

文件高级处理下
一、文件查找命令:
find命令就是帮你找某个文件夹下面去找有没有你要找的文件。
按照文件名查找:
find /etc -name "ifcfg-ens33"
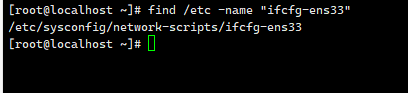

find /etc -name "ifcfg-*" *代表的意思是所有ifcfg开头的都找一下。


按照大小查找:
find /etc -size +3M 大于3M的
find /etc -size 3M 什么都不写默认就是等于3兆
find /etc -size -3M 小于3兆
找到之后进行操作:
-ls意思是进行浏览
find /etc -size -3M -ls
-print 打印
-delete 删除
-exec 对找到的结果进行某种操作。比如把找到的文件全部拷贝到一个文件夹下面去,-a的意思是拷贝源文件的元数据+文件内容,默认情况下cp命令只会拷贝文件的内容,一个文件包括两部分数据,一部分数据是元数据,另一部分是数据本身。
find /etc -size -3M -exec cp -ra
找到的结果用花括号代替。
find /etc -size -3M -exec cp -ra {} /test/ \;
除了-cp还可以-mv
find /aaa -size -3M -exec mv -ra {} /test/ \;
超过10兆的都删掉
find /aaa -size +10M -exec rm -rf {} \;
指定查找的深度:

find /etc -maxdepth 5 最多查找5层 /etc/a/b/c/d/e
-maxdepth通常都跟其它搭配,大于3兆的并且名字是log结尾的
find /etc -maxdepth 5 -size +3M -name "*.log"
这三个选项之间这样写是省略了-a,-a是并且and的意思,不写默认就是and的意思。
find /etc -maxdepth 5 -a -size +3M -a -name "*.log"
-a与-o
-a是并且,必须同时满足。
-o是或者,满足一个就可以。
按照时间查找:参照的是当前的时间。
通常用在我们定期的要去做些备份。
修改时间超过3天的删掉
find /etc -mtime +3 -name "*bak*" -exec rm-rf {} \;
修改时间等于3天
find /etc -mtime 3
修改时间3天以内
find /etc -mtime -3
按照文件类型查找
如果是普通文件就写f,不要写-f
find /etc -type f -name "*.log" -size +3M -exec rm -rf {} \;
xargs把不支持从管道取出来的东西来做处理的那些命令让他们都能支持。
find /test -name "*.txt" | xargs tar czf ../222.tar.gz
tar xf ../222.tar.gz -C /test1/
上传下载
wget 文件网址
wget -O 本地路径 远程包链接地址 -O是把下载的图片保存到本地的一个路径(自己命名)
先下载安装wget
yum install wget -y
wget https://pics1.baidu.com/feed/d833c895d143ad4b160a7650a077a4a1a50f06f9.jpeg@f_auto?token=e7da643d52381a542c309594ad212787
下载的时候我们可能不用http协议,我们可能用的是nginx这个就是https协议,就是在http协议上加了ssl的一个协议,更加的安全。
如果遇到ssl问题,有两种方案解决第一种尝试加上 --no-check-certificate
wget --no-check-certificate https://nginx.org/download/nginx-1.22-1.tar.gz
另外一种是尝试改用http协议下载
wget http://xxxx
curl
curl是系统自带不需要自己下载安装。必须-o指定下载的路径,如果遇到https的问题在前面在-k,或者改用HTTP协议。
curl -o /xxx/1.png http://www.xxx.com/1.png
curl -k -o /xxx/1.png https://www.xxx.com/1.png
curl还有个额外的用法:把网上的脚本下载到本地后立即执行。
一下载就会把脚本内容在屏幕上打印展现出来。-s是静默输出,把本该打印展现的不打印了,把结果扔到管道里交给bash执行。
curl -s http://xxx/test/a.sh | bash
curl --help |less


