
数据采集技术第三次作业
作业①:
题目:指定一个网站爬取这个网站中的所有的所有图片,例如中国气象网分别使用单线程和多线程的方式爬取。(限定爬取图片为学号后3位) 输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
完整代码:码云作业1单线程
1.解题过程:
1.1 解析网页:
url = "http://www.weather.com.cn/" # 中国气象网
doc = urllib.request.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(doc, "html.parser")1.2 分析网页,获取网站中的各个href链接

故对应的正则表达式可为:
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", str(lis))1.3 获取图片地址:

由此可见图片地址在img标签的src中
方法1---单线程:
for url in link_list:
if number<139:
print('-'*25+'第'+str(a+1)+'页'+'-'*25)
a+=1#记录爬取的页数
images = soup.select("img") # 获取图像标签
for image in images:
if number<139:#记录爬取的图片数量
try:
url = image["src"]
if (url[len(url) - 4:] == ".jpg"): # 去掉png属性的图片
number = number + 1
urllib.request.urlretrieve(url, 'E:\爬取图片\\' + str(number) + '.jpg')
#下载图片
print("downloaded " + str(number))
except Exception as err:
print(err)
else:
break
else:
print("爬取", a, "页,并成功保存了", number, "张图片。")
break输出结果(可看出是顺序输出):

方法2---多线程:
引入多线程的模块:
for url in link_list:
if number<139:
print('-'*25+'第'+str(a+1)+'页'+'-'*25) # 翻页记录
a+=1
imageSpider(url)
for t in threads: #多线程
t.join()
else:
print("爬取", a, "页,并成功保存了", number, "张图片。")
break执行多线程:
for image in images:
if (number < 139): # 对爬取数量进行规定
try:
url=image["src"]
if (url[len(url) - 4:] == ".jpg"):# 去掉png属性的图片
number = number + 1
# target:要执行的线程函数
# args:为target的函数提供参数的一个元组或者列表
T = threading.Thread(target=download, args=(url, number))
T.setDaemon(False)#非守护线程
T.start()# 调用T.start()开始线程,开始下载每一个图片
threads.append(T) #把线程加入到线程数组
except Exception as err:
print(err)下载图片函数:
def download(url,number):
try:
urllib.request.urlretrieve(url,'E:\爬取图片\\'+str(number)+'.jpg')
#下载图片
print("downloaded "+str(number))
except Exception as err:
print(err)输出结果(可看出是非顺序输出):

2.心得体会:
此实验我更加熟悉了如何获取href标签内的网页地址:
re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", str(lis))两种方法相比的话单线程更简单直观但比较慢,多线程速度快但存在考虑进程执行顺序的问题。
作业②:
题目:使用scrapy框架复现作业①。
输出信息:同作业①。
完整代码:码云作业2
1.解题过程:
