Map(续)
3.Map练习
package com.zhang.map;
import java.util.*;
/**
* 是否需要重写equals()和hashcode(),是否需要继承Comparable接口,取决于Key是什么类型,key是Ingeter类型不需要,
* key是Student类型才需要。
*
* HashMap集合--唯一,无序
* LinkedHashMap集合--唯一,插入的顺序
* TreeMap集合--唯一,自然顺序
*
* 基本方法:
* map.containsKey()
* map.containsValue(),需重写equals()和hashcode()
* Set<Map.Entry<Integer, Student>> entrySet = map.entrySet();
*/
public class MapDemoTest {
public static void main(String[] args) {
//1.创建HashMap集合--唯一,无序
Map<Integer, Student> map = new HashMap<Integer, Student>();
Student stu1 = new Student(10, "zhangsan", 90.0, 20);
Student stu2 = new Student(20, "lisi", 93.0, 23);
Student stu3 = new Student(30, "wangwu", 97.0, 22);
Student stu4 = new Student(10, "zhangsan", 90.0, 20);
//存放数据
map.put(stu1.getId(), stu1);
map.put(stu2.getId(), stu2);
map.put(stu3.getId(), stu3);
map.put(stu4.getId(), stu4);
System.out.println(map.size());//3
System.out.println(map);// 唯一,无序 {20=Student{id=20, name='lisi', score=93.0, age=23},
// 10=Student{id=10, name='zhangsan',score=90.0, age=20}, 30=Student{id=30, name='wangwu', score=97.0, age=22}}
//2.创建LinkedHashMap集合--唯一,插入的顺序
Map<Integer, Student> map2 = new LinkedHashMap<Integer, Student>();
Student stu11 = new Student(10, "zhangsan", 90.0, 20);
Student stu22 = new Student(20, "lisi", 93.0, 23);
Student stu33 = new Student(30, "wangwu", 97.0, 22);
Student stu44 = new Student(10, "zhangsan", 90.0, 20);
//存放数据
map2.put(stu11.getId(), stu11);
map2.put(stu33.getId(), stu33);
map2.put(stu44.getId(), stu44);
map2.put(stu22.getId(), stu22);
System.out.println(map2.size());//3
System.out.println(map2);// 唯一,插入的顺序 {10=Student{id=10, name='zhangsan', score=90.0, age=20},
// 30=Student{id=30, name='wangwu', score=97.0, age=22}, 20=Student{id=20, name='lisi', score=93.0, age=23}}
//3.创建TreeMap集合--唯一,自然顺序
Map<Integer, Student> map3 = new TreeMap<Integer, Student>();
Student stu111 = new Student(10, "zhangsan", 90.0, 20);
Student stu222 = new Student(20, "lisi", 93.0, 23);
Student stu333 = new Student(30, "wangwu", 97.0, 22);
Student stu444 = new Student(10, "zhangsan", 90.0, 20);
//存放数据
map3.put(stu111.getId(), stu111);
map3.put(stu333.getId(), stu333);
map3.put(stu444.getId(), stu444);
map3.put(stu222.getId(), stu222);
System.out.println(map3.size());//3
System.out.println(map3);// 唯一,自然顺序 {10=Student{id=10, name='zhangsan', score=90.0, age=20},
// 20=Student{id=20, name='lisi', score=93.0, age=23}, 30=Student{id=30, name='wangwu', score=97.0, age=22}}
System.out.println("===========基本方法============");
System.out.println(map.containsKey(1));//是否含有值为1的key false
System.out.println(map.containsKey(10));//true
System.out.println(map.containsValue(new Student(20, "lisi", 93.0, 23)));//是否含有Value true
System.out.println(map.get(10));//获取key为10的value Student{id=10, name='zhangsan', score=90.0, age=20}
Student zhaoliu = map.replace(20, new Student(20, "zhaoliu", 89.0, 22));
System.out.println(map.get(20));//Student{id=20, name='zhaoliu', score=89.0, age=22}
//遍历
Set<Map.Entry<Integer, Student>> entrySet = map.entrySet();
Iterator<Map.Entry<Integer, Student>> iterator = entrySet.iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, Student> next = iterator.next();
//System.out.println(next);
System.out.println(next.getKey() + ":" + next.getValue());
}
//20=Student{id=20, name='zhaoliu', score=89.0, age=22}
//10=Student{id=10, name='zhangsan', score=90.0, age=20}
//30=Student{id=30, name='wangwu', score=97.0, age=22}
//20:Student{id=20, name='zhaoliu', score=89.0, age=22}
//10:Student{id=10, name='zhangsan', score=90.0, age=20}
//30:Student{id=30, name='wangwu', score=97.0, age=22}
}
}
4.HashMap源码
- jdk1.7及之前,HashMap底层采用的table数组+链表的哈希表存储结构
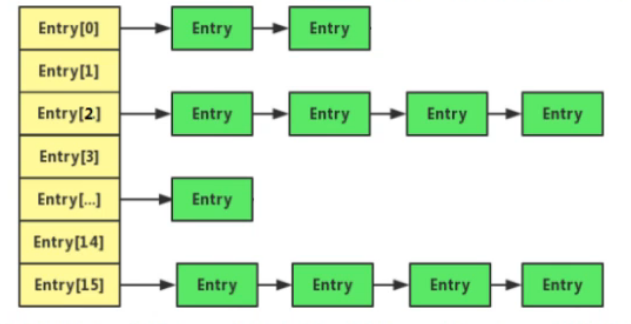
-
链表的每个节点是一个Entry,其中包括键key,值value,key的哈希码hash,执行下一个节点的引用next四部分

