
25-Day 6 长期记忆 —— 接触向量数据库
📅 Day 6:长期记忆 —— 向量数据库入门
让 Agent 记住“用户偏好”,而不仅是对话历史
🎯 教学目标
- 理解长期记忆 vs 短期记忆的区别
- 掌握向量数据库(FAISS)的基本用法
- 学会用文本嵌入(Embedding)实现语义检索
- 完成一个可运行的“偏好记忆”小系统
- 为 Day 7(Agent + 长期记忆)打下基础
🔍 核心概念讲解
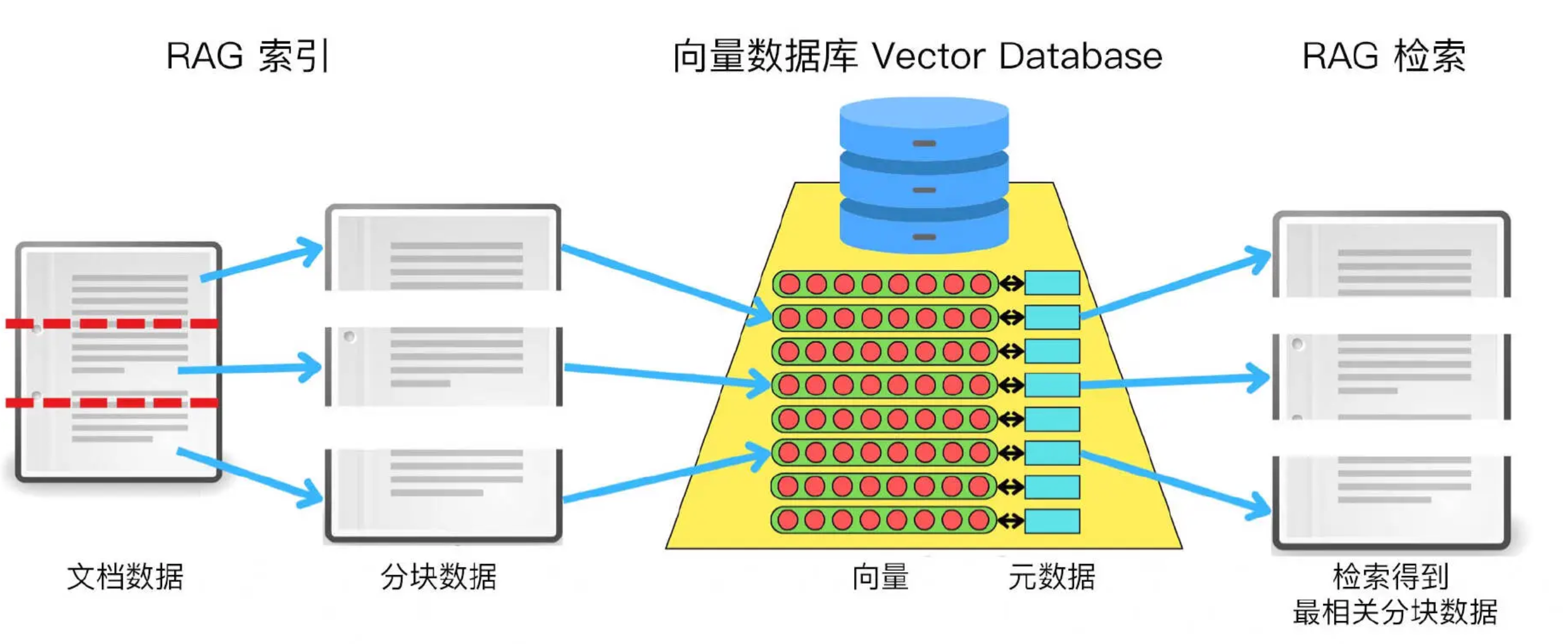
向量数据库的概念
[🎥 打开向量数据库视频](file:///D:/24-python-AI%20Agent/%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93%E6%8A%80%E6%9C%AF.mp4)
❓ 为什么需要“长期记忆”?
- 对话历史(SQLite)只能记住说过什么,但无法回答:
- “我上次说喜欢什么?”
- “我对开会的态度是什么?”
- 长期记忆 = 用户偏好的知识库,需支持语义模糊匹配
💡 向量数据库如何工作?
原始文本 → [嵌入模型] → 高维向量 → 存入 FAISS
查询文本 → [嵌入模型] → 向量 → 在 FAISS 中找最近邻 → 返回原文
✅ 为什么选 FAISS?
