

药品通用名和商品名称数据库下载
需求:如图,我想把药品商品名通用名称数据库中的所有药品的中文名称和商品名称获取到
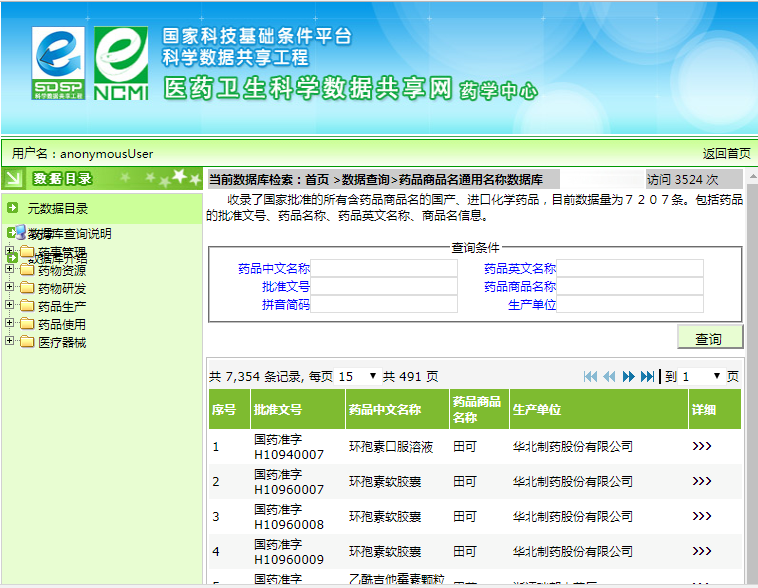
分析页面请求,共491页,共7354条记录,点击第二页
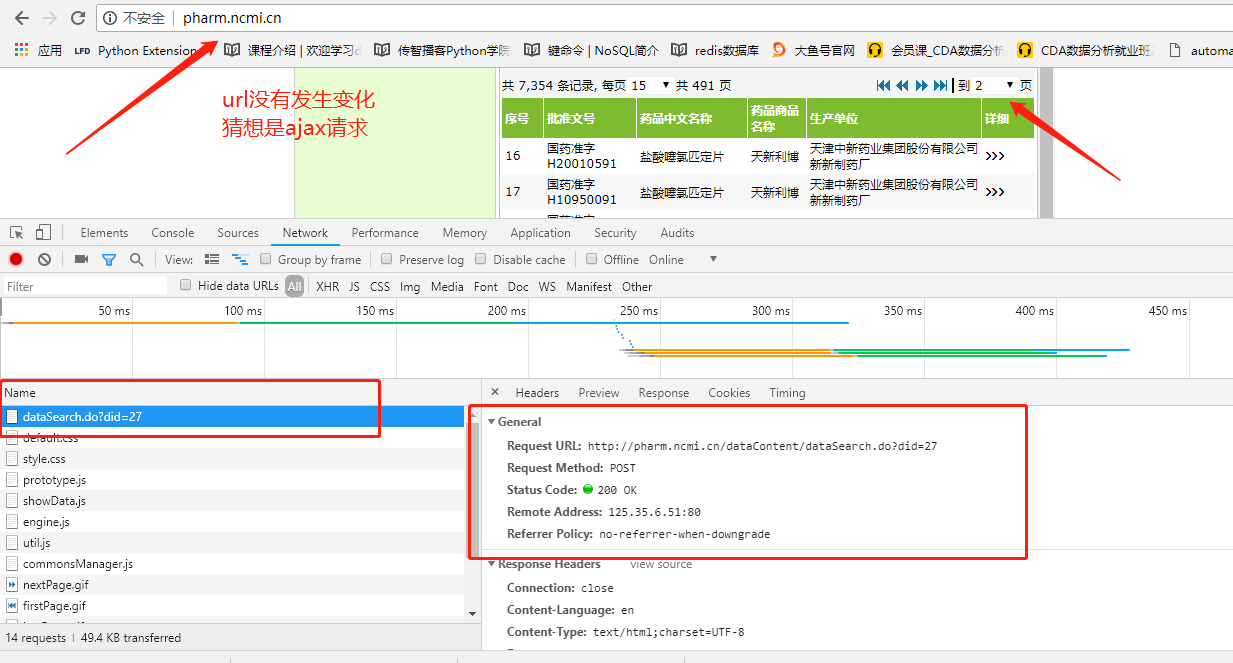
查看返回数据信息
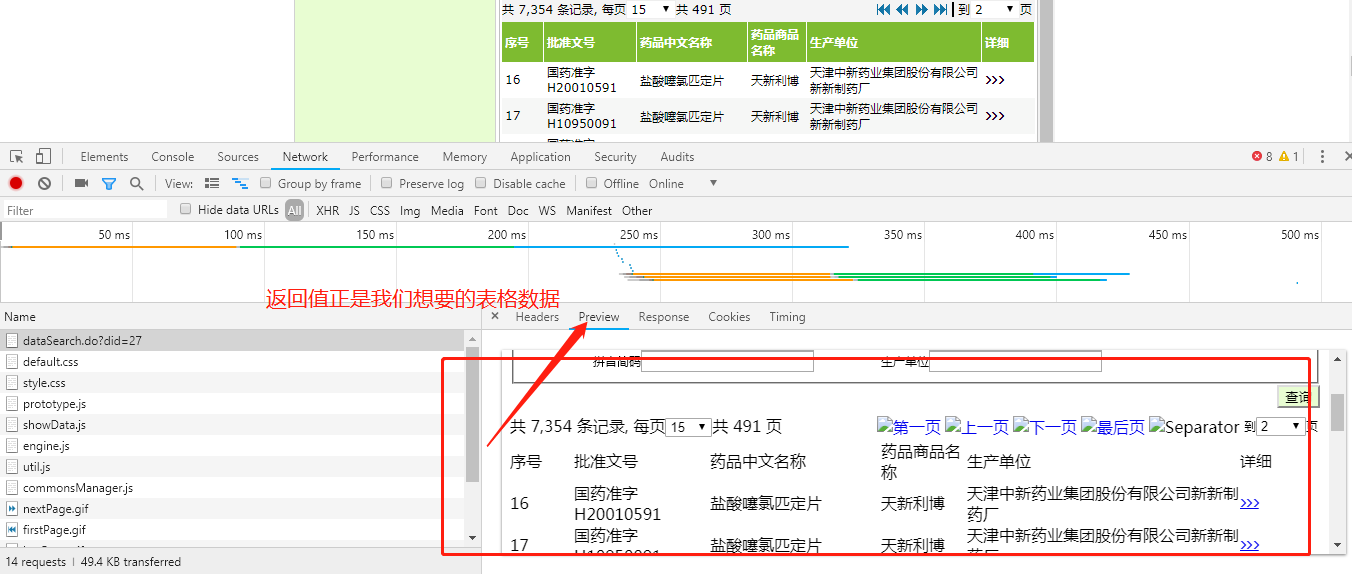
由此确定代码编写方案
- 1. 按照要求想指定url发送post请求下载所有491个页面
- 2. 将页面用pd.read_html将表格信息提取
- 3. 将提取表格存储为csv文件
- 4. 之后将数据进行分析
以下是完整代码
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/11/11
@Author: Zhang Yafei
"""
from multiprocessing import Pool
import pandas
import requests
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
HTML_DIR = os.path.join(BASE_DIR,'药品商品名通用名称数据库')
if not os.path.exists(HTML_DIR):
os.mkdir(HTML_DIR)
name_list = []
if os.path.exists('drug_name.csv'):
data = pandas.read_csv('drug_name.csv',encoding='utf-8')
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '248',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=0000ixyj6Mwe6Be4heuHcvtSW4C:-1; Hm_lvt_3849dadba32c9735c8c87ef59de6783c=1541937281; Hm_lpvt_3849dadba32c9735c8c87ef59de6783c=1541940406',
'Upgrade-Insecure-Requests': '1',
'Origin': 'http://pharm.ncmi.cn',
'Referer': 'http://pharm.ncmi.cn/dataContent/dataSearch.do?did=27',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
def spider(page):
adverse_url = 'http://pharm.ncmi.cn/dataContent/dataSearch.do?did=27'
form_data = {
'method': 'list',
'did': 27,
'ec_i': 'ec',
'ec_crd': 15,
'ec_p': page,
'ec_rd': 15,
'ec_pd': page,
}
response = requests.post(url=adverse_url,headers=header,data=form_data)
filename = '{}.html'.format(page)
with open(filename,'w',encoding='utf-8') as f:
f.write(response.text)
