良好'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END AS level,
COUNT(*) AS count
FROM scores
GROUP BY level
ORDER BY FIELD(level, '优秀', '良好', '及格', '不及格');
💡
FIELD()可控制排序顺序(可选,但推荐)。
Q7. 列出“ClassA”中数学成绩高于全班数学平均分的学生姓名和分数。
-- 你的答案:
✅ 答案:
SELECT s.name, sc.score
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
WHERE s.class = 'ClassA'
AND sc.subject = 'Math'
AND sc.score > (
SELECT AVG(score)
FROM scores sc2
JOIN students s2 ON sc2.student_id = s2.student_id
WHERE s2.class = 'ClassA' AND sc2.subject = 'Math'
);
✅ 考察子查询 + 多表条件。
🔹 D:综合应用
Q8. 生成一份报告:每位学生各科成绩 + 等级 + 是否高于该科平均分(是/否)。
-- 你的答案:
✅ 答案:
SELECT
s.name,
sc.subject,
sc.score,
CASE
WHEN sc.score >= 90 THEN '优秀'
WHEN sc.score >= 80 THEN '良好'
WHEN sc.score >= 60 THEN '及格'
ELSE '不及格'
END AS level,
CASE
WHEN sc.score > subj_avg.avg_score THEN '是'
ELSE '否'
END AS above_subject_avg
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
JOIN (
SELECT subject, AVG(score) AS avg_score
FROM scores
GROUP BY subject
) subj_avg ON sc.subject = subj_avg.subject
ORDER BY s.name, sc.subject;
✅ 考察:多表连接 + 子查询(作为临时表)+ CASE 嵌套。
🔹 思考题
Q9. 找出“偏科最严重”的学生(即最高分与最低分差距最大的学生)。
-- 提示:使用 MAX(score) - MIN(score)
✅ 答案:
SELECT
s.name,
MAX(sc.score) - MIN(sc.score) AS score_gap
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
GROUP BY s.student_id, s.name
ORDER BY score_gap DESC
LIMIT 1;
📘 第三部分 MySQL 与 Python/pandas 联动
目标:打通“数据库 → 分析 → 可视化 → 回写” 全流程
- python库:
pandas、sqlalchemy、PyMySQL(或mysql-connector-python) - 用 Python 连接 MySQL
- 将查询结果直接加载为 pandas DataFrame
- 在 pandas 中进行清洗、分析、可视化
- 将处理后的数据写回数据库
第 1 步:安装必要 Python 库
pip install \
pandas \
sqlalchemy \
pymysql \
matplotlib \
seaborn \
-i https://mirrors.aliyun.com/pypi/simple/
第 2 步:连接 MySQL 数据库
tee dataAnalysis.py <<'EOF'
# dataAnalysis.py
import pandas as pd
from sqlalchemy import create_engine
from urllib.parse import quote_plus
username = "username"
password = "Hello123!" # 原始密码,含特殊字符
host = "10.7.164.5"
port = 3306
database = "username"
# 自动对密码进行 URL 编码
encoded_password = quote_plus(password)
engine = create_engine(
f"mysql+pymysql://{username}:{encoded_password}@{host}:{port}/{database}?charset=utf8mb4"
)
# 测试连接
try:
with engine.connect() as conn:
print("✅ 成功连接到 MySQL!")
except Exception as e:
print("❌ 连接失败:", e)
EOF
📌 连接字符串字段说明与实际配置对照
"mysql+pymysql://analyst:123456@localhost:3306/school_analysis?charset=utf8mb4"
| 部分 | 含义 |
|---|---|
| mysql+pymysql | 使用 PyMySQL 驱动连接 MySQL |
| analyst | 数据库用户名 |
| 123456 | 用户密码 |
| localhost | 数据库服务器 IP 或主机名 |
| 3306 | MySQL 默认端口 |
| school_analysis | 要连接的数据库名称(schema) |
| ?charset=utf8mb4 | 指定字符集,避免中文乱码 |
第 3 步:从 MySQL 读取数据到 pandas
3.1 读取整张表
df_students = pd.read_sql("SELECT * FROM students", con=engine)
df_scores = pd.read_sql("SELECT * FROM scores", con=engine)
print(df_students.head())
print(df_scores.head())
3.2 执行复杂查询(直接传 SQL)
query = """
SELECT
s.name,
s.class,
sc.subject,
sc.score
FROM students s
JOIN scores sc ON s.student_id = sc.student_id
WHERE sc.score >= 85
ORDER BY sc.score DESC;
"""
df_high_scores = pd.read_sql(query, con=engine)
print(df_high_scores)
✅ 优势:SQL 负责筛选和聚合,pandas 负责后续分析,分工明确!