1.1 items.py部分:
class DemoItem(scrapy.Item):
# 爬取图片地址需要的字段
url = scrapy.Field()1.2 run.py部分:
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())1.3 setting.py部分:
ITEM_PIPELINES = {
'demo.pipelines.DemoPipeline': 300,
}1.4 mySpider.py部分:
1.4.1解析网址并将网站内的href标签内的网址存在列表中:
url = 'http://www.weather.com.cn/'
doc = urllib.request.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(doc, "html.parser") #解析网址
lis = soup.select('div[class="page"]')
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", str(lis))
#href标签内的网址1.4.2开始函数:
def start_requests(self):
yield scrapy.Request(url=MySpider.url, callback=self.parse)1.4.3 获取//img/@src标签内的图片地址,同时爬取一页后进行翻页处理。
def parse(self, response):
global number
global count
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)#解析网页
lis = selector.xpath("//img/@src")#查找图片的地址
for url in lis.extract():
if number<139: #爬取数量限制
if url[len(url) - 4:] == ".jpg": # 去掉png属性的图片
item = DemoItem()
item["url"] = url if url else ""
number+=1
yield item
if number<139:#进行翻页操作
count+=1
yield scrapy.Request(url=MySpider.link_list[count], callback=self.parse)
else:
print("爬取", count, "页,并成功保存了", number, "张图片。")
except Exception as err:
print(err)1.5 pipelines.py部分:
class DemoPipeline(object):
number=0 #爬取图片数量标记
def process_item(self, item, spider):
DemoPipeline.number += 1 #记录数量
url = item["url"] # 获得url地址
try:
urllib.request.urlretrieve(url, 'E:\爬取图片\\' + str(DemoPipeline.number) + '.jpg') # 下载图片
print("downloaded " + str(DemoPipeline.number))
except Exception as err:
print(err)
return item输出结果:
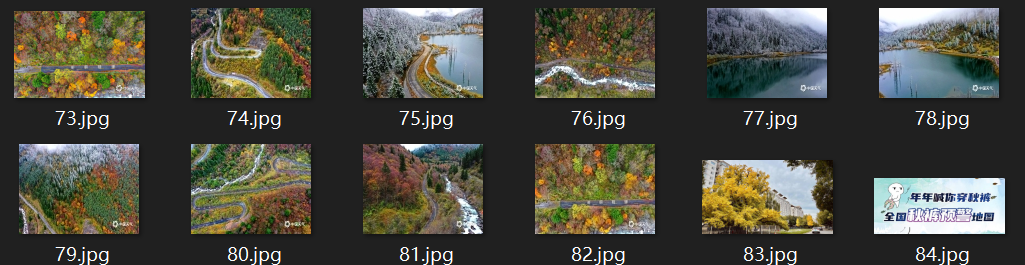
2.心得体会:
每次运用scrapy编写程序,都会进一步理解scrapy是如何把数据爬取与数据存储分开处理,异步执行的。 mySpider每爬取到一个数据项目item,就yield推送给pipelines.py 。
作业③:
题目:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
候选网站: 豆瓣电影网
输出信息:
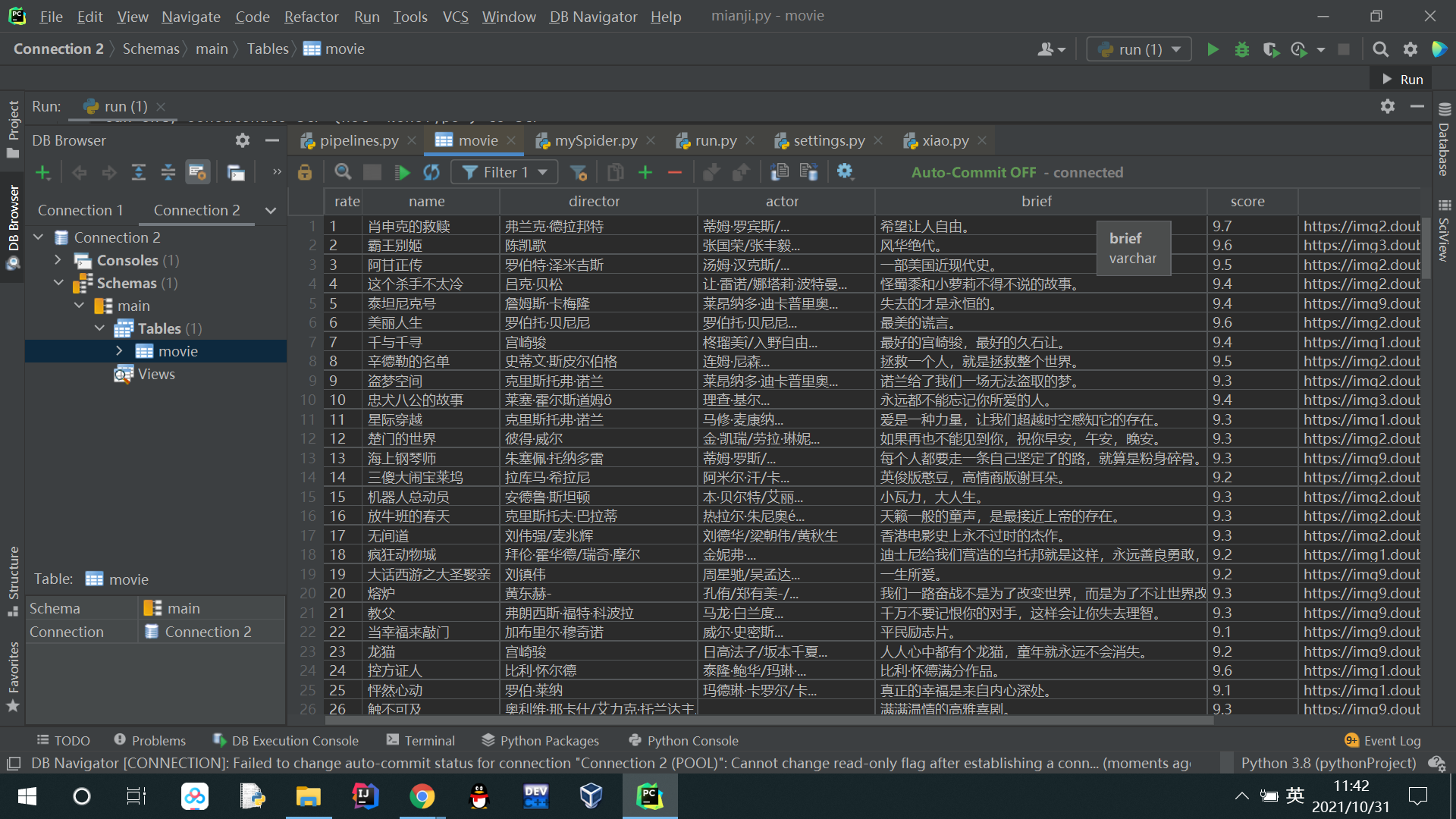
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
| 1 | 肖申克的救赎 |
弗兰克·德拉邦特 |
蒂姆·罗宾斯 |
希望让人自由 |
9.7 |
./imgs/xsk.jpg |
