
数据采集技术第一次作业
作业①:
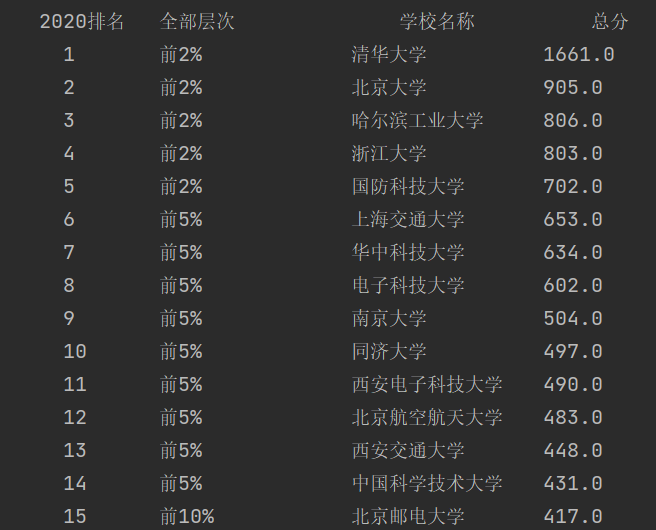
题目:要求用urllib和re库方法定向爬取给定网址2020中国最好学科排名的数据。输出信息如下:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2 | …… | …… | …… |
1.解题过程:
1.1:获取网页
url="https://www.shanghairanking.cn/rankings/bcsr/2020/0812"
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req)# 发送请求
soup=data.read().decode('utf-8')# 解析网页1.2根据网页结点信息构造正则表达式
rank=[]
level=[]
school=[]
score=[]
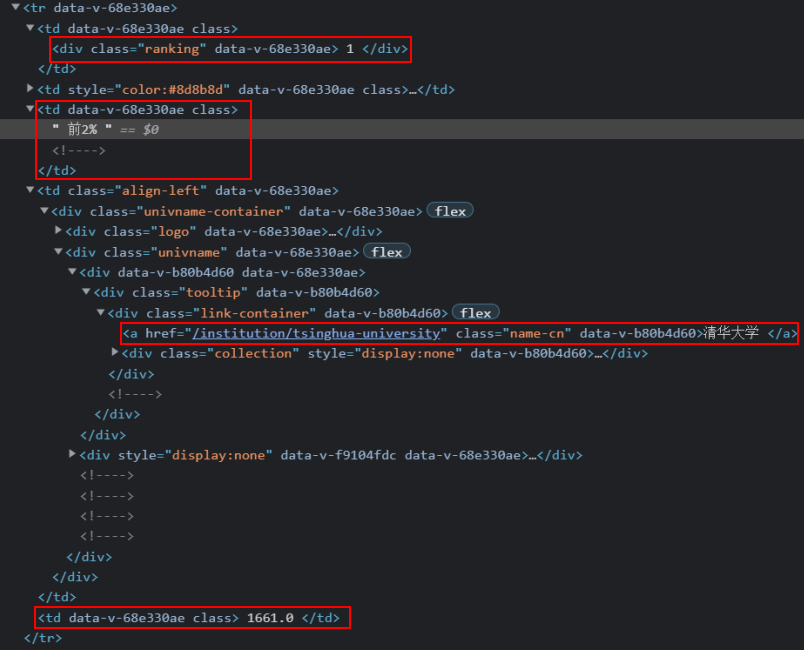
for items in re.findall(r'<tr data-v-68e330ae>.*?</tr>', soup, re.S|re.M):
for a in re.findall(r'<div class="ranking".*?>(.*?)</div>',items,re.S|re.M):
rank.append(int(a)) #记录排名
for b in re.findall(r'<td data-v-68e330ae.*?>(.*?)</td>',items,re.S|re.M):
for k in re.findall(r'(.*?)<!---->',b,re.S):
level.append(k.strip()) #记录层次
for k in re.findall(r'\d+\.\d',b,re.S):
score.append(k.strip()) #记录总分
for c in re.findall(r'<a .*?name-cn.*?>(.*?)</a>', items, re.S|re.M):
school.append(c)# 记录学校1.3输出代码
tplt = "{0:^10}\t{1:{4}<10}\t{2:<10}\t{3:<10}"
print(tplt.format("2020排名", "全部层次", "学校名称", "总分", chr(12288)))
for i in range(len(rank)):
print(tplt.format(rank[i],level[i],school[i],score[i],chr(12288)))
#中英文混排时采用chr(12288)1.4输出结果
完整代码:
2.心得体会
记录层次和总分时因为两者都是在<td data-v-68e330ae class></td>中,一时间没有想好怎么区分,浪费了比较多的时间,也说明我的正则表达式掌握的还不够熟练。
作业②:
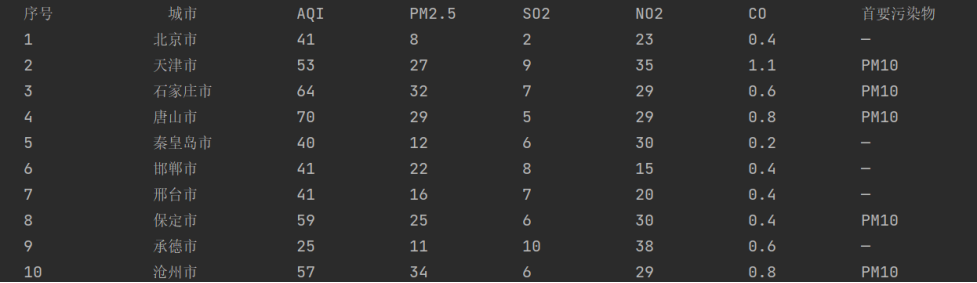
题目:用requests和Beautiful Soup库方法设计爬取城市AQI实时报
| 序号 | 城市 | AQI | PM2.5 | SO2 | NO2 | CO | 首要污染物 |
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | —— |
| 2 | …… | …… | …… | …… | …… | …… | …… |
1.解题过程
1.1获取网页
url="https://datacenter.mee.gov.cn/aqiweb2/"
r = requests.get(url) # requests库方法请求
r.raise_for_status()
r.encoding = r.apparent_encoding
soup=BeautifulSoup(r.text,"html.parser")# 利用BeautifulSoup方法1.2设置输出格式
tplt = "{0:^8}\t{1:{8}^10}\t{2:<10}\t{3:<10}\t{4:<10}\t{5:<10}\t{6:<10}\t{7:<10}"
print(tplt.format("序号", "城市", "AQI", "PM2.5", "SO2","NO2","CO","首要污染物", chr(12288)))1.3根据网页结点信息构造爬取代码

