
sklearn学习随笔1
快速入门:
加载数据集
In [1]: from sklearn import datasets In [2]: iris = datasets.load_iris() In [3]: digits = datasets.load_digits() In [4]: print(digits.data) [[ 0. 0. 5. ..., 0. 0. 0.] [ 0. 0. 0. ..., 10. 0. 0.] [ 0. 0. 0. ..., 16. 9. 0.] ..., [ 0. 0. 1. ..., 6. 0. 0.] [ 0. 0. 2. ..., 12. 0. 0.] [ 0. 0. 10. ..., 12. 1. 0.]] In [5]: print (digits.target) [0 1 2 ..., 8 9 8]
In [6]: digits.images[1]
Out[6]:
array([[ 0., 0., 0., 12., 13., 5., 0., 0.],
[ 0., 0., 0., 11., 16., 9., 0., 0.],
[ 0., 0., 3., 15., 16., 6., 0., 0.],
[ 0., 7., 15., 16., 16., 2., 0., 0.],
[ 0., 0., 1., 16., 16., 3., 0., 0.],
[ 0., 0., 1., 16., 16., 6., 0., 0.],
[ 0., 0., 1., 16., 16., 6., 0., 0.],
[ 0., 0., 0., 11., 16., 10., 0., 0.]])
SVM小试牛刀:
In [9]: from sklearn import svm In [10]: clf = svm.SVC(gamma=0.001,C = 50) In [11]: clf.fit(digits.data[:-1],digits.target[:-1]) Out[11]: SVC(C=50, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) In [12]: clf.predict(digits.data[-1:]) Out[12]: array([8])
模型持久化:
通过python的内置的持久化模型pickle讲模型保存在scikit中
In [13]: from sklearn import svm In [14]: from sklearn import datasets In [15]: clf = svm.SVC() In [16]: iris = datasets.load_iris() In [17]: X,y = iris.data,iris.target In [18]: clf.fit(X,y) Out[18]: SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) In [19]: import pickle In [20]: s = pickle.dumps(clf) In [21]: clf2 = pickle.loads(s) In [22]: clf2.predict(X[0:1]) Out[22]: array([0]) In [23]: y[0] Out[23]: 0
pickle.dumps(clf)存储模型
pickle.loads()加载存储的模型
joblib替换pickle(joblib.dump&joblib.load)可能会更有意思,这对大数据更有效,但只能腌制到磁盘而不是字符串:
In [24]: from sklearn.externals import joblib
In [25]: joblib.dump(clf,'filename.pkl')
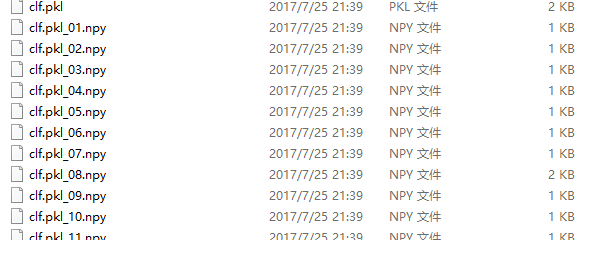
In [26]: joblib.dump(clf,'d:/clf.pkl')
Out[26]:
['d:/clf.pkl',
'd:/clf.pkl_01.npy',
'd:/clf.pkl_02.npy',
'd:/clf.pkl_03.npy',
'd:/clf.pkl_04.npy',
'd:/clf.pkl_05.npy',
'd:/clf.pkl_06.npy',
'd:/clf.pkl_07.npy',
'd:/clf.pkl_08.npy',
'd:/clf.pkl_09.npy',
'd:/clf.pkl_10.npy',
'd:/clf.pkl_11.npy']
In [27]: clf = joblib.load('d:\clf.pkl')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号