第 4 步:在 pandas 中进行数据分析
4.1 基础统计
# 各科目平均分
avg_by_subject = df_scores.groupby('subject')['score'].mean()
print(avg_by_subject)
4.2 合并学生信息
# 将学生表与成绩表合并(类似 SQL JOIN)
df_merged = pd.merge(df_students, df_scores, on='student_id')
print(df_merged.head())
4.3 成绩分布可视化(用 matplotlib / seaborn)
python -m venv see
source see/bin/activate
pip install --upgrade pip
pip install \
pandas==2.0.3 \
matplotlib==3.7.2 \
seaborn==0.12.2 \
sqlalchemy==2.0.25 \
PyMySQL==1.1.0 \
numpy==1.24.4 \
-i https://mirrors.aliyun.com/pypi/simple/
tee see.py <<'EOF'
# see.py
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sqlalchemy import create_engine
from urllib.parse import quote_plus
# === 🔑 关键:设置中文字体 ===
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans', 'Bitstream Vera Sans', 'sans-serif']
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# === 数据库连接 ===
username = "jacky"
password = "Asimov.123"
host = "10.234.10.105"
port = 3306
database = "school_analysis"
encoded_password = quote_plus(password)
engine = create_engine(
f"mysql+pymysql://{username}:{encoded_password}@{host}:{port}/{database}?charset=utf8mb4"
)
# === 读取数据 ===
df_scores = pd.read_sql("SELECT * FROM scores", con=engine)
# === 绘图 ===
plt.figure(figsize=(8, 5))
sns.boxplot(data=df_scores, x='subject', y='score')
plt.title('各科成绩分布')
plt.ylabel('分数')
plt.xlabel('科目')
plt.tight_layout()
plt.show()
EOF
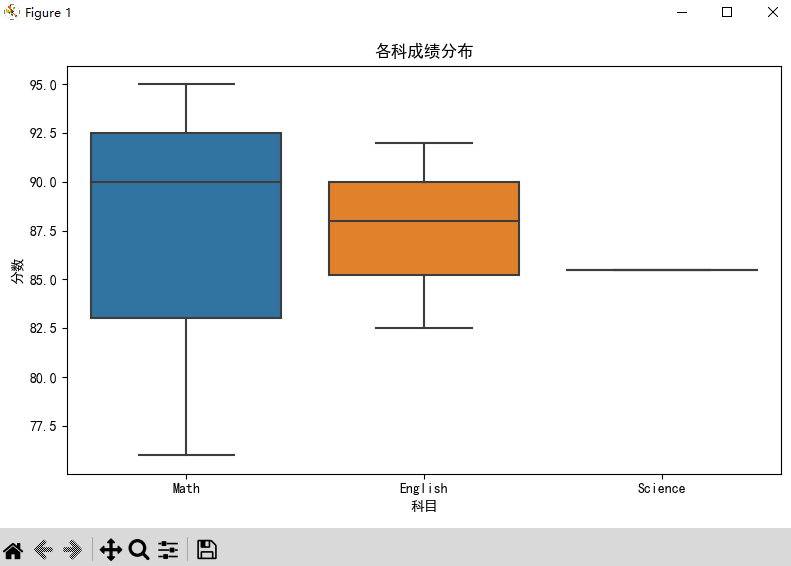
📊 图表基本信息
- 标题:各科成绩分布
- 横轴(X):科目(Math, English, Science)
- 纵轴(Y):分数(Score)
- 图表类型:箱线图(Box Plot)
⚠️ 注意:Science 科目没有显示箱体 → 表示只有 1 条记录,无法画出完整的箱线图。
🔍 箱线图组成:
| 部分 | 含义 |
|---|---|
| ✅ 箱体(Box) | 包含中间 50% 的数据(从第 25 百分位到第 75 百分位) |
| ✅ 中位线(Median Line) | 箱体中间的横线,表示数据的中位数(第 50 百分位) |
| ✅ 上下须(Whiskers) | 从箱体延伸出的线,通常代表“正常范围” |
| ✅ 异常值(Outliers) | 超出须之外的点(本图未显示) |
- Math(数学)
- 箱体范围:约 83 ~ 93 分 → 中间 50% 的学生分数在此区间
- 中位数:约 90 分 → 一半学生高于此,一半低于
- 上下须:最低 77 分,最高 95 分 → 数据整体集中在 77~95 之间
