Node爬虫 爬博客园搜索
博客园右边有一个“找找看”的索引窗口,我们输入关键词,可以查到几万篇的相关的博客,这里用Node的爬虫来抓取给定关键词的查询的特定内容,实现翻页功能,抓取文章链接,作者,发布日期等信息。
Node适合高并发IO操作的程序,用来写爬虫速度最快了。这里我们把爬到的数据存储到数据库中。
前奏:
1.cheerio模块 ,一个类似jQuery的选择器模块,分析HTML利器。
2.request模块,让http请求变的更加简单
3.mysql模块,node连接mysql的模块,可参考:http://www.runoob.com/nodejs/nodejs-mysql.html。
4.数据库部分:
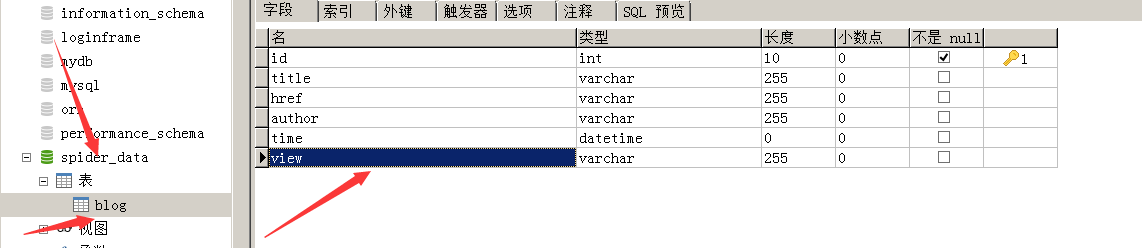
分析:
