

python对文件的操作
对文件的操作,首先要知道文件的三个要素
1、文件的路径
路径分为绝对路径和相对路径
绝对路径:从根目录(盘符)开始到要查找的文件的路径
如:c:/xinli/sunxue/love/home
相对路径:是从当前路径开始到查找的文件的路径
如果现在上述路径中的sunxue,要查找home文件
相对路径就是:/love/home
2、文件的编码方式
utf-8、gb2312、big5、gbk等
3、对文件的操作方式
打开文件的方式: r, w, a, r+, w+, a+, rb, wb, ab, r+b, w+b, a+b 默认使用的是r(只读)模式
1、读
(1)、只读(r,rb),需要注意encoding表示编码集. 根据文件的实际保存编码进行获取数据, 通常是utf-8
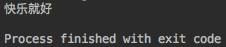
with open("新礼的秘密/生命的真意",mode="r",encoding="utf-8") as f: #也可以f=open("新礼的秘密/生命的真意",mode="r",encoding="utf-8") content=f.read() print(content) f.close()
以二进制只读(rb),rb.读取出来的数据是bytes类型, 在rb模式下. 不能选择encoding字符集.
rb的作用: 在读取非文本文件的时候. 比如读取MP3. 图像. 视频等信息的时候就需要用到
f=open("新礼的秘密/生命的真意",mode="rb") content=f.read() print(content) f.close()

read() 将文件中的内容全部读取出来. 弊端: 占内存. 如果文件过大.容易导致内存崩溃
read(n) 读取n个字符. 需要注意的是. 如果再次读取. 那么会在当前位置继续去读而不
是从头读, 如果使用的是rb模式. 则读取出来的是n个字节
(2)、readline() 一次读取一行数据
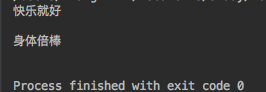
with open("新礼的秘密/生命的真意",mode="r",encoding="utf-8") as f: content1=f.readline() content2=f.readline() print(content1) print(content2) f.close()
(3)、readlines()将每一行形成一个元素, 放到一个列表中. 将所有的内容都读取出来
注意: readline()结尾, 注意每次读取出来的数据都会有一个\n 所以呢. 需要我们使用strip()方法来去掉\n或者空格
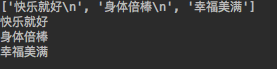
with open("新礼的秘密/生命的真意",mode="r",encoding="utf-8") as f: content=f.readlines() print(content) for i in content: print(i.strip('\n')) f.close()
注意: 读取完的文件句柄一定要关闭 f.close()
2、写
写的时候注意. 如果没有文件. 则会创建文件, 如果文件存在. 则将原件中原来的内容删除, 再
写入新内容
(1)、w,不能执行读操作
with open("新礼的秘密/生命的真意",mode="w",encoding="utf-8") as f: f.write('love') f.flush() #用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它 f.close()
(2)、wb
wb模式下. 可以不指定打开文件的编码. 但是在写文件的时候必须将字符串转化成utf-8的
bytes数据。
with open("新礼的秘密/生命的真意",mode="wb") as f: f.write('i love you'.encode('utf-8')) f.flush() f.close()
3、追加(a、ab)
在追加模式下. 我们写入的内容会追加在文件的结尾
with open("新礼的秘密/生命的真意",mode="a",encoding='utf-8') as f: f.write('i can give you the best of me') f.flush() f.close()
4、 读写模式(r+, r+b)
对于读写模式. 必须是先读. 因为默认光标是在开头的. 准备读取的. 当读完了之后再进行
写入. 我们以后使用频率最⾼的模式就是r+
5、写读(w+, w+b)
先将所有的内容清空. 然后写入. 最后读取. 但是读取的内容是空的, 不常用
有人会说. 先读不就好了么? 错. w+ 模式下, 一开始读取不到数据. 然后写的时候再将原来
的内容清空. 所以, 很少用
6、追加读(a+)
a+模式下, 不论先读还是后读. 都是读取不到数据的.
4、其他操作
1. seek(n) 光标移动到n位置, 注意, 移动的单位是byte. 所以如果是UTF-8的中文部分要
是3的倍数.通常我们使用seek都是移动到开头或者结尾.
移动到开头: seek(0)
移动到结尾: seek(0,2) seek的第二个参数表示的是从哪个位置进行偏移, 默认是0, 表
示开头, 1表示当前位置, 2表示结尾
f = open("新礼的秘密/生命的真意", mode="r+", encoding="utf-8") content1 = f.read() # 读取内容, 此时光标移动到结尾 print(content1) f.seek(0) # 将光标移动到开头 f.seek(0, 2) # 将光标移动到结尾 content2 = f.read() # 读取内容. 什么都没有 print(content2) f.seek(0) # 移动到开头 f.write("张新礼") # 写入信息. 此时光标在9 中文3 * 3个 = 9 f.flush() f.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号