- 结论:数学成绩分布较集中,中等偏上,无明显异常值
- English(英语)
- 箱体范围:约 85 ~ 90 分 → 中间 50% 的学生分数在此
- 中位数:约 88 分
- 上下须:最低 82 分,最高 92 分
- 结论:英语成绩略低于数学,但波动较小,整体稳定
- Science(科学)
- 只有一条横线 → 因为只有 1 条记录(赵六考了 85.5)
- 没有箱体、没有须 → 无法计算四分位数
- 结论:数据不足,无法分析分布
🧠 综合分析与建议
| 维度 | 数学 | 英语 | 科学 |
|---|---|---|---|
| 平均水平 | 较高(中位数 90) | 中等(中位数 88) | 单一值(85.5) |
| 波动程度 | 较大(跨度 18 分) | 较小(跨度 10 分) | 无数据 |
| 数据完整性 | 完整 | 完整 | 不完整 |
第 5 步:将分析结果写回 MySQL
tee result_to_new_table.py <<'EOF'
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
📊 学生成绩平均分计算与写入 MySQL
功能说明:
- 从 MySQL 中读取 students 和 scores 表
- 合并数据,按学生计算平均分
- 将结果写入新表 student_avg_scores
依赖库:
- pandas
- sqlalchemy
- pymysql(作为 SQLAlchemy 的 MySQL 驱动)
"""
import pandas as pd
from sqlalchemy import create_engine
# ==============================
# 🔌 数据库连接配置
# 请根据实际环境修改以下参数
# ==============================
DB_USER = 'analyst' # 数据库用户名
DB_PASSWORD = '123456' # 密码
DB_HOST = 'localhost' # 主机地址(本地为 localhost)
DB_PORT = 3306 # MySQL 默认端口
DB_NAME = 'school_analysis' # 目标数据库名
# 构建 SQLAlchemy 连接字符串(使用 PyMySQL 驱动)
# 格式:mysql+pymysql://用户:密码@主机:端口/数据库
connection_string = f"mysql+pymysql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}:{DB_PORT}/{DB_NAME}"
# 创建数据库引擎(用于 pandas 与 MySQL 交互)
engine = create_engine(
connection_string,
echo=False, # 设为 True 可打印 SQL 日志(调试用)
pool_pre_ping=True # 自动检测连接有效性,避免断连
)
# ==============================
# 📥 从数据库读取原始数据
# ==============================
print("📥 正在从 MySQL 读取 students 和 scores 表...")
# 读取学生信息表
df_students = pd.read_sql("SELECT student_id, name, class FROM students", con=engine)
# 读取成绩表
df_scores = pd.read_sql("SELECT student_id, score FROM scores", con=engine)
# 合并两个表(基于 student_id)
df_merged = pd.merge(df_students, df_scores, on='student_id', how='inner')
print(f"✅ 成功加载 {len(df_merged)} 条成绩记录。")
# ==============================
# 🧮 计算每个学生的平均分
# ==============================
print("🧮 正在计算每位学生的平均分...")
