import torch
import torch.nn as nn
from torch.distributions import Categorical
import gymnasium as gym
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Memory:
def __init__(self):
self.actions = []
self.states = []
self.logprobs = []
self.rewards = []
self.is_terminals = []
def clear_memory(self):
del self.actions[:]
del self.states[:]
del self.logprobs[:]
del self.rewards[:]
del self.is_terminals[:]
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim, n_latent_var):
super(ActorCritic, self).__init__()
# actor,4个动作
self.action_layer = nn.Sequential(
nn.Linear(state_dim, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, action_dim),
nn.Softmax(dim=-1)
)
# critic,得到一个b,value值
self.value_layer = nn.Sequential(
nn.Linear(state_dim, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, n_latent_var),
nn.Tanh(),
nn.Linear(n_latent_var, 1)
)
def forward(self):
raise NotImplementedError
def act(self, state, memory):
state = torch.from_numpy(state).float().to(device)
action_probs = self.action_layer(state)
dist = Categorical(action_probs)#按照给定的概率分布
action = dist.sample()#根据给定概率分布采样
memory.states.append(state)
memory.actions.append(action)
memory.logprobs.append(dist.log_prob(action))
return action.item()
def evaluate(self, state, action):
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action_logprobs = dist.log_prob(action)
dist_entropy = dist.entropy()
state_value = self.value_layer(state)
return action_logprobs, torch.squeeze(state_value), dist_entropy
class PPO:
def __init__(self, state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip):
self.lr = lr
self.betas = betas
self.gamma = gamma
self.eps_clip = eps_clip
self.K_epochs = K_epochs
