

一条走了索引还执行慢的sql
一、现象
1、客户反应报表出不来
服务台同事接到客户反馈“ 某个报表查询结果为空”。与研发同事确认,该报表设置为60秒超时。
2、awr中显示执行70多秒
与运维确认该报表对应的SQL,生成出故障时间段的awr报表。在awr报告中显示执行时长为71.54S
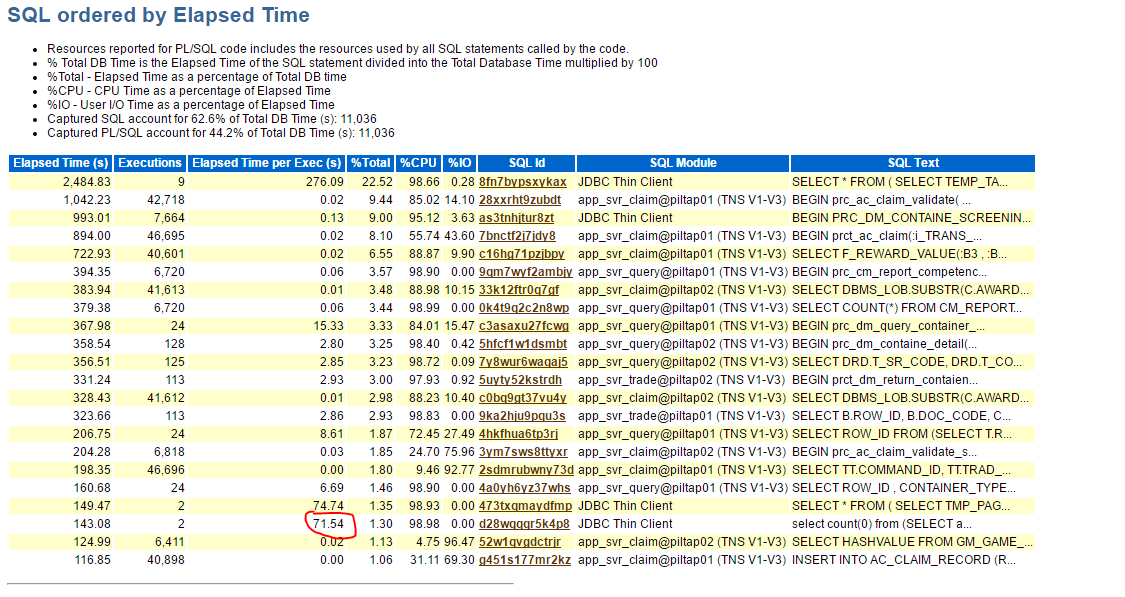
sql执行超了60秒,该报表设置60秒超时。符合客户反馈报表为空的现象。至此,故障现象阶段处理完成。
二、分析原因过程
1、分析执行计划
1)慢在哪儿
(1)通过sqlplus 以ilps用户登录主机
(2)设置环境参数
set linesize 600
set pagesize 0
set long 999999
(3) 确认sql_id
确认了sql之后,从AWR报告中可以直接看出sql_id为:d28wqqqr5k4p8
(4)查看执行计划
Select * from table(dbms_xplan.display_awr(‘d28wqqqr5k4p8’));
得到的执行计划如下:
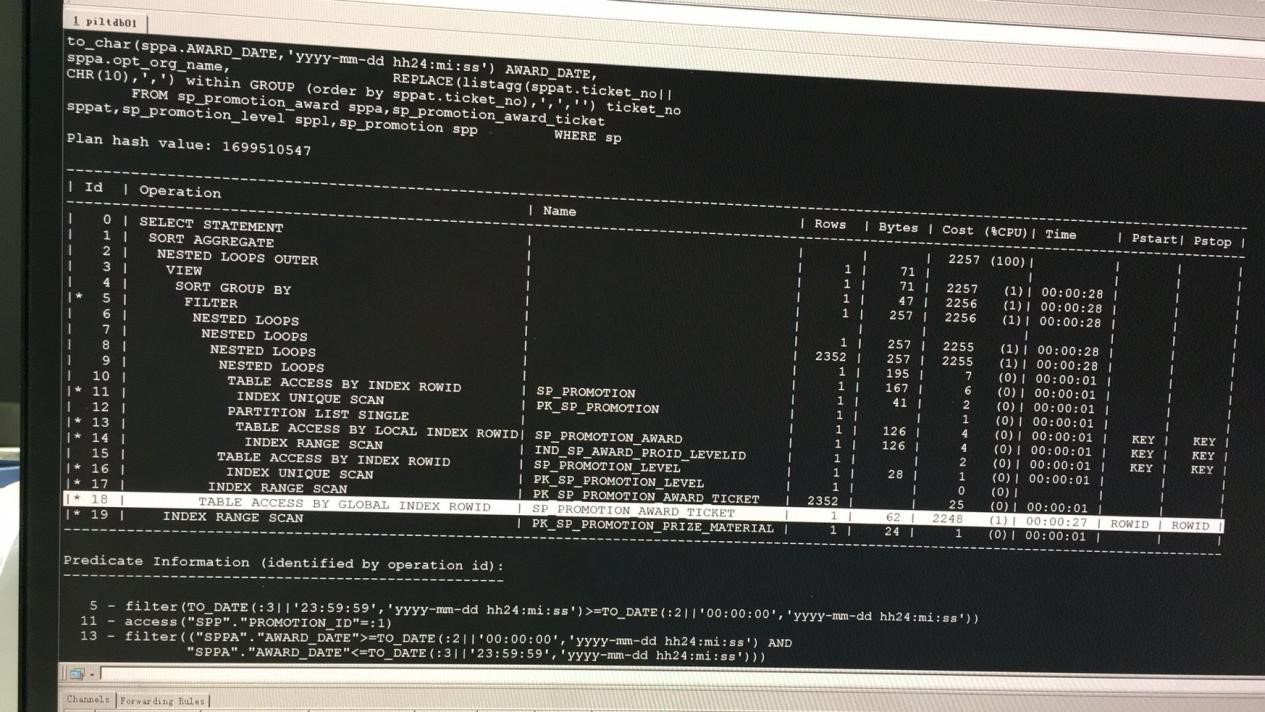
无论是从cost还是Time中,消耗最多的在地18行,对表sp_promotion_award_ticket的操作上消耗了90%以上的资源。
2)为什么慢
(1)分析表结构
sp_promotion_award_ticket表为分区表,根据省编码分区。
该表有一主键,执行计划的第17行就是走的该表主键对应的全局唯一性索引,并且是组合索引,索引列为:PROMOTION_ID, PROMOTION_LEVEL_ID, TICKET_NO。
(2) 走索引了为什么还会慢
分析一下索引与sql中where条件中的情况。
首先,索引的选择性肯定为1,因为是唯一性索引。所以索引本身的选择性没有问题。
其次,从sql的where条件来看,用到的where条件列有3个,即:TRANS_ID,claim_org_code,promotion_id。也就是说该sql不能用到这个唯一索引的全部列,只能用到索引的第一列:promotion_id。
由此,promotion_id这一列值的选择性,直接影响该sql使用这个唯一性索引的效率。
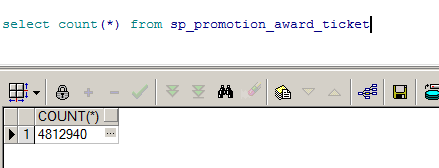
关键一点:我们来看一下这一列的选择性如何:
表中的记录有48万条。
Promotion_id却只有370条。
