

(九)混淆矩阵与绘图
一、基本概念
当说到召回率的时候就说到了混淆矩阵。
再回顾一下召回率吧,案例中有100个正例,猜中(预测对)了59个,我们就说召回率为59%。
召回率就是猜中率。
当时也讲到,正例和反例,加上猜中和猜错,总共有四种情况

所谓召回率,仅仅是其中的四分之一。在条件允许(资本充足)的情况下,我们关心的,也是实际有用的,的确是召回率。
但是实际条件并不允许我们这么单一,现实对我们的要求不仅是增加猜中的概率,也需要降低猜错的概率。
同时,关键的一个隐蔽点,在于数量的限制,50个男生,50个女生,我猜全部是男生,就会发现这种奇葩情况:
召回率100%,但是其他分布惨不忍睹。
隐藏的,就是可以猜的个数。
当然,我们可以把猜的个数做一个限制,但是这只是在已知的情境下才有具体的作用,位置的情况下,谁也说不准100个人中到底有多少个男生,多少个女生,可取的范围的确是[0,100]。
综上所述,对于一个模型的评估,所谓的召回率只能是在其他情况下都"不太差"的情况下才有对比的意义,或者说是只在乎"召回率",也就是错杀一千也不放过一个,不在乎浪费和消耗的情况下才有追逐的价值。
普遍的情况,追求的当然是全面,用最少的资源做最多的事情。也就是说,我们需要对样本的分布和预测的分布进行综合的考量,从各方面对模型进行评估和约束,才能够达到预期的目标。
而上面的2*2的分布表格,就是我们所谓的混淆矩阵。
当样本分布为3类的时候,猜测也为3类
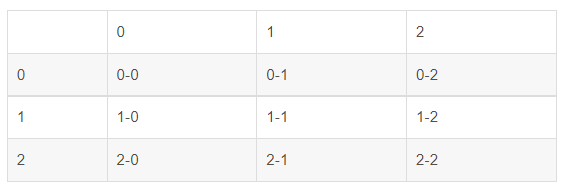
其他先不管,至少我们可以先得出一个结论:
混淆矩阵始终是方阵。
把对错继续划分,样本除了猜对和猜错,具体可以划分为猜对,猜成?类,数据中类越多,这种也就更加具体规范。
混淆矩阵的意义在于弥补错(and)误,我们也要明晰这个误区:不是成功率提高了错误率就会降低。
或许更具体的说起,就是我们的"成功"也是有水分的,TP是成功,TN是FP水分,TN是错漏,FT是有效排除。
真实的结果不仅在于找到对的,还在于排除错的。单方面的前进,或许会覆盖正确,但是也会错过正确,偏离正确。
只有两头逼近,才能够真正的定位正确,或锁定在一个较小的区间范围内(夹逼定则)。
二、函数
1、召回率
from sklearn.metrics import confusion_matrix from sklearn.metrics import recall_score guess = [1, 0, 1, 0, 1, 0, 1, 0, 1, 0] fact = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] a = recall_score(guess, fact) print(a) ''' 0.0 '''
这个会自动计算,主要的过程就是"对号入座"
(1)数据对
(2)位置对
首先,它会把实际结果和预测结果组成数据对,才到后来的判断阶段。
判断的时候,只考虑对错,按照如下的表进行计算。
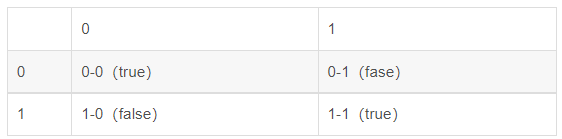
全部的数组合成一个个数据对,然后按照这种分布情况表进行统计,正对角线上的都是预测正确的,这就加一,最后正确数的除以总数就得出来了所谓的召回率。
from sklearn.metrics import confusion_matrix from sklearn.metrics import recall_score guess = [1, 0, 1, 0, 1, 0, 1, 0, 1, 0] fact = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] a = confusion_matrix(guess, fact) print(a) ''' [[0 5] [5 0]] '''
图表表示一下
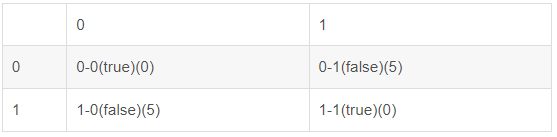
恩...说了半天都觉得混淆矩阵比召回率高级多了,事实打脸了,的确是有了混淆矩阵(混淆统计)才计算召回率的。
即使是召回率感觉高级一些,但是混淆矩阵更详细,这才是避免更大失误的关注点。
尤其是多种分类的情况下
from sklearn.metrics import confusion_matrix from sklearn.metrics import recall_score guess = [1, 0, 1, 2, 1, 0, 1, 0, 1, 0] fact = [0, 1, 0, 1, 2, 1, 0, 1, 0, 1] a = confusion_matrix(guess, fact) print(a) ''' [[0 4 0] [4 0 1] [0 1 0]] '''
三、绘图
混淆矩阵重要吧,不过谁知道啊,谁关心啊,数据人家感触不到,也不一定深刻理解,怎么办,画图呗。