self.policy = ActorCritic(state_dim, action_dim, n_latent_var).to(device)
self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr, betas=betas)
self.policy_old = ActorCritic(state_dim, action_dim, n_latent_var).to(device) #上一次的策略
self.policy_old.load_state_dict(self.policy.state_dict())#刚开始权重一样
self.MseLoss = nn.MSELoss()
def update(self, memory):
# Monte Carlo estimate of state rewards:
rewards = [] #非当前奖励打折
discounted_reward = 0
for reward, is_terminal in zip(reversed(memory.rewards), reversed(memory.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
rewards.insert(0, discounted_reward)
# Normalizing the rewards:
rewards = torch.tensor(rewards, dtype=torch.float32).to(device)
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5)
#reword标准化
# convert list to tensor
#每2000个数据训练一次
old_states = torch.stack(memory.states).to(device).detach()
old_actions = torch.stack(memory.actions).to(device).detach()
old_logprobs = torch.stack(memory.logprobs).to(device).detach()
# Optimize policy for K epochs:
for _ in range(self.K_epochs):#训练4轮
# Evaluating old actions and values :
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
# Finding the ratio (pi_theta / pi_theta__old):
ratios = torch.exp(logprobs - old_logprobs.detach())
# Finding Surrogate Loss:
advantages = rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy
# take gradient step
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
# Copy new weights into old policy:
self.policy_old.load_state_dict(self.policy.state_dict())
def main():
############## Hyperparameters ##############
env_name = "LunarLander-v2"
# creating environment
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 4
render = False #不用放游戏图