| 2 | …… | …… | …… | …… | …… | …… |
完整代码:码云作业3
1. 解题过程:
1.1 items.py部分:
class DemoItem(scrapy.Item):# 爬取图片地址需要的字段
rate = scrapy.Field() #排名
name = scrapy.Field() # 电影名称
director = scrapy.Field() # 导演
actor = scrapy.Field() # 演员
brief = scrapy.Field() # 简介
score = scrapy.Field() # 评分
picture = scrapy.Field() # 封面1.2 run.py部分:
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())1.3 mySpider.py部分:
1.3.1开始信息:
class MySpider(scrapy.Spider):
name = "mySpider"
url = 'https://movie.douban.com/top250/'
def start_requests(self):
yield scrapy.Request(url=MySpider.url, callback=self.parse)1.3.2解析网址:
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)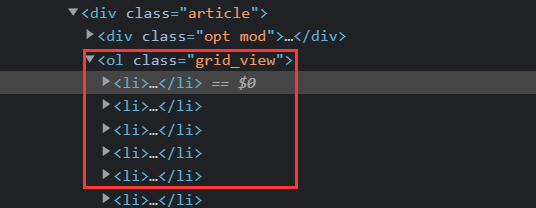
lis = selector.xpath("//ol[@class='grid_view']//li")1.3.3根据网页信息编写xpath代码:
for li in lis:
rate = li.xpath(".//div[@class='pic']/em/text()").extract_first() # 序号
name = li.xpath(".//div[@class='info']//a/span[position()=1]/text()").extract_first() # 电影名称
tor =li.xpath(".//div[@class='bd']/p/text()").extract_first() # 导演和演员
brief = li.xpath(".//div[@class='bd']/p[@class='quote']/span/text()").extract_first() #简介
score = li.xpath(".//div[@class='star']/span[@class='rating_num']/text()").extract_first() #电影评分
picture = li.xpath(".//div[@class='pic']/a/img/@src").extract_first() #电影封面在这里我都用到了.extract_first(),这样的好处时如果出现空值,则会按照None处理,比如这种情况:

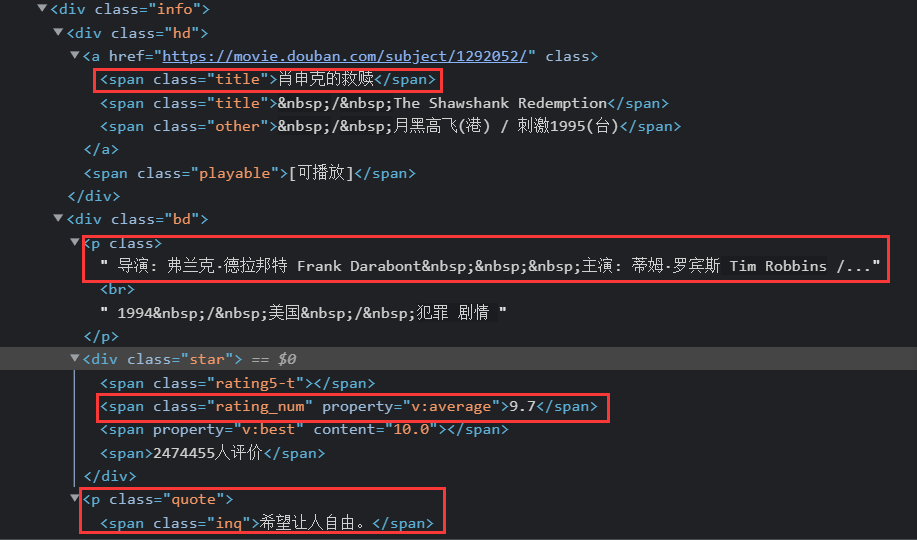
需要注意的是导演和演员混在一起了,需要进行特殊处理:
![]()
需要进行的处理包括:
去除 
分割导演和主演
去掉他们的英文名从而留下中文名
主演空缺的情况处理
people = tor.strip().replace(u"\xa0", u"").replace(" ", "").split("主演:")
#去除 
#分割导演和主演
if len(people) == 2:
item["director"] = re.compile("[a-z|A-Z]").sub("", people[0]).replace("导演:", "")
#去掉他们的英文名,留下中文名
item["actor"] = re.compile("[a-z|A-Z]").sub("", people[1])
else:
#主演空缺的情况处理
item["director"] = re.compile("[a-z|A-Z]").sub("", people[0]).replace("导演:", "")
item["actor"] = ""翻页操作:

link = selector.xpath("//div[@class='paginator']/span[@class='next']/a/@href").extract_first()