-
JDK1.7中HashMap的主要成员变量及含义

-
调用put方法添加键值对,哈希表三步添加数据的具体实现,是计算key的哈希码,和value无关
-
第一步计算哈希码时,不仅调用了Key的hashCode(),还进行了更复杂的处理,目的是保证key尽量得到不同的哈希码
-
第二步根据哈希码计算存储位置时,使用了位运算提高效率,同时也要求主数组的长度必须是2的幂
-
第三步添加Entry时,添加到链表的第一个位置,而不是链表的末尾
-
第三步添加Entry时,发现了相同的key已存在,就使用新的value代替旧的value,并返回旧的value
源码:
-
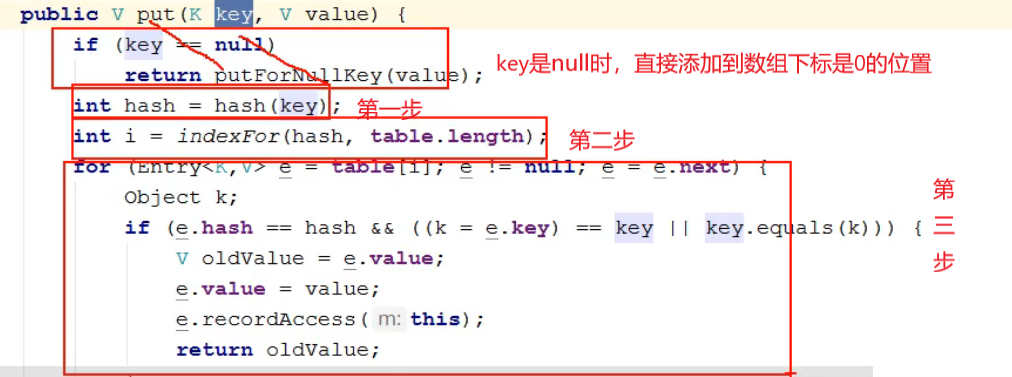
源码解析:


-
调用get方法根据key获取value
-
哈希表三步查询原理的实现
-
其实是根据key找到Entry,再从Entry中获取value

-
-
添加元素时,如达到阈值需扩容,每次扩容为原来主数组容量的两倍
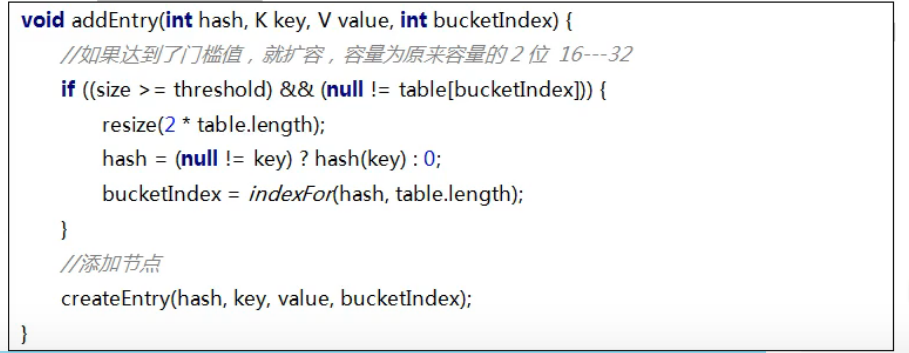
- jdk1.8中发生了变化,当链表的存储数据个数大于等于8的时候,不再采用链表存储,而是采用红黑树存储结构。这么做主要是查询的时间复杂度上,链表为O(n),红黑树为O(Log n),如果冲突多,并且超过8,采用红黑树提高效率

