

java8-流-操作(Intermediate&Terminal&Short-circuiting)
三类:Intermediate、Terminal、Short-circuiting
Intermediate
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
Terminal
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Short-circuiting
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
一. map
转换大小写
ArrayList<String> wordList = Lists.newArrayList("a", "b", "c");
List<String> output = wordList
.stream()
.map(String::toUpperCase)
.collect(Collectors.toList());
System.out.println(output);
从List获取stream
这里传入的是一个CollectorImpl,就是一个Collector的实现,而stream的collect方法,就需要传入一个collector
构造的时候传入了Supplier、BiConsumer、BinaryOperator、characteristics
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Set<Characteristics> characteristics) {
this(supplier, accumulator, combiner, castingIdentity(), characteristics);
}
collect返回的结果是,最后会根据传入的Collector收集数据
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else {
container = evaluate(ReduceOps.makeRef(collector));
}
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
map创建了一个流,在opWrapSink方法中,调用的是mapper的apply方法去处理内R
这里只需要填写对stream中元素的映射方式,填写一个function就可以了
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
平方数
List<Integer> nums = Arrays.asList(1, 2, 3, 4);
List<Integer> squareNums = nums.stream()
.map(n -> n * n)
.collect(Collectors.toList());
flatMap负责一对多的映射
Stream<List<Integer>> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
Stream<Integer> outputStream = inputStream.flatMap((childList) -> childList.stream());
flatmap把Stream<List<Integer>>中的内容扁平化
flatMap传入的是一个function,function传入lambda表达式,内部会调用传入的function函数
public final <R> Stream<R> flatMap(Function<? super P_OUT, ? extends Stream<? extends R>> mapper) {
Objects.requireNonNull(mapper);
//stream无限的时候轮训,返回StatelessOp无状态操作
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT | StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
try (Stream<? extends R> result = mapper.apply(u)) {
// We can do better that this too; optimize for depth=0 case and just grab spliterator and forEach it
if (result != null)
result.sequential().forEach(downstream);
}
}
};
}
};
}
map和flatmap的区别
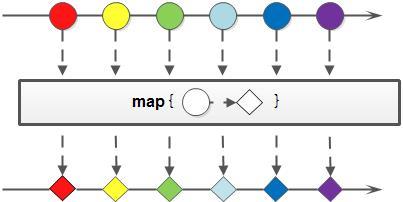
map
对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong和mapToDouble。这三个方法也比较好理解,比如mapToInt就是把原始Stream转换成一个新的Stream,这个新生成的Stream中的元素都是int类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗
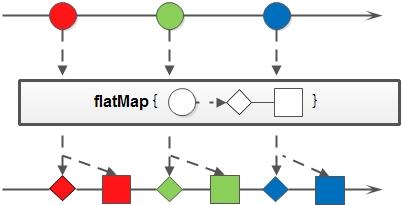
flatMap
和map类似,不同的是其每个元素转换得到的是Stream对象,会把子Stream中的元素压缩到父集合中;
二. filter
filter 对原始 Stream 进行某项测试,通过测试的元素被留下来生成一个新 Stream
留下偶数
Integer[] sixNums = {1, 2, 3, 4, 5, 6};
Integer[] evens =
Stream.of(sixNums).filter(n -> n%2 == 0).toArray(Integer[]::new);
把单词挑出来
同时可以看出,flatMap操作的是集合中的元素,只是能够更进一步的利用元素产生一个个的stream,再组合起来,组成更细粒度的stream
List<String> output = reader.lines().
flatMap(line -> Stream.of(line.split(REGEXP))).
filter(word -> word.length() > 0).