yield scrapy.Request(MySpider.url+link, callback=self.parse, dont_filter=False)#翻取下一页1.4 setting.py部分:
ITEM_PIPELINES = {
'demo.pipelines.DemoPipeline': 300,
}#打开pipelines
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.16 Safari/537.36',
}#设置请求头
AUTOTHROTTLE_ENABLED = True1.5 pipelines.py部分:
1.5.1创建数据库,写入数据库,关闭数据库:
#打开数据库的方法
def openDB(self):
self.con = sqlite3.connect("movie.db")
self.cursor = self.con.cursor() # 创建一个游标对象
try:
self.cursor.execute(" create table movie (rate varchar(5),name varchar(16),director varchar(20),actor varchar(20),brief varchar(20),score varchar(5),picture varchar(16) )" )# 创建格式
#创建表
except:
self.cursor.execute("delete from movie")#插入数据的方法
def insert(self, rate, name, director, actor, brief, score, picture):
try:
self.cursor.execute("insert into movie (rate, name, director, actor, brief, score, picture) "
"values (?,?,?,?,?,?,?)",
(rate, name, director, actor, brief, score, picture))
#插入表
except Exception as err:
print(err)#关闭数据库的方法
def closeDB(self):
self.con.commit()
self.con.close()#关闭数据库连接1.5.2open_spider函数在开始执行项目时会执行一次:
class DemoPipeline(object):
def open_spider(self, spider):
print("开始爬取")
self.db = movieDB()
self.db.openDB()1.5.3插入数据操作并下载图片到指定文件夹:
def process_item(self, item, spider):
self.db.insert(item["rate"],item["name"], item["director"],item["actor"],item["brief"],item["score"],item["picture"])
urllib.request.urlretrieve(item["picture"], 'E:\爬取图片\\' + str(item["rate"]) + '.jpg')
# 下载图片
return item1.5.4close_spider类在结束项目时会执行一次,断开数据库链接。
def close_spider(self, spider):
self.db.closeDB()
print("爬取结束")输出结果:
2.心得体会:
此实验中我学习了如何处理爬取数据,这其中运用到了re库,以及replace和split。 同时巩固了构建数据库的相关知识点。
遇到的问题:
(1)运行时只能爬取第一页的数据,然后就出现了list index out of range的问题。
原因:出现了主演空缺的情况,需要进行处理。
解决方法:.split("主演:")后对其数量进行分情况讨论。
(2)本应该爬取250部电影的信息,但经常在中间停滞了。
原因:我怀疑是数据采集太快了,毕竟scrapy是异步进行的。
解决方法:在setting中添加AUTOTHROTTLE_ENABLED = True。作用是根据 Scrapy 及爬取网站的负载自动限制爬取速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号