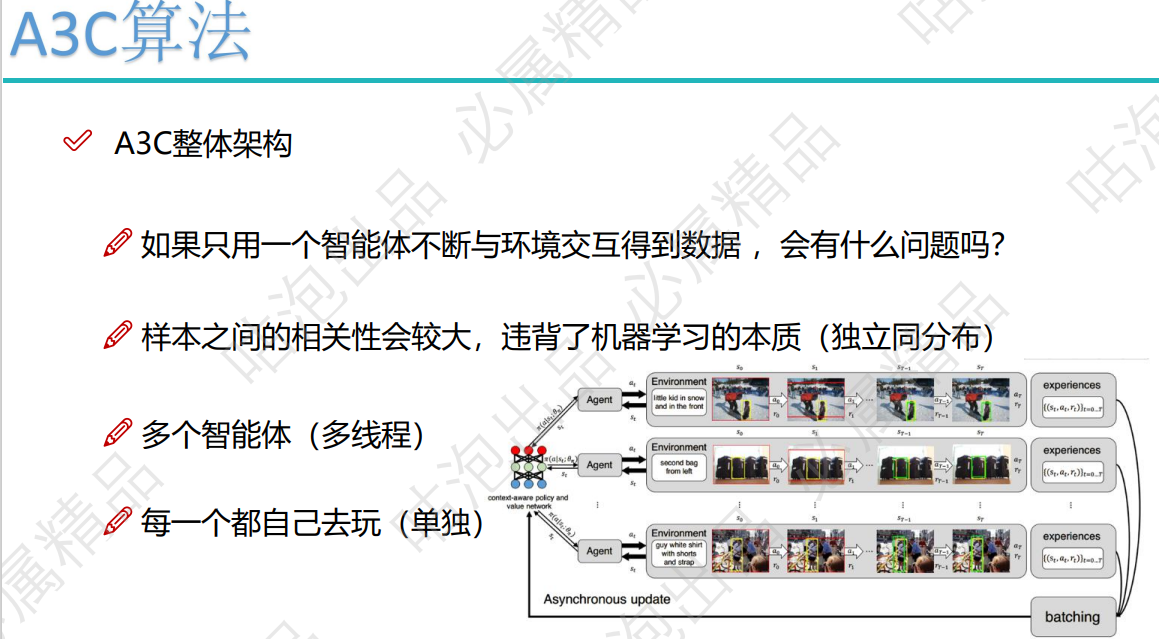
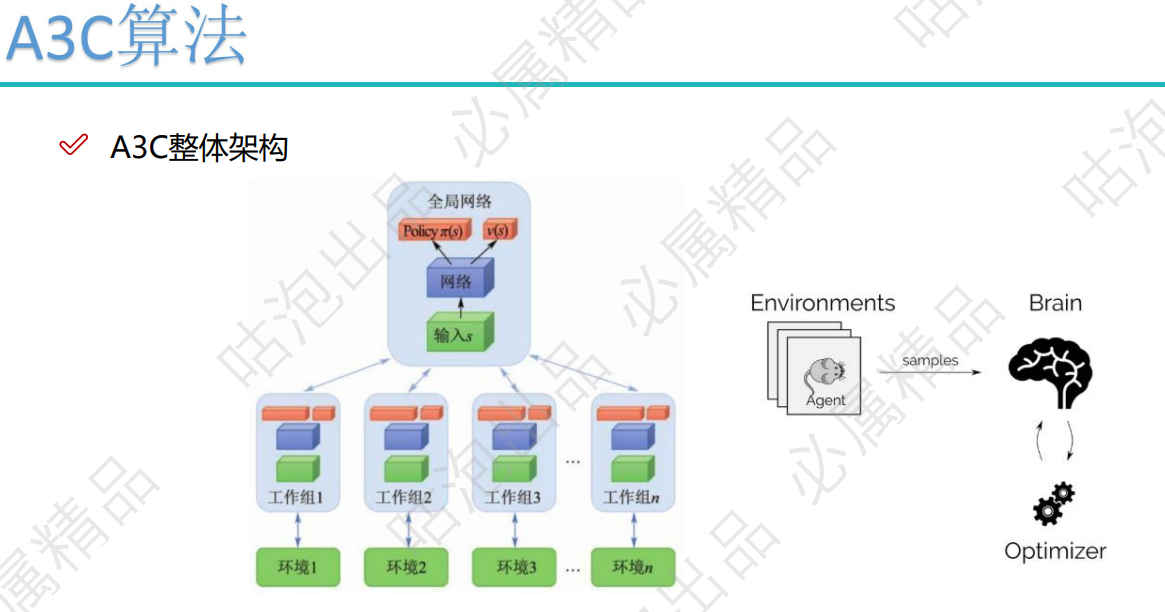
一、知识
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
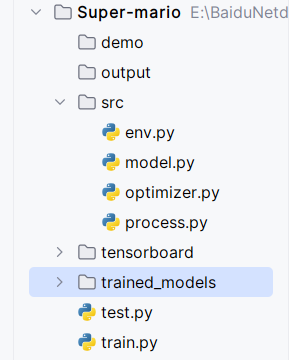
二、代码
1、6个py文件
![]()
2、train.py
import os
os.environ['OMP_NUM_THREADS'] = '1'
import argparse
import torch
from src.env import create_train_env
from src.model import ActorCritic
from src.optimizer import GlobalAdam
from src.process import local_train, local_test
import torch.multiprocessing as _mp
import shutil
# pip install gym_super_mario_bros
def get_args():
parser = argparse.ArgumentParser(
"""Implementation of model described in the paper: Asynchronous Methods for Deep Reinforcement Learning for Super Mario Bros""")
parser.add_argument("--world", type=int, default=1)
parser.add_argument("--stage", type=int, default=1)
parser.add_argument("--action_type", type=str, default="complex")
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--gamma', type=float, default=0.9, help='discount factor for rewards')
parser.add_argument('--tau', type=float, default=1.0, help='parameter for GAE')
parser.add_argument('--beta', type=float, default=0.01, help='entropy coefficient')
parser.add_argument("--num_local_steps", type=int, default=50)
parser.add_argument("--num_global_steps", type=int, default=5e6)
parser.add_argument("--num_processes", type=int, default=6)
parser.add_argument("--save_interval", type=int, default=500, help="Number of steps between savings")
parser.add_argument("--max_actions", type=int, default=200, help="Maximum repetition steps in test phase")
parser.add_argument("--log_path", type=str, default="tensorboard/a3c_super_mario_bros")
parser.add_argument("--saved_path", type=str, default="trained_models")
parser.add_argument("--load_from_previous_stage", type=bool, default=False,
help="Load weight from previous trained stage")
parser.add_argument("--use_gpu", type=bool, default=True)
args = parser.parse_args()
return args
def train(opt):
torch.manual_seed(123)
if os.path.isdir(opt.log_path):
shutil.rmtree(opt.log_path)
os.makedirs(opt.log_path)
if not os.path.isdir(opt.saved_path):
os.makedirs(opt.saved_path)
mp = _mp.get_context("spawn")
#world大关,stage小关
env, num_states, num_actions = create_train_env(opt.world, opt.stage, opt.action_type)#游戏环境配置
