


MapReduce遇到的坑
今天上课老师让做一个关于MapReduce的小实验,给了代码和教程,下面说一下我遇到的坑(我用的IDEA)
先在IDEA上新建一个mevan项目,然后写入相关的pom文件,然后新建一个类,类名:WordCount
之后直接上代码:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCount{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in =new Path("hdfs://master:9000/mymapreduce1/in/buyer_favorite1");
Path out = new Path("hdfs://master:9000/mymapreduce1/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
public static Text word =new Text() {
};
@Override
protected void map(Object key, Text value, Context context) throws IOException,InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString(),"\t");
word.set(tokenizer.nextToken());
context.write(word,one);
}
}
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key,Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values){
sum += value.get();
}
result.set(sum);
context.write(key,result);
}
}
}
要注意的是,上面导入的FileOutputFormat一定要是MapReduce下的,不然可能会导致FileOutputFormat.addInputPath()里面的参数只能使用jobconf,而我们要的是上面已经初始化好的job
除此之外还要将上面代码的Path中的“master”改成你所使用的虚拟机的名字,之后打包成jar文件,导入hadoop/share/hadoop/MapReduce文件夹中,打开虚拟机,开启yarn和hdfs,然后输入
hadoop jar (你的jar文件名).jar (类名)
之后就可以查看结果了:
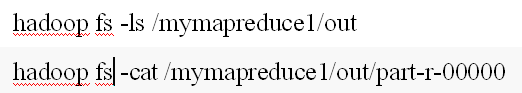
在那之前还有一些操作:

还要在这个基础下创建文件夹in
具体看图:
如果创建文件夹时遇到了权限问题,需要修改一个配置文件,具体忘了,可以去百度,很容易找到。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号