from sklearn.metrics import confusion_matrix from sklearn.metrics import recall_score import matplotlib.pyplot as plt guess = [1, 0, 1] fact = [0, 1, 0] classes = list(set(fact)) classes.sort() confusion = confusion_matrix(guess, fact) plt.imshow(confusion, cmap=plt.cm.Blues) indices = range(len(confusion)) plt.xticks(indices, classes) plt.yticks(indices, classes) plt.colorbar() plt.xlabel('guess') plt.ylabel('fact') for first_index in range(len(confusion)): for second_index in range(len(confusion[first_index])): plt.text(first_index, second_index, confusion[first_index][second_index]) plt.show()
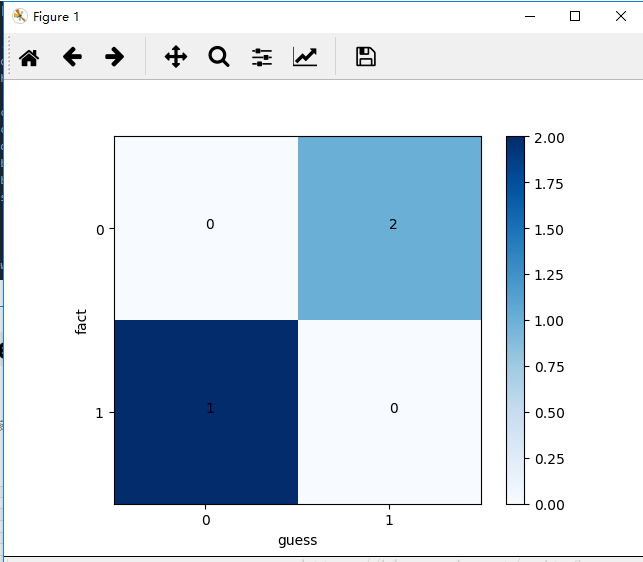
复杂一点
from sklearn.metrics import confusion_matrix from sklearn.metrics import recall_score import matplotlib.pyplot as plt guess = [1, 0, 1, 2, 1, 0, 1, 0, 1, 0] fact = [0, 1, 0, 1, 2, 1, 0, 1, 0, 1] classes = list(set(fact)) classes.sort() confusion = confusion_matrix(guess, fact) plt.imshow(confusion, cmap=plt.cm.Blues) indices = range(len(confusion)) plt.xticks(indices, classes) plt.yticks(indices, classes) plt.colorbar() plt.xlabel('guess') plt.ylabel('fact') for first_index in range(len(confusion)): for second_index in range(len(confusion[first_index])): plt.text(first_index, second_index, confusion[first_index][second_index]) plt.show()
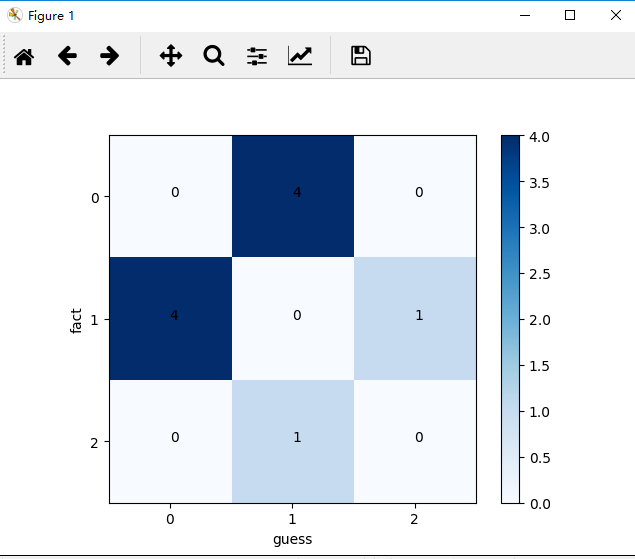
讲解一波
from sklearn.metrics import confusion_matrix from sklearn.metrics import recall_score import matplotlib.pyplot as plt # 预测数据,predict之后的预测结果集 guess = [1, 0, 1, 2, 1, 0, 1, 0, 1, 0] # 真实结果集 fact = [0, 1, 0, 1, 2, 1, 0, 1, 0, 1] # 类别 classes = list(set(fact)) # 排序,准确对上分类结果 classes.sort() # 对比,得到混淆矩阵 confusion = confusion_matrix(guess, fact) # 热度图,后面是指定的颜色块,gray也可以,gray_x反色也可以 plt.imshow(confusion, cmap=plt.cm.Blues) # 这个东西就要注意了 # ticks 这个是坐标轴上的坐标点 # label 这个是坐标轴的注释说明 indices = range(len(confusion)) # 坐标位置放入 # 第一个是迭代对象,表示坐标的顺序 # 第二个是坐标显示的数值的数组,第一个表示的其实就是坐标显示数字数组的index,但是记住必须是迭代对象 plt.xticks(indices, classes) plt.yticks(indices, classes) # 热度显示仪?就是旁边的那个验孕棒啦 plt.colorbar() # 就是坐标轴含义说明了 plt.xlabel('guess') plt.ylabel('fact') # 显示数据,直观些 for first_index in range(len(confusion)): for second_index in range(len(confusion[first_index])): plt.text(first_index, second_index, confusion[first_index][second_index]) # 显示 plt.show() # PS:注意坐标轴上的显示,就是classes # 如果数据正确的,对应关系显示错了就功亏一篑了 # 一个错误发生,想要说服别人就更难了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号