global_model = ActorCritic(num_states, num_actions)
if opt.use_gpu:
global_model.cuda()
global_model.share_memory()
if opt.load_from_previous_stage:
if opt.stage == 1:
previous_world = opt.world - 1
previous_stage = 4
else:
previous_world = opt.world
previous_stage = opt.stage - 1
file_ = "{}/a3c_super_mario_bros_{}_{}".format(opt.saved_path, previous_world, previous_stage)
if os.path.isfile(file_):
global_model.load_state_dict(torch.load(file_))
optimizer = GlobalAdam(global_model.parameters(), lr=opt.lr)
# local_train(0, opt, global_model, optimizer, True)
# local_test(opt.num_processes, opt, global_model)
processes = []
for index in range(opt.num_processes):
if index == 0:
process = mp.Process(target=local_train, args=(index, opt, global_model, optimizer, True))
else:
process = mp.Process(target=local_train, args=(index, opt, global_model, optimizer))
process.start()
processes.append(process)
process = mp.Process(target=local_test, args=(opt.num_processes, opt, global_model))
process.start()
processes.append(process)
for process in processes:
process.join()
if __name__ == "__main__":
opt = get_args()
train(opt)
2、test.py
import os
os.environ['OMP_NUM_THREADS'] = '1'
import argparse
import torch
from src.env import create_train_env
from src.model import ActorCritic
import torch.nn.functional as F
def get_args():
parser = argparse.ArgumentParser(
"""Implementation of model described in the paper: Asynchronous Methods for Deep Reinforcement Learning for Super Mario Bros""")
parser.add_argument("--world", type=int, default=4)
parser.add_argument("--stage", type=int, default=1)
parser.add_argument("--action_type", type=str, default="complex")
parser.add_argument("--saved_path", type=str, default="trained_models")
parser.add_argument("--output_path", type=str, default="output")
args = parser.parse_args()
return args
def test(opt):
torch.manual_seed(123)
env, num_states, num_actions = create_train_env(opt.world, opt.stage, opt.action_type,
"{}/video_{}_{}.mp4".format(opt.output_path, opt.world, opt.stage))
model = ActorCritic(num_states, num_actions)
if torch.cuda.is_available():
model.load_state_dict(torch.load("{}/a3c_super_mario_bros_{}_{}".format(opt.saved_path, opt.world, opt.stage)))
model.cuda()
