

一次线上问题的解决
线上发现服务cpu使用达到98%,负载高达200多,64核心cpu,下面介绍解决过程:
1.top命令查出占用cpu高的进程pid
2.使用jstack -l pid >dump.txt 获取dump文件
3.使用top -H查询出消耗资源的线程号tid(十进制线程id),转换为16进制
4.cat dump.txt | grep -10 tid(16进制) 查询出该进程号上下10行,定位问题并解决问题
=====================================================
1.使用top命令
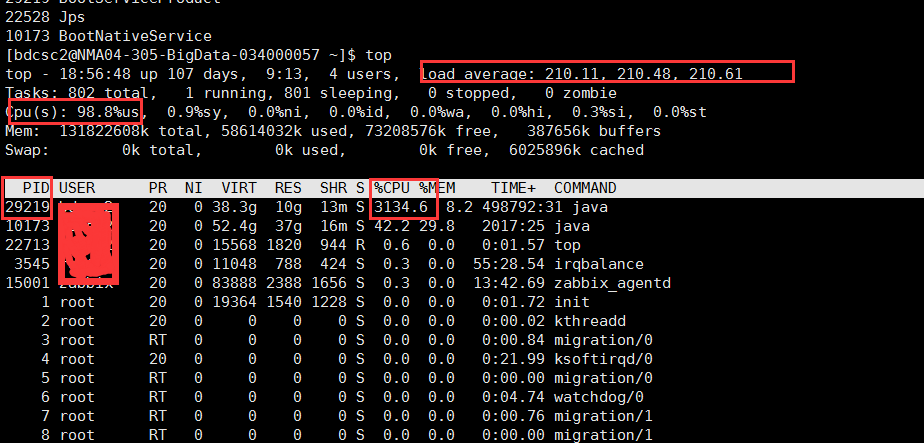
2.jstack -l pid >dump.txt 获取dump文件
3.使用top -H查询出消耗资源的线程号tid(十进制线程id),转换为16进制 ,10587转换成十六进制后为295B,转换成小写为295b
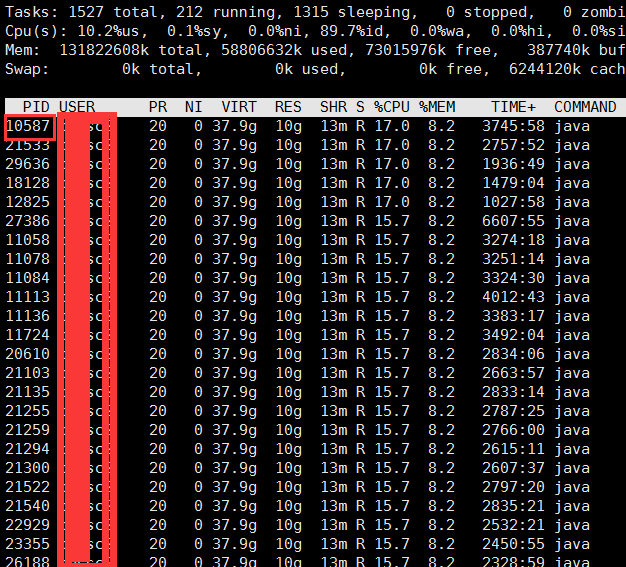
4.cat dump.txt | grep -10 tid(16进制) 查询出该进程号上下10行,定位问题并解决问题
cat dump.txt | grep -10 295b
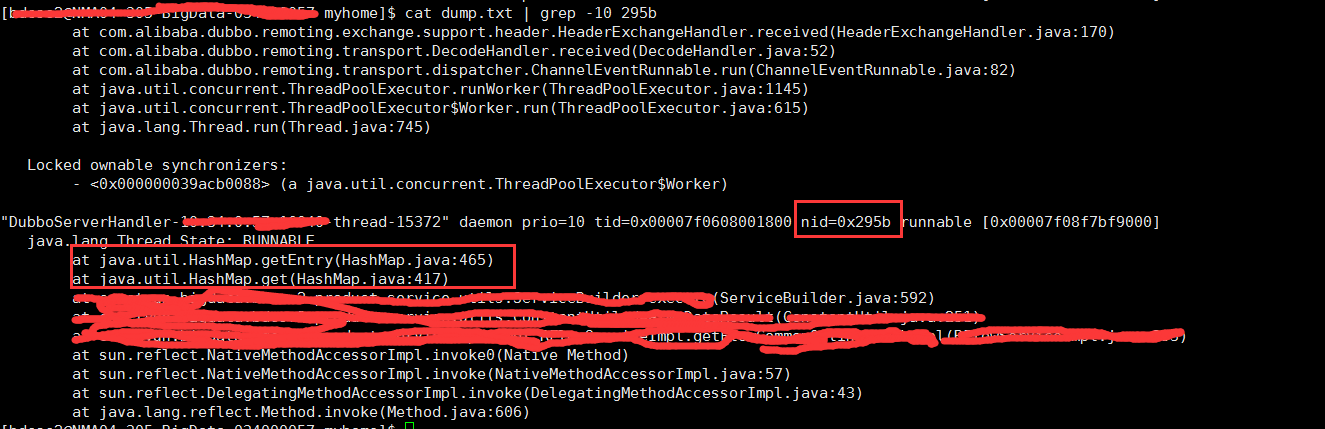
发现问题在hashMap的get方法,count发现有200多个的runnable状态在调用hashMap的get方法,经过查找ServiceBuilder的第592行发现在一个公共静态方法中使用了一个类全局变量的HashMap作为 共享变量被并发使用,第592行是get方法,经过查找发现在1.7的get方法中有e.next();方法造成cpu无限循环。于是把HashMap改成了ConcurrentHashMap.问题应该解决了,待上线验证。(注该问题不一定会100%发生)
另见(关于hashMap的循环bug):http://ifeve.com/hashmap-infinite-loop/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号