源码:
static final int TREEIFY_THRESHOLD = 8;//链表-红黑树的临界值
static final int UNTREEIFY_THRESHOLD = 6;//红黑树-链表的临界值
5.TreeMap源码
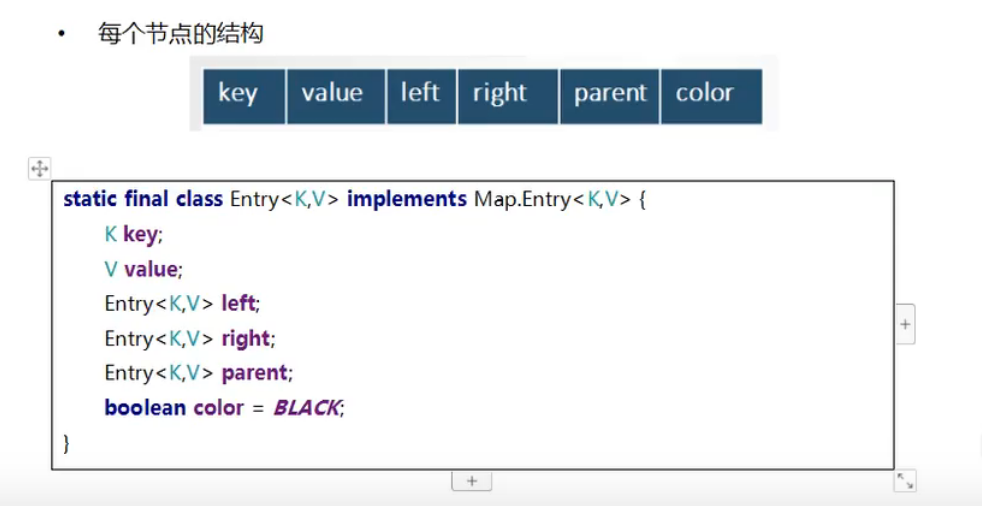


- TreeMap不能添加key是null的键,否则会报空指针
- 查询原理与添加基本相同
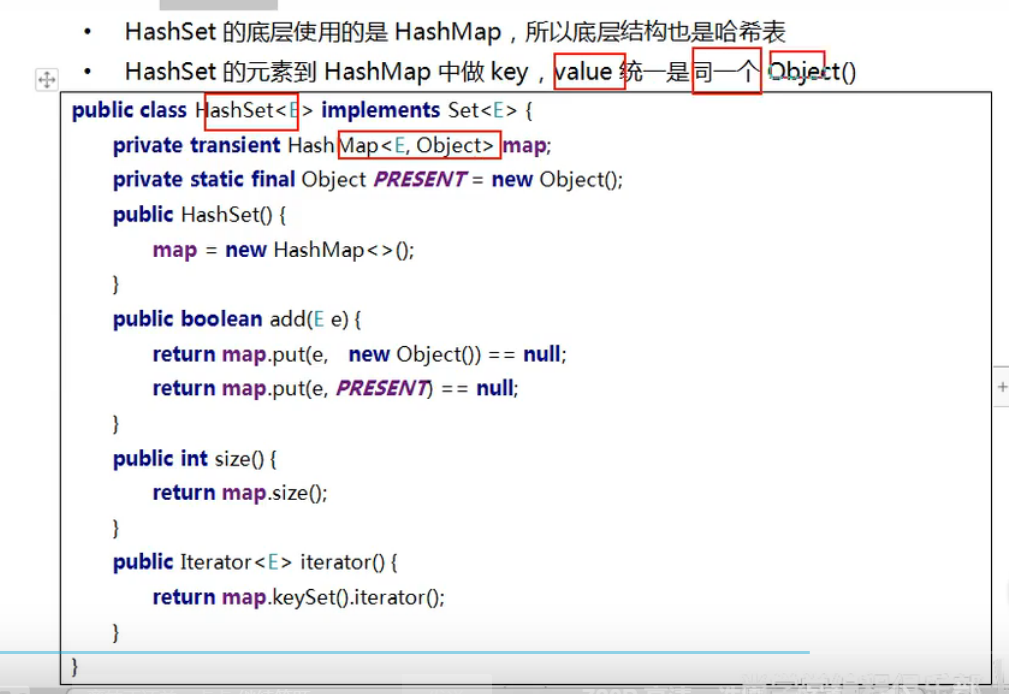
6.HashSet的底层是HashMap
6.TreeSet的底层是TreeMap