else:
model.load_state_dict(torch.load("{}/a3c_super_mario_bros_{}_{}".format(opt.saved_path, opt.world, opt.stage),
map_location=lambda storage, loc: storage))
model.eval()
state = torch.from_numpy(env.reset())
done = True
while True:
if done:
h_0 = torch.zeros((1, 512), dtype=torch.float)
c_0 = torch.zeros((1, 512), dtype=torch.float)
env.reset()
else:
h_0 = h_0.detach()
c_0 = c_0.detach()
if torch.cuda.is_available():
h_0 = h_0.cuda()
c_0 = c_0.cuda()
state = state.cuda()
logits, value, h_0, c_0 = model(state, h_0, c_0)
policy = F.softmax(logits, dim=1)
action = torch.argmax(policy).item()
action = int(action)
state, reward, done, info = env.step(action)
state = torch.from_numpy(state)
env.render()
if info["flag_get"]:
print("World {} stage {} completed".format(opt.world, opt.stage))
break
if __name__ == "__main__":
opt = get_args()
test(opt)
3、env.py
import gym_super_mario_bros
from gym.spaces import Box
from gym import Wrapper
#from nes_py.wrappers import BinarySpaceToDiscreteSpaceEnv
from gym.wrappers import JoypadSpace
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT, COMPLEX_MOVEMENT, RIGHT_ONLY
import cv2
import numpy as np
import subprocess as sp
class Monitor:
def __init__(self, width, height, saved_path):
self.command = ["ffmpeg", "-y", "-f", "rawvideo", "-vcodec", "rawvideo", "-s", "{}X{}".format(width, height),
"-pix_fmt", "rgb24", "-r", "80", "-i", "-", "-an", "-vcodec", "mpeg4", saved_path]
try:
self.pipe = sp.Popen(self.command, stdin=sp.PIPE, stderr=sp.PIPE)
except FileNotFoundError:
pass
def record(self, image_array):
self.pipe.stdin.write(image_array.tostring())
def process_frame(frame):
if frame is not None:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
frame = cv2.resize(frame, (84, 84))[None, :, :] / 255.
return frame
else:
return np.zeros((1, 84, 84))
class CustomReward(Wrapper):
def __init__(self, env=None, monitor=None):
super(CustomReward, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(1, 84, 84))
self.curr_score = 0
if monitor:
self.monitor = monitor
else:
self.monitor = None
def step(self, action):
state, reward, done, info = self.env.step(action)
if self.monitor:
self.monitor.record(state)
state = process_frame(state)
reward += (info["score"] - self.curr_score) / 40.
