

系统监控
什么是监控?
监控就是盯着、监视状态。
监控系统监控什么?
监控一些我们关注的系统运行的重要指标:CPU、内存、磁盘和网络。
监控CPU使用率脚本
思路:
第一步获取CPU的运行状态,从多个状态中取出想要的那一个(CPU的使用率)
第二步判断 CPU的使用率 超过100% 发送报警
获取CPU状态
即时跟踪进程信息:top命令
数据处理工具:awk命令
检测系统资源变化:vmstat命令
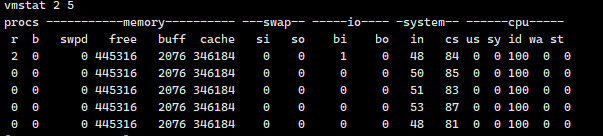
vmstat 1 5 |awk 'NR==5{print $(NF-2)}'
判断,拿到值的结果进行判断
cpu_free=$(vmstat 1 5 |awk 'NR==5{print $(NF-2)}')
if [ ${cpu_free} -eq 0 ];then echo "报警信息:cpu剩余率为0" >> /tmp/warn.log fi
写进脚本文件并给予执行权限
vi /scripts/check.cpu.sh
chmod +x /scripts/check.cpu.sh
在本地测试
bash /scripts/check.cpu.sh cat /tmp/warn.log
优化脚本并编辑计划任务

监控系统负载脚本
获取系统负载的值
load_average=$(uptime |awk '{print $(NF-2)}' |cut -d, -f1)
判断,平均负载预期值根据CPU的核数进行判断,双核的CPU满载是2,翻个2倍作为阈值。
动态获取CPU的个数:


[root@localhost ~]# cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 151 model name : 12th Gen Intel(R) Core(TM) i5-12400F stepping : 2 microcode : 0x2e cpu MHz : 2496.000 cache size : 18432 KB physical id : 0 siblings : 1 core id : 0 cpu cores : 1 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 32 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 arat umip pku ospke gfni vaes vpclmulqdq movdiri movdir64b md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities bogomips : 4992.00 clflush size : 64 cache_alignment : 64 address sizes : 45 bits physical, 48 bits virtual power management:
grep 'processor' /proc/cpuinfo |wc -l
阈值:
load_average_limit=$(($(grep 'processor' /proc/cpuinfo |wc -l) * 2))
if [ load_average -ge load_average_limit ];then echo "主机:$`hostname` 系统超负载" >> /tmp/warn.log fi
监控指标的优化
监控的时候瞬时的值不能代表系统的健康状态。可以多次取值然后去平均值,也可以隔一段时间再次取值。
CPU资源---->可压缩资源
内存、磁盘---->不可压缩资源
监控内存脚本
需求:内存使用率超过90%报警

分别取到真正可用的内存的值和总的内存的值,做计算后得到内存可利用率赋值给一个变量
available=`free |awk '/Mem/{print $NF}'` total=`free |awk '/Mem/{print $2}'` mem_percent=`echo "scale=2;$available / $total" |bc |cut -d. -f2`
写入脚本进行判断:
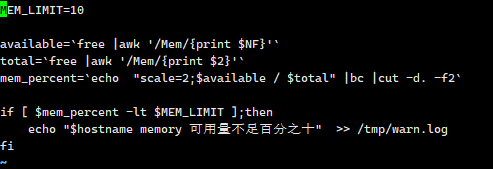
加执行权限,并在本地测试。
[root@localhost ~]# chmod +x /scripts/check_mem.sh [root@localhost ~]# bash /scripts/check_mem.sh
监控磁盘脚本
需求:磁盘使用率超过90%则报警。
用df命令统计根分区。
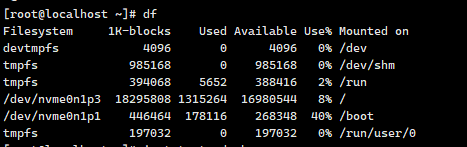
取值:
disk_use=$(df |awk '/sda3/{print$(NF-1)}' |cut -d'%' -f1)
写入脚本进行判断:

结合计划任务实现邮件报警
mail.py "系统报警" "主机localhost 系统负载超10倍" "13951479732@163.com"
发邮箱或者微信。
张仁国

 浙公网安备 33010602011771号
浙公网安备 33010602011771号