
Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库。整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因。
发现:
集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫法,如:数据本地化、计算本地化、任务本地化等。
自己简单理解:
假设集群有6个节点,来了一批数据共12条,数据被均匀的分布在了每个节点,也就是每个节点2条。现在要开始处理这些数据。
一种情况是:某数据由哪个节点处理被随机的分配,类似A节点存了数据1和数据2却可能被要求处理C节点的数据5和数据6,C节点的数据5和数据6就被备份到A节点,而A节点的数据又要备份到其他某一节点用于被处理。集群节点间存在大量数据移动,影响了速度。
另一种情况:某节点自身储存的数据就由自身来处理,比如A节点存储了数据1和数据2,那么数据1和数据2就由A节点来计算,C节点存储了数据5和数据6,那么数据5和数据6就由C节点来计算。这也就避免了数据的移动。
当然实际要比我描述的复杂得多,我的理解肯定也有不对的地方。
浏览器打开spark 8080端口master界面,图中红色箭头处如果显示各机器IP地址那就很有可能会造成移动数据的问题。
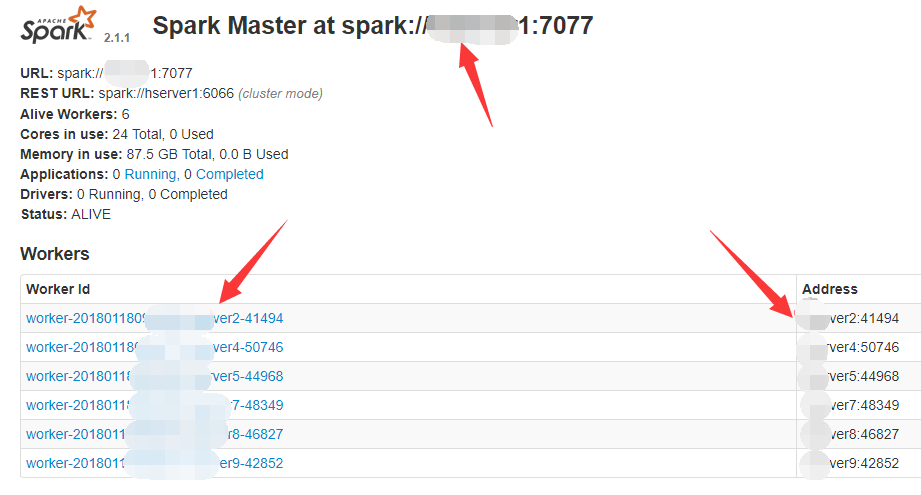
解决:
先停止spark集群,在master机器用 start-master.sh 启动,然后分别在每一台worker机器用 start-slave.sh -h 本机hostname spark://master机器hostname:7077 启动。
过程中可能遇到很多问题,多注意每台机器上的几个文件中的内容是否有问题:/etc/hosts, spark中conf文件夹中spark-env.sh和slaves

 浙公网安备 33010602011771号
浙公网安备 33010602011771号