self.curr_score = info["score"]
if done:
if info["flag_get"]:
reward += 50
else:
reward -= 50
return state, reward / 10., done, info
def reset(self):
self.curr_score = 0
return process_frame(self.env.reset())
class CustomSkipFrame(Wrapper):
def __init__(self, env, skip=4):
super(CustomSkipFrame, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(4, 84, 84))
self.skip = skip
def step(self, action):
total_reward = 0
states = []
state, reward, done, info = self.env.step(action)
for i in range(self.skip):
if not done:
state, reward, done, info = self.env.step(action)
total_reward += reward
states.append(state)
else:
states.append(state)
states = np.concatenate(states, 0)[None, :, :, :]
return states.astype(np.float32), reward, done, info
def reset(self):
state = self.env.reset()
states = np.concatenate([state for _ in range(self.skip)], 0)[None, :, :, :]
return states.astype(np.float32)
def create_train_env(world, stage, action_type, output_path=None):
env = gym_super_mario_bros.make("SuperMarioBros-{}-{}-v0".format(world, stage))
if output_path:
monitor = Monitor(256, 240, output_path)
else:
monitor = None
if action_type == "right":
actions = RIGHT_ONLY
elif action_type == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
env = JoypadSpace(env, actions)
env = CustomReward(env, monitor)
env = CustomSkipFrame(env)
return env, env.observation_space.shape[0], len(actions)
4、model
import torch.nn as nn
import torch.nn.functional as F
class ActorCritic(nn.Module):
def __init__(self, num_inputs, num_actions):
super(ActorCritic, self).__init__()
self.conv1 = nn.Conv2d(num_inputs, 32, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.lstm = nn.LSTMCell(32 * 6 * 6, 512)
self.critic_linear = nn.Linear(512, 1)
self.actor_linear = nn.Linear(512, num_actions)
self._initialize_weights()
def _initialize_weights(self):
for module in self.modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
nn.init.xavier_uniform_(module.weight)
# nn.init.kaiming_uniform_(module.weight)
nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.LSTMCell):
nn.init.constant_(module.bias_ih, 0)
nn.init.constant_(module.bias_hh, 0)
def forward(self, x, hx, cx):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
hx, cx = self.lstm(x.view(x.size(0), -1), (hx, cx))
return self.actor_linear(hx), self.critic_linear(hx), hx, cx#隐层和记忆单元
5、optimal.py
import torch
class GlobalAdam(torch.optim.Adam):
def __init__(self, params, lr):
super(GlobalAdam, self).__init__(params, lr=lr)
for group in self.param_groups:
for p in group['params']:
state = self.state[p]
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p.data)
state['exp_avg_sq'] = torch.zeros_like(p.data)
state['exp_avg'].share_memory_()
state['exp_avg_sq'].share_memory_()
6、process.py
import torc
from src.env import create_train_env
from src.model import ActorCritic
import torch.nn.functional as F
from torch.distributions import Categorical
from collections import deque
from tensorboardX import SummaryWriter
import timeit
def local_train(index, opt, global_model, optimizer, save=False):
torch.manual_seed(123 + index)
if save:
start_time = timeit.default_timer()
writer = SummaryWriter(opt.log_path)
env, num_states, num_actions = create_train_env(opt.world, opt.stage, opt.action_type)#单独玩
local_model = ActorCritic(num_states, num_actions)
if opt.use_gpu:
local_model.cuda()
local_model.train()
state = torch.from_numpy(env.reset())
if opt.use_gpu:
state = state.cuda()
done = True
curr_step = 0
curr_episode = 0
while True:
if save:
if curr_episode % opt.save_interval == 0 and curr_episode > 0:
torch.save(global_model.state_dict(),