solved_reward = 230 # stop training if avg_reward > solved_reward,终止条件
log_interval = 20 # print avg reward in the interval
max_episodes = 50000 # max training episodes 最多重玩多少次
max_timesteps = 300 # max timesteps in one episode,每一次操作上限
n_latent_var = 64 # number of variables in hidden layer,隐藏神经元的数量
update_timestep = 2000 # update policy every n timesteps,获取多少数据后进行学习
lr = 0.002
betas = (0.9, 0.999)
gamma = 0.99 # discount factor
K_epochs = 4 # update policy for K epochs,前一轮数据学多少次
eps_clip = 0.2 # clip parameter for PPO
random_seed = None
#############################################
if random_seed:
torch.manual_seed(random_seed)
env.seed(random_seed)
memory = Memory()#保存训练数据
ppo = PPO(state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip)
#print(lr,betas)
# logging variables
running_reward = 0
avg_length = 0
timestep = 0
# training loop
for i_episode in range(1, max_episodes+1):
state = env.reset()[0]#初始化(重新玩)
for t in range(max_timesteps):#每次玩300个动作
timestep += 1
# Running policy_old:
action = ppo.policy_old.act(state, memory) #old是打工的,产生数据。
state, reward, done, _, _ = env.step(action)#得到(新的状态,奖励,是否终止,额外的调试信息)
# Saving reward and is_terminal:
memory.rewards.append(reward)
memory.is_terminals.append(done)
# update if its time
if timestep % update_timestep == 0:
ppo.update(memory)
memory.clear_memory()
timestep = 0
running_reward += reward
if render:
env.render()
if done:
break
avg_length += t
# stop training if avg_reward > solved_reward
if running_reward > (log_interval*solved_reward):
print("########## Solved! ##########")
torch.save(ppo.policy.state_dict(), './PPO_{}.pth'.format(env_name))
break
# logging
if i_episode % log_interval == 0:
avg_length = int(avg_length/log_interval)