做一个服务端,并且在服务器上放置好一个脚本文件 先确定一下服务器能不能上网 ping www.baidu.com 安装一个NGINX软件包 apt-get install nginx -y 如果是centos系统就用yum安装 yum install nginx -y 安装之后跑到固定的文件夹下 cd /var/www/html/ 再建一个子目录 mkdir test 建一个脚本文件 vi test/a.sh 在这个脚本文件里写脚本然后esc :wq systemctl start nginx systemctl status nginx
安装软件包
centos
yum install lrzsz -y
ubuntu
apt-get install lrzsz -y
rz:上传,用图形界面进行操作。
sz:下载
二、文件管理的输入输出重定向
文件描述符:进程但凡打开一个文件,操作系统都会为打开的文件分配一个非负整数(大于等于0的整数)的编号,这个编号就称之为文件描述符也称之为文件句柄。
整体关系:进程操作的是打开的文件,其实打开的文件在操作系统里体现的是文件描述符,操作系统内核去操控硬盘。
进程(打开文件)----------->文件描述符------------->内核--------------->硬盘
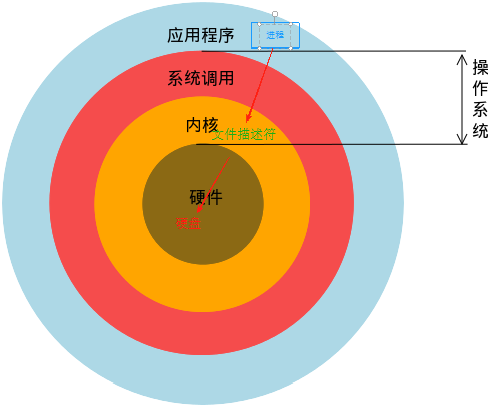
一个进程起来之后,我们要用他的时候无非就是与之交互,交互就是:输入+输出
输入输出背后对应的机制是什么?
在Linux系统一切皆文件:
对于进程来讲:
输入操作------>某个打开的文件-------->文件描述符
输出操作------>某个打开的文件-------->文件描述符
0号文件描述符:代表标准输入
1号文件描述符:代表标准正确输出
2号文件描述符:代表标准错入输出
重定向符号:
> 代表写入,覆盖
>> 代表追加
把2号文件描述符的标准输出的错入信息写到tmp文件夹下的a.txt文件中去:
[root@localhost ~]# dfasdfas 2>/tmp/a.txt [root@localhost ~]# cat /tmp/a.txt -bash: dfasdfas: command not found
把1号文件描述符的标准正确输出信息写到tmp文件夹下的b.txt文件中去:
如果是正确输出的话ip a 1的1可以省略掉。
[root@localhost ~]# ip a 1>/tmp/b.txt [root@localhost ~]# [root@localhost ~]# cat /tmp/b.txt 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:0c:29:81:26:68 brd ff:ff:ff:ff:ff:ff altname enp3s0 inet 192.168.1.56/24 brd 192.168.1.255 scope global dynamic noprefixroute ens160 valid_lft 6324sec preferred_lft 6324sec inet6 2409:8a20:7f4d:b550:20c:29ff:fe81:2668/64 scope global dynamic noprefixroute valid_lft 258814sec preferred_lft 172414sec inet6 fe80::20c:29ff:fe81:2668/64 scope link noprefixroute valid_lft forever preferred_lft forever
命令 1>/tmp/a.txt 2>/tmp/b.txt
命令 1>/dev/null 2>/dev/null
命令 & >/dev/null
标准输入:
需求:把一大堆内容放到一个文件里面去。
cat >> /tmp/c.txt << "EOF" 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:0c:29:81:26:68 brd ff:ff:ff:ff:ff:ff altname enp3s0 inet 192.168.1.56/24 brd 192.168.1.255 scope global dynamic noprefixroute ens160 valid_lft 6324sec preferred_lft 6324sec inet6 2409:8a20:7f4d:b550:20c:29ff:fe81:2668/64 scope global dynamic noprefixroute valid_lft 258814sec preferred_lft 172414sec inet6 fe80::20c:29ff:fe81:2668/64 scope link noprefixroute valid_lft forever preferred_lft forever EOF
sort命令,排序。
unip命令,去重。
去重并且显示重复的次数。
cat file.txt | sort |uniq -c
cat > file.txt << EOF EOF
访问前10的IP地址是谁?
首先要取出文件的ip地址
awk '{print$1}' access.log
再归类到一起去
awk '{print$1}' access.log |sort
去重-c显示重复出现的次数,-n是以数值进行排序,默认是升序从小到大 -r是反过来 -rn就是降序开始排。
awk '{print$1}' access.log |sort |uniq -c |sort -rn
取前10
awk '{print$1}' access.log |sort |uniq -c |sort -rn |head -10
cut命令
cut -d 指定分割符
head -3 /etc/passwd | cut -d':' -f1,2,3

wc命令
-l统计文件的长度
wc -1 /etc/passwd
cat /etc/passwd | wc -l
-w统计文件中单词的个数
打包压缩
打包:把多个文件放到一起,得到一个打包文件。
压缩:对打包的文件进行空间上的缩减。
c要创建打包文件,f指定打包文件名(a.tar),/date是要打包的目录,v是展示详细信息,会把整个大打包过程给展示出来。
tar cvf a.tar /data/
gzip压缩,会发现加了gz后缀,并且内容精简了很多。
gzip a.tar
打包压缩合一步:
z就是调用gzip压缩算法,我们自己要压缩文件加上gz结尾
tar -cvzf a.tar.gz /data/
使用bzip2,还得需要安装一下软件包。
tar -cvjf a.tar.bz2 /data/
解包不区分算法
x代表解包的意思,f代表要指定的文件名,-C /data指定到解压到哪里去的路径
tar xvf a.tar.gz -C /data/
让我们的压缩包不带被打爆目录
1、首先先切到被打包目录下
cd /data/
2、进行打包压缩
../ 上一级 ./*当前目录下的*,只打包当前目录下的文件不带目录了
tar cvzf ../a.tar.gz ./*
获取某一天的某一刻时间 date '+%Y-%m-/%d %H:%M:%S'
date '+%Y_%m_/%d_%H_%M_%S'
把这个命令的结果当做另外一条命令的参数,就在这个命令上加翻译号 `date '+%Y_%m_/%d_%H_%M_%S' `
tar cvzf `date '+%Y_%m_/%d_%H_%M_%S' `.tar.gz /data
zip是通用的,安装 yum install zip -y
选项,如果之根文件可以不写
-r,针对目录
-q,静默输出
打包压缩:
zip -q aaa.zip /data/1/txt /data/2.txt /data/3.png /data/4.txt
zip -rq bbb.zip /data/
解压缩
unzip bbb.zip -d /nnn/
大文件切分与合并
以10兆为单位切分成多份
split -b 10M a.tar.gz
组合
cat
cat xa* >b.tar.gz
md5sum计算两个文件的结果如果一样,就代表两个文件的内容一模一样。
md5sum a.tar.gz
md5sum b.tar.gz

 浙公网安备 33010602011771号
浙公网安备 33010602011771号