collect(Collectors.toList());
三. forEach
在Stream的每个元素上执行传入的表达式
// Java8的方法
roster.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.forEach(p -> System.out.println(p.getName()));
// java8之前的方法
for (Person p : roster) {
if (p.getGender() == Person.Sex.MALE) {
System.out.println(p.getName());
}
}
forEach是为Lambda设计的,代码更紧凑,如果需要并行,可以使用parallelStream().forEach()优化
java8把foreach并行化,只是元素的顺序无法保证,forEach是terminal操作,只能执行一次
peek
intermediate操作,也可以达到这个目的
peek 对每个元素执行操作,之后返回一个新的 Stream
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
forEach 不能修改自己包含的本地变量值,也不能用 break/return 之类的关键字提前结束循环
四. findFirst
termimal 兼 short-circuiting 操作,返回Stream的第一个元素或者空
其返回值类型为Optional,模仿 Scala的概念,作为一个容器可能包含某值,或者不包含,可以避免NullPointerException
Optional的两个例子
public void optional_test() {
String strA = " abcd ", strB = null;
print(strA);
print("");
print(strB);
System.out.println(getLength(strA));
System.out.println(getLength(""));
System.out.println(getLength(strB));
}
public static void print(String text) {
// Java 8
Optional.ofNullable(text).ifPresent(System.out::println);
// Pre-Java 8
if (text != null) {
System.out.println(text);
}
}
public static int getLength(String text) {
// Java 8
return Optional.ofNullable(text).map(String::length).orElse(-1);
};
Stream中的findAny、max/min、reduce等方法返回Optional
IntStream.average()返回OptionalDouble
五. reduce
把Stream元素组合起来,提供一个起始种子,按照运算规则,和前面 Stream 的第一个、第二个、第 n 个元素组合
字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce;
例如:Stream的sum就相当于
Integer sum = integers.reduce(0, (a, b) -> a+b);
Integer sum = integers.reduce(0, Integer::sum);
如果没有起始,会把stream的前两个元素组合起来,返回的是Optional
reduce例子
// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").
filter(x -> x.compareTo("Z") > 0).
reduce("", String::concat);
identity是传入的seed,BinaryOperator是具体的操作
public final P_OUT reduce(final P_OUT identity, final BinaryOperator<P_OUT> accumulator) {
return evaluate(ReduceOps.makeRef(identity, accumulator, accumulator));
}
然后执行ReduceOps的makeRef操作,最后返回的是一个TerminalOp这个终结操作
public static <T, U> TerminalOp<T, U>
makeRef(U seed, BiFunction<U, ? super T, U> reducer, BinaryOperator<U> combiner) {
Objects.requireNonNull(reducer);
Objects.requireNonNull(combiner);
class ReducingSink extends Box<U> implements AccumulatingSink<T, U, ReducingSink> {
@Override
public void begin(long size) {
state = seed;
}
@Override
public void accept(T t) {
state = reducer.apply(state, t);
}
@Override
public void combine(ReducingSink other) {
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, U, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
};
}
evaluate的具体操作如下
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
根据是否是并行操作,决定具体的evaluate函数,如果串行使用terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags())
第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。
这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素返回的是 Optional
六. limit/skip
limit返回前n个元素,skip扔掉前n个元素
public void testLimitAndSkip() {
List<Person> persons = new ArrayList();
for (int i = 1; i <= 10000; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<String> personList2 = persons.stream().
map(Person::getName).limit(10).skip(3).collect(Collectors.toList());
System.out.println(personList2);
}
private class Person {
public int no;
private String name;
public Person (int no, String name) {
this.no = no;
this.name = name;
}
public String getName() {
System.out.println(name);
return name;
}
}
在 short-circuiting 操作 limit 和 skip 的作用下,管道中 map 操作指定的 getName() 方法的执行次数为 limit 所限定的 10 次,而最终返回结果在跳过前 3 个元素后只有后面 7 个返回;
但是放在stream排序后,limit/skip无法达到short-circuiting的目的,和sorted这个intermediate操作有关,此时系统并不知道Stream排序后次序,sorted中的操作看上去就像完全没有被 limit 或者 skip 一样
limit 和 skip 对 sorted 后的运行次数无影响
public void sorted_limit_skip() {
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList2 = persons.stream().sorted((p1, p2) ->
p1.getName().compareTo(p2.getName())).limit(2).collect(Collectors.toList());
System.out.println(personList2);
}
虽然追后返回值是2,但是运行次数没有减少
并行操作,如果元素有序limit的代价比较大,返回对象必须是前 n 个也有一样次序的元素,取消元素之间的次序或者不要用parallel Stream
七. sorted
对Stream排序通过sorted,可以首先对stream进行 map、filter、limit、skip 甚至 distinct 等操作,减少元素数量之后再排序,这能够明显缩短时间
排序前进行 limit 和 skip
List<Integer> transactionsIds = transactions.parallelStream().
filter(t -> t.getType() == Transaction.GROCERY).
sorted(comparing(Transaction::getValue).reversed()).
map(Transaction::getId).