running_reward = int((running_reward/log_interval))
print('Episode {} \t avg length: {} \t reward: {}'.format(i_episode, avg_length, running_reward))
running_reward = 0
avg_length = 0
if __name__ == '__main__':
main()
import gym
from PPO import PPO, Memory
from PIL import Image
import torch
def test():
############## Hyperparameters ##############
env_name = "LunarLander-v2"
# creating environment
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 4
render = True
max_timesteps = 500
n_latent_var = 64 # number of variables in hidden layer
lr = 0.0007
betas = (0.9, 0.999)
gamma = 0.99 # discount factor
K_epochs = 4 # update policy for K epochs
eps_clip = 0.2 # clip parameter for PPO
#############################################
n_episodes = 3
max_timesteps = 300
render = True
save_gif = False
filename = "PPO_{}.pth".format(env_name)
directory = "./preTrained/"
memory = Memory()
ppo = PPO(state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip)
ppo.policy_old.load_state_dict(torch.load(directory+filename),strict=False)
for ep in range(1, n_episodes+1):
ep_reward = 0
state = env.reset()
for t in range(max_timesteps):
action = ppo.policy_old.act(state, memory)
state, reward, done, _ = env.step(action)
ep_reward += reward
if render:
env.render()
if save_gif:
img = env.render(mode = 'rgb_array')
img = Image.fromarray(img)
img.save('./gif/{}.jpg'.format(t))
if done:
break
print('Episode: {}\tReward: {}'.format(ep, int(ep_reward)))
ep_reward = 0
env.close()
if __name__ == '__main__':
test()


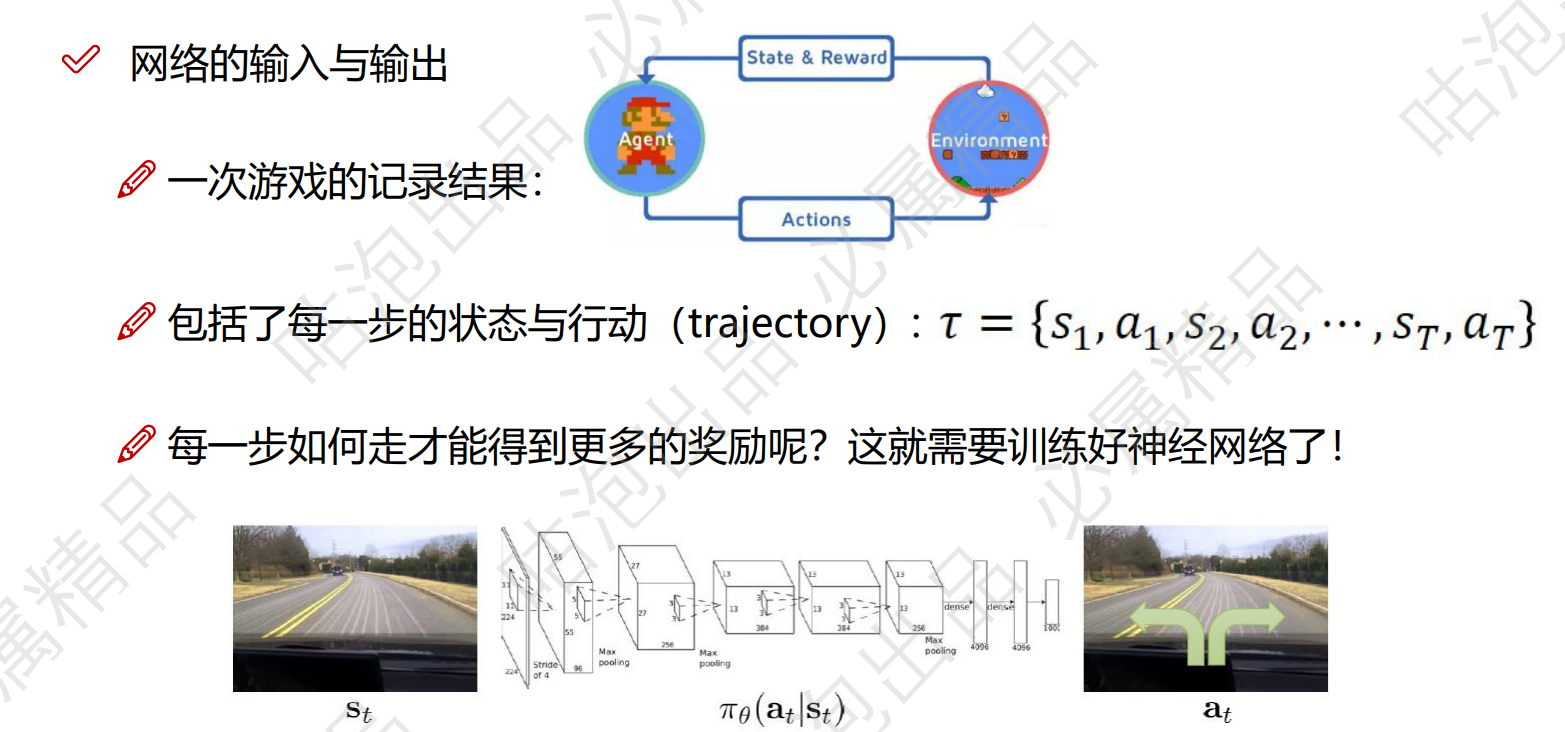





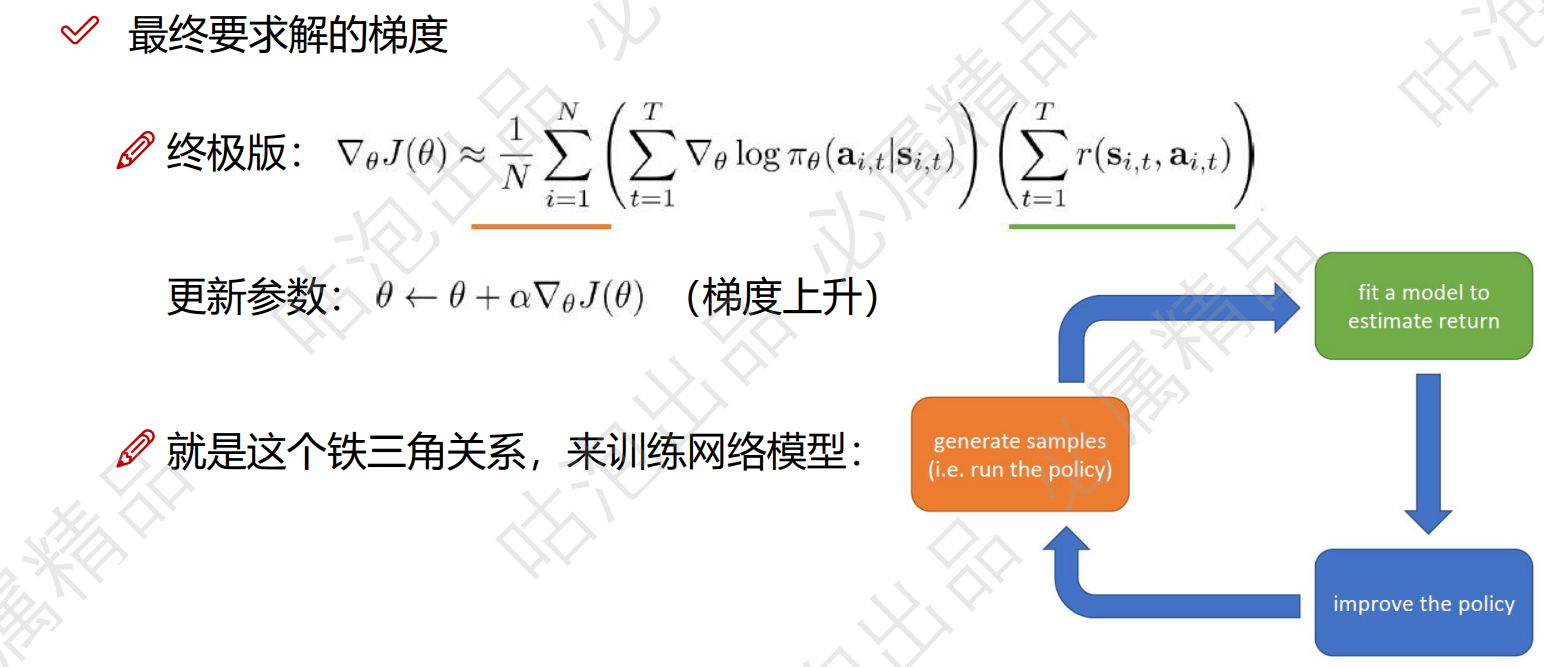








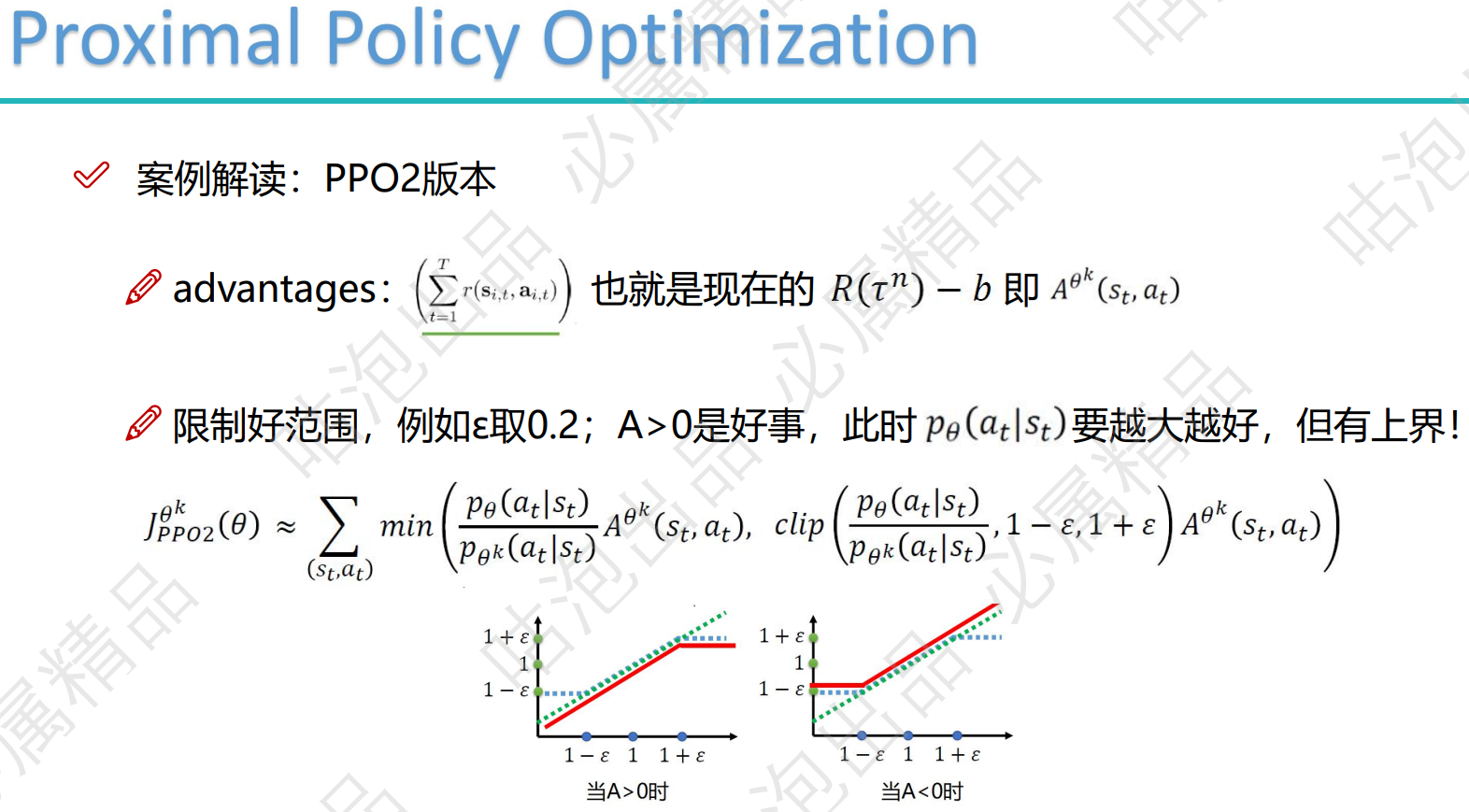

 浙公网安备 33010602011771号
浙公网安备 33010602011771号