FAISS(Facebook AI Similarity Search)是由 Facebook AI 团队开发的一个高效、开源的向量相似性搜索库,主要用于在大规模高维向量数据集中快速查找最相似的向量。它广泛应用于推荐系统、图像检索、自然语言处理(如语义搜索)、聚类等需要进行近似最近邻(Approximate Nearest Neighbor, ANN)搜索的场景。
- Facebook 开源,纯 Python 支持(
langchain-community) - 内存存储,无需部署数据库
- 适合小规模、本地实验
⚠️ 注意:FAISS 不持久化!程序退出后数据丢失(下一篇 会解决)
💻 实验:构建你的第一个向量记忆系统
步骤 1:准备环境
# 进入项目目录
mkdir -p day06 && cd day06
python3 -m venv vector_memory
# 激活虚拟环境(延续 Day5)
source vector_memory/bin/activate
# 安装依赖
pip install \
langchain \
langchain-community \
langchain-openai \
python-dotenv \
-i https://mirrors.aliyun.com/pypi/simple/
pip install \
faiss-cpu \
dashscope \
-i https://mirrors.aliyun.com/pypi/simple/
# 创建 .env 文件
echo "DASHSCOPE_API_KEY=(替换为您的实际API Key)" > .env
步骤 2:编写 vector_memory.py
当然可以!以下是在不改变原有逻辑的基础上,将你的 vector_memory.py 升级为 交互式 CLI 程序的版本。用户可以:
- 动态添加记忆(如“我喜欢看电影”)
- 随时查询语义相关记忆(如“我讨厌什么?”)
- 输入
quit退出
这样实验过程更有“Agent 记忆”的感觉,也便于课堂演示。
tee vector_memory.py <<'EOF'
# day06/vector_memory.py
# 使用 DashScope 原生 API + 适配新版 LangChain 的向量记忆系统
import os
from dotenv import load_dotenv
import dashscope
from dashscope import TextEmbedding
from langchain_community.vectorstores import FAISS
from langchain_core.embeddings import Embeddings
from typing import List
# 加载环境变量
load_dotenv()
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY")
class DashScopeEmbeddings(Embeddings):
def __init__(self, model: str = "text-embedding-v2"):
self.model = model
def embed_documents(self, texts: List[str]) -> List[List[float]]:
texts = [t for t in texts if t.strip()]
if not texts:
return []
response = TextEmbedding.call(
model=self.model,
input=texts
)
if response.status_code != 200:
raise RuntimeError(f"Embedding failed: {response}")
return [item["embedding"] for item in response.output["embeddings"]]
def embed_query(self, text: str) -> List[float]:
return self.embed_documents([text])[0]
# 初始化
embeddings = DashScopeEmbeddings(model="text-embedding-v2")
initial_memories = [
"用户喜欢喝美式咖啡",
"用户住在杭州"
]
print("🧠 向量记忆系统启动中...")
vectorstore = FAISS.from_texts(initial_memories, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
print("✅ 系统就绪!")
print("\n💡 使用说明:")
print(" - 输入陈述句(如“我讨厌开会”)→ 保存为记忆")
print(" - 输入问句(如“我喜欢什么?”)→ 检索相关记忆")
print(" - 输入 'quit' 退出\n")
while True:
try:
user_input = input("🗨️ 请输入: ").strip()
except (KeyboardInterrupt, EOFError):
print("\n👋 再见!")
break
if not user_input:
continue
if user_input.lower() == "quit":
print("👋 再见!")
break
# 判断是否为查询(问句)
if user_input.endswith('?') or any(w in user_input for w in ["什么", "怎么", "是否", "吗", "呢", "为什么", "谁"]):
print(f"\n🔍 检索: 「{user_input}」")
docs = retriever.invoke(user_input) # ✅ 关键修复:用 .invoke() 替代 .get_relevant_documents()
if docs:
print("✅ 找到记忆:")
for i, doc in enumerate(docs, 1):
print(f" {i}. {doc.page_content}")
else:
print("❌ 无相关记忆")
print()
else:
# 规范化记忆文本
if user_input.startswith("我"):
memory_text = "用户" + user_input[1:]
elif not user_input.startswith("用户"):
memory_text = "用户" + user_input
else:
memory_text = user_input
vectorstore.add_texts([memory_text])
print(f"💾 已保存: 「{memory_text}」\n")
EOF
✨ 功能亮点
| 功能 | 说明 |
|---|---|
| 智能判断输入类型 | 以 ? 或疑问词(什么/吗/呢)结尾 → 查询;否则 → 添加记忆 |
| 自动规范化记忆文本 | 将“我喜欢吃苹果”转为“用户喜欢吃苹果”,保持格式统一 |
| 返回 Top-3 结果 | 避免只看第一条,提升语义覆盖 |
| 友好提示 | 清晰区分“存”和“查”操作 |
🧪 测试
💡先输入几条偏好,再用不同问法测试召回能力,感受“语义匹配” vs “关键词匹配”的区别。
架构正确,只是数据质量和检索策略需要优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号