collect(toList());
这种排序是有局限的,要求排序后不要取值;
八. min/max/distinct
min 和 max 的功能也可以通过对 Stream 元素先排序,再 findFirst 来实现,但是性能会更好 O(n)
而排序成本是 O(n log n)
找出最长一行的长度
BufferedReader br = new BufferedReader(new FileReader("c:\\SUService.log"));
int longest = br
.lines()
.mapToInt(String::length)
.max()
.getAsInt();
br.close();
System.out.println(longest);
找出不重复的单词
List<String> words = br
.lines()
.flatMap(line -> Stream
.of(line.split(" ")))
.filter(word -> word.length() > 0)
.map(String::toLowerCase)
.distinct()
.sorted()
.collect(Collectors.toList());
br.close();
System.out.println(words);
九. Match
Stream 有三个 match 方法,从语义上说:
- allMatch:Stream 中全部元素符合传入的 predicate,返回 true
- anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
- noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
只要判断出即可,不会便利所有的元素
List<Person> persons = new ArrayList();
persons.add(new Person(1, "name" + 1, 10));
persons.add(new Person(2, "name" + 2, 21));
persons.add(new Person(3, "name" + 3, 34));
persons.add(new Person(4, "name" + 4, 6));
persons.add(new Person(5, "name" + 5, 55));
boolean isAllAdult = persons.stream().
allMatch(p -> p.getAge() > 18);
System.out.println("All are adult? " + isAllAdult);
boolean isThereAnyChild = persons.stream().anyMatch(p -> p.getAge() < 12);
System.out.println("Any child? " + isThereAnyChild);
十. 自己生成流
Stream.generate
通过实现 Supplier 接口,你可以自己来控制流的生成;
情形:随机数、常量stream、前后元素间维持着某种状态信息的 Stream
Stream.generate()生成,无序,无限,需要使用limit限制大小
生成 10 个随机整数
public void stream_random() {
Random seed = new Random();
Supplier<Integer> random = seed::nextInt;
Stream.generate(random).limit(10).forEach(System.out::println);
//Another way
IntStream.generate(() -> (int) (System.nanoTime() % 100)).
limit(10).forEach(System.out::println);
}
自实现 Supplier
private class PersonSupplier implements Supplier<Person> {
private int index = 0;
private Random random = new Random();
@Override
public Person get() {
return new Person(index++, "StormTestUser" + index, random.nextInt(100));
}
}
public void stream_random() {
Stream.generate(new PersonSupplier())
.limit(10)
.forEach(p -> System.out.println(p.getName() + ", " + p.getAge()));
}
Stream.iterate
和reduce很想,接受一个种子值,和一个 UnaryOperator;
然后种子值成为 Stream 的第一个元素,f(seed) 为第二个,f(f(seed)) 第三个,以此类推。
生成等差数列
Stream.iterate(0, n -> n + 3).limit(10). forEach(x -> System.out.print(x + " "));.
iterate也必须用limit限制数量
十一. 用 Collectors 来进行 reduction 操作
Collectors主要作用是辅助进行各类有用的 reduction 操作;
例如转变输出为 Collection,把 Stream 元素进行归组;
groupingBy/partitioningBy
按照年龄归组,相同年龄的放在同一个list中
public void stream_groupby() {
Map<Integer, List<Person>> personGroups = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.groupingBy(Person::getAge));
Iterator it = personGroups.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, List<Person>> persons = (Map.Entry) it.next();
System.out.println("Age " + persons.getKey() + " = " + persons.getValue().size());
}
}
按照未成年人和成年人归组
Map<Boolean, List<Person>> children = Stream
.generate(new PersonSupplier())
.limit(100)
.collect(Collectors.partitioningBy(p -> p.getAge() < 18));
System.out.println("Children number: " + children.get(true).size());
System.out.println("Adult number: " + children.get(false).size());
十二. 总结
Stream 的特性可以归纳为:
- 不是数据结构
- 它没有内部存储,它只是用操作管道从 source(数据结构、数组、generator function、IO channel)抓取数据。
- 它也绝不修改自己所封装的底层数据结构的数据。例如 Stream 的 filter 操作会产生一个不包含被过滤元素的新 Stream,而不是从 source 删除那些元素。
- 所有 Stream 的操作必须以 lambda 表达式为参数
- 不支持索引访问
- 你可以请求第一个元素,但无法请求第二个,第三个,或最后一个。不过请参阅下一项。
- 很容易生成数组或者 List
- 惰性化
- 很多 Stream 操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始。
- Intermediate 操作永远是惰性化的。
- 并行能力
- 当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的。
- 可以是无限的
- 集合有固定大小,Stream 则不必。limit(n) 和 findFirst() 这类的 short-circuiting 操作可以对无限的 Stream 进行运算并很快完成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号