# 按 student_id、name、class 分组,计算 score 的平均值
df_avg = (
df_merged
.groupby(['student_id', 'name', 'class'])['score']
.mean()
.reset_index()
)
# 重命名列,使语义更清晰
df_avg.rename(columns={'score': 'avg_score'}, inplace=True)
# 可选:保留两位小数(提高可读性)
df_avg['avg_score'] = df_avg['avg_score'].round(2)
# ==============================
# 📤 写入结果到 MySQL 新表
# ==============================
print("📤 正在将平均分结果写入 MySQL 表 student_avg_scores...")
df_avg.to_sql(
name='student_avg_scores', # 目标表名
con=engine, # 数据库连接引擎
if_exists='replace', # 若表已存在则替换(可改为 'append')
index=False, # 不写入 pandas 的索引
method='multi' # 使用批量插入,提升性能
)
print("✅ 平均分结果已成功写入 MySQL 表 `student_avg_scores`!")
print("\n📄 表结构预览:")
print(df_avg.head())
EOF
第 6 步:自动化脚本示例(每日分析任务)
tee daily_analysis.py <<'EOF'
# daily_analysis.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
📅 每日成绩分析脚本
功能:
- 读取今日(exam_date = CURDATE())的成绩
- 按科目统计平均分和记录数
- 将结果追加写入 daily_summary 表
"""
import pandas as pd
from sqlalchemy import create_engine, text
import sys
# ==============================
# 🔌 数据库连接配置
# 请根据实际环境修改以下参数
# ==============================
DB_USER = 'analyst' # 数据库用户名
DB_PASSWORD = '123456' # 密码
DB_HOST = 'localhost' # 主机地址(本地为 localhost)
DB_PORT = 3306 # MySQL 默认端口
DB_NAME = 'school_analysis' # 目标数据库名
# 构建 SQLAlchemy 连接字符串(使用 PyMySQL 驱动)
# 格式:mysql+pymysql://用户:密码@主机:端口/数据库
connection_string = f"mysql+pymysql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}:{DB_PORT}/{DB_NAME}?charset=utf8mb4"
# 创建数据库引擎(用于 pandas 与 MySQL 交互)
engine = create_engine(
connection_string,
echo=False,
pool_pre_ping=True
)
# ==============================
# 📥 1. 读取今日成绩
# ==============================
try:
print("📥 正在读取今日成绩数据...")
df = pd.read_sql(
text("SELECT * FROM scores WHERE exam_date = CURDATE()"),
con=engine
)
if df.empty:
print("ℹ️ 今日无考试数据,跳过分析。")
sys.exit(0)
print(f"📊 今日共 {len(df)} 条成绩记录。")
# ==============================
# 🧮 2. 按科目聚合分析
# ==============================
summary = (
df.groupby('subject')['score']
.agg(['mean', 'count'])
.round(2)
.reset_index()
.rename(columns={'mean': 'avg_score', 'count': 'record_count'})
)
# 可选:添加分析日期(便于追踪)
from datetime import date
summary['analysis_date'] = date.today()
# ==============================
# 📤 3. 保存到日志表
# ==============================
print("📤 正在写入 daily_summary 表...")
summary.to_sql(
name='daily_summary',
con=engine,
if_exists='append',
index=False,
method='multi'
)
print("✅ 今日分析完成!")
print(summary.to_string(index=False))
except Exception as e:
print(f"❌ 执行出错:{e}", file=sys.stderr)
sys.exit(1)
EOF
可配合 cron(Linux)定时运行。
-- 在 MySQL 中执行
INSERT INTO scores (student_id, subject, score, exam_date)
VALUES
(1, 'Math', 88.0, CURDATE()),
(2, 'Math', 92.0, CURDATE()),
(1, 'English', 85.0, CURDATE()),
(1, 'Physics', 80.5, CURDATE());
然后再运行:
python3 daily_analysis.py
📥 正在读取今日成绩数据...
📊 今日共 1 条成绩记录。
📤 正在写入 daily_summary 表...
✅ 今日分析完成!
subject avg_score record_count analysis_date
Physics 80.5 1 2026-02-04
✅ 总结:MySQL + pandas 协同工作流
graph LR
A[MySQL 原始数据] -->|SQL 查询| B(pandas DataFrame)
B --> C[数据清洗/聚合/建模]
C --> D[可视化]
C -->|to_sql| E[MySQL 结果表]
拓展:
- Jupyter Notebook 版本?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号