"{}/a3c_super_mario_bros_{}_{}".format(opt.saved_path, opt.world, opt.stage))
print("Process {}. Episode {}".format(index, curr_episode))
curr_episode += 1
local_model.load_state_dict(global_model.state_dict())
if done:
h_0 = torch.zeros((1, 512), dtype=torch.float)
c_0 = torch.zeros((1, 512), dtype=torch.float)
else:
h_0 = h_0.detach()
c_0 = c_0.detach()
if opt.use_gpu:
h_0 = h_0.cuda()
c_0 = c_0.cuda()
log_policies = []
values = []
rewards = []
entropies = []
for _ in range(opt.num_local_steps):
curr_step += 1
logits, value, h_0, c_0 = local_model(state, h_0, c_0)#return self.actor_linear(hx), self.critic_linear(hx), hx, cx#隐层和记忆单元
policy = F.softmax(logits, dim=1)
log_policy = F.log_softmax(logits, dim=1)
entropy = -(policy * log_policy).sum(1, keepdim=True)#计算当前熵值
m = Categorical(policy)#采样
action = m.sample().item()
state, reward, done, _ = env.step(action)
state = torch.from_numpy(state)
if opt.use_gpu:
state = state.cuda()
if curr_step > opt.num_global_steps:
done = True
if done:
curr_step = 0
state = torch.from_numpy(env.reset())
if opt.use_gpu:
state = state.cuda()
values.append(value)
log_policies.append(log_policy[0, action])
rewards.append(reward)
entropies.append(entropy)
if done:
break
R = torch.zeros((1, 1), dtype=torch.float)
if opt.use_gpu:
R = R.cuda()
if not done:
_, R, _, _ = local_model(state, h_0, c_0)#这个R相当于最后一次的V值,第二个返回值是critic网络的
gae = torch.zeros((1, 1), dtype=torch.float)#额外的处理,为了减小variance
if opt.use_gpu:
gae = gae.cuda()
actor_loss = 0
critic_loss = 0
entropy_loss = 0
next_value = R
for value, log_policy, reward, entropy in list(zip(values, log_policies, rewards, entropies))[::-1]:
gae = gae * opt.gamma * opt.tau
gae = gae + reward + opt.gamma * next_value.detach() - value.detach()#Generalized Advantage Estimator 带权重的折扣项,V(s+1)-V(s)
next_value = value
actor_loss = actor_loss + log_policy * gae
R = R * opt.gamma + reward
critic_loss = critic_loss + (R - value) ** 2 / 2
entropy_loss = entropy_loss + entropy
total_loss = -actor_loss + critic_loss - opt.beta * entropy_loss
writer.add_scalar("Train_{}/Loss".format(index), total_loss, curr_episode)
optimizer.zero_grad()
total_loss.backward()
for local_param, global_param in zip(local_model.parameters(), global_model.parameters()):
if global_param.grad is not None:
break
global_param._grad = local_param.grad
optimizer.step()
if curr_episode == int(opt.num_global_steps / opt.num_local_steps):
print("Training process {} terminated".format(index))
if save:
end_time = timeit.default_timer()
print('The code runs for %.2f s ' % (end_time - start_time))
return
def local_test(index, opt, global_model):
torch.manual_seed(123 + index)
env, num_states, num_actions = create_train_env(opt.world, opt.stage, opt.action_type)
local_model = ActorCritic(num_states, num_actions)
local_model.eval()
state = torch.from_numpy(env.reset())
done = True
curr_step = 0
actions = deque(maxlen=opt.max_actions)
while True:
curr_step += 1
if done:
local_model.load_state_dict(global_model.state_dict())
with torch.no_grad():
if done:
h_0 = torch.zeros((1, 512), dtype=torch.float)
c_0 = torch.zeros((1, 512), dtype=torch.float)
else:
h_0 = h_0.detach()
c_0 = c_0.detach()
logits, value, h_0, c_0 = local_model(state, h_0, c_0)
policy = F.softmax(logits, dim=1)
action = torch.argmax(policy).item()
state, reward, done, _ = env.step(action)
env.render()
actions.append(action)
if curr_step > opt.num_global_steps or actions.count(actions[0]) == actions.maxlen:
done = True
if done:
curr_step = 0
actions.clear()
state = env.reset()
state = torch.from_numpy(state)









 浙公网安备 33010602011771号
浙公网安备 33010602011771号