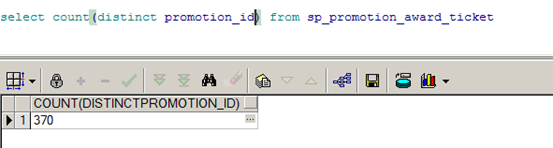
也就是说,每一条promotion_id对应的记录为:4812940/370=13万。选择性太低,这就是sql即使走了索引,也并没有提高效率的原因。
2、解决过程
1)查看sql中sp_promotion_award_ticket表在where条件中的使用到列的选择性
从sql中看,where条件中用到sp_promotion_award_ticket的列有3个,即:TRANS_ID,claim_org_code,promotion_id,这3个列对应的记录数如下:
|
列名 |
TRANS_ID,claim_org_code |
TRANS_ID |
claim_org_code |
promotion_id |
|
唯一记录数 |
4813146 |
4602359 |
26695 |
370 |
|
选择性: |
1.000 |
0.956 |
0.006 |
0.000 |
其中,选择性为对应列的唯一记录数÷表的全记录数。比如:claim_org_code列的选择性为:select count(distinct claim_org_code) from sp_promotion_award_ticket ÷ select count(*) from sp_promotion_award_ticket的值
由上图可见,TRANS_ID,claim_org_code两列的组合索引,选择性为1,如果新增这一索引,会极大提高sql的效率
2)分区表的优势没有使用
Sql中查询的是某个省中的信息,而且sp_promotion_award_ticket表中正好根据省分区。遗憾的是sql的where条件中并没有针对该表进行省条件的过滤。
如果需要利用分区表的优势的话,需要在where条件中增加sp_promotion_award_ticket表对省份的过滤
三、总结
1、索引的选择性问题
索引的选择性影响索引的执行效率。组合索引中使用了到索引列的选择性,同样 影响索引的效率。
2、前置索引的重要性
sp_promotion_award_ticket表的主键看,就算用到了全部的主键,索引的效率也并不是最好的。因为选择性最强的列不是最前面,
3、分区表的使用
如果想使用分区表的分区,必须在sql的where条件中明确根据分区键来使用,否则不起作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号