lis = soup.select("tbody tr")
i=1 #记录序号
for tr in lis:
rate = i
city = tr.select('td')[0].text.strip() # 记录城市
AQI = tr.select('td')[1].text.strip() # 记录AQI
PM25 = tr.select('td')[2].text.strip() # 记录PM2.5
SO2 = tr.select('td')[4].text.strip() # 记录SO2
NO2 = tr.select('td')[5].text.strip() # 记录NO2
CO = tr.select('td')[6].text.strip() # 记录CO
WU = tr.select('td')[8].text.strip() # 记录首要污染物
print(tplt.format(rate, city, AQI, PM25, SO2, NO2, CO, WU, chr(12288)))
i=i+11.4输出结果
完整代码:
2.心得体会
此题运用BeautifulSoup方法比较简单。
作业③:
题目:使用urllib和requests和re爬取一个给定网页福州大学新闻网爬取该网站下的所有图片,将自选网页内的所有jpg文件保存在一个文件夹中。
1.requests方法解题过程
1.1获取网页
def Html(url):
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
r = requests.get(url, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
url = "http://news.fzu.edu.cn/"
1.2根据网页信息爬取图片并下载
for items in re.findall(r'<img src=".*?>',r.text,re.I|re.S|re.M):
for item in re.findall(r'(?<=src=\")(.+?).jpg(?=\")', items, re.I|re.S|re.M):
value = item.split('/')[-1] #截取出图片名称
path='E:\爬取图片\\'+value+'.jpg'
value=requests.get(url+item+'.jpg')
with open(path,'wb') as f:
f.write(value.content) #下载图片完整代码:
2.urllib方法解题过程
2.1获取网页
def Html(url):
header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
req = urllib.request.Request(url, headers=header)
data = urllib.request.urlopen(req)# 发送请求
soup = data.read().decode('utf-8')#解析网页
url = "http://news.fzu.edu.cn"
2.2根据网页信息爬取图片并下载
for items in re.findall(r'<img src=".*?>',soup,re.I|re.S|re.M):
for item in re.findall(r'(?<=src=\")(.+?).jpg(?=\")', items, re.I|re.S|re.M):
value = item.split('/')[-1] #截取出图片名称
urllib.request.urlretrieve(url+item+'.jpg', 'E:\爬取图片\\' + value+'.jpg')
#采用urllib.request.urlretrieve下载图片完整代码:
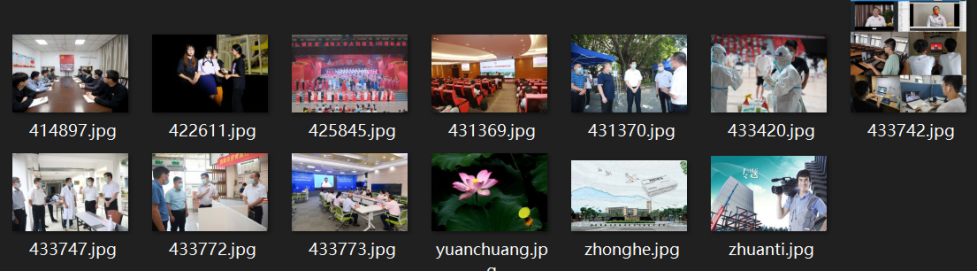
下载结果如下:
3.心得体会
运行以下代码发现部分图片无法打开。
urllib.request.urlretrieve(url+item, 'E:\爬取图片\\' + value+'.jpg')改成下面代码成功解决。
urllib.request.urlretrieve(url+item+'.jpg', 'E:\爬取图片\\' + value+'.jpg')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号