print(filename,'下载完成')
def get_response(page):
file = os.path.join(HTML_DIR,'{}.html')
with open(file.format(page),'r',encoding='utf-8') as f:
response = f.read()
return response
def parse(page):
response = get_response(page)
result = pandas.read_html(response,attrs={'id':'ec_table'})[0]
data = result.iloc[:,:5]
data.columns = ['序号','批准文号','药品中文名称','药品商品名称','生产单位']
if page==1:
data.to_csv('drug_name.csv',mode='w',encoding='utf_8_sig',index=False)
else:
data.to_csv('drug_name.csv',mode='a',encoding='utf_8_sig',header=False,index=False)
print('第{}页数据存取完毕'.format(page))
def get_unparse_data():
if os.path.exists('drug_name.csv'):
pages = data['序号']
pages = list(set(range(1,492))-set(pages.values))
else:
pages = list(range(1,492))
return pages
def download():
pool = Pool()
pool.map(spider,list(range(1,492)))
pool.close()
pool.join()
def write_to_csv():
pages = get_unparse_data()
print(pages)
list(map(parse,pages))
def new_data(chinese_name):
trade_name = '/'.join(set(data[data.药品中文名称==chinese_name].药品商品名称))
name_list.append(trade_name)
def read_from_csv():
name = data['药品中文名称'].values
print(len(name))
chinese_name = list(set(data['药品中文名称'].values))
list(map(new_data,chinese_name))
df_data = {'药品中文名称':chinese_name,'药品商品名称':name_list}
new_dataframe = pandas.DataFrame(df_data)
new_dataframe.to_csv('unique_chinese_name.csv',mode='w',encoding='utf_8_sig',index=False)
return new_dataframe
def main():
download()
write_to_csv()
# return read_from_csv()
if __name__ == '__main__':
main()
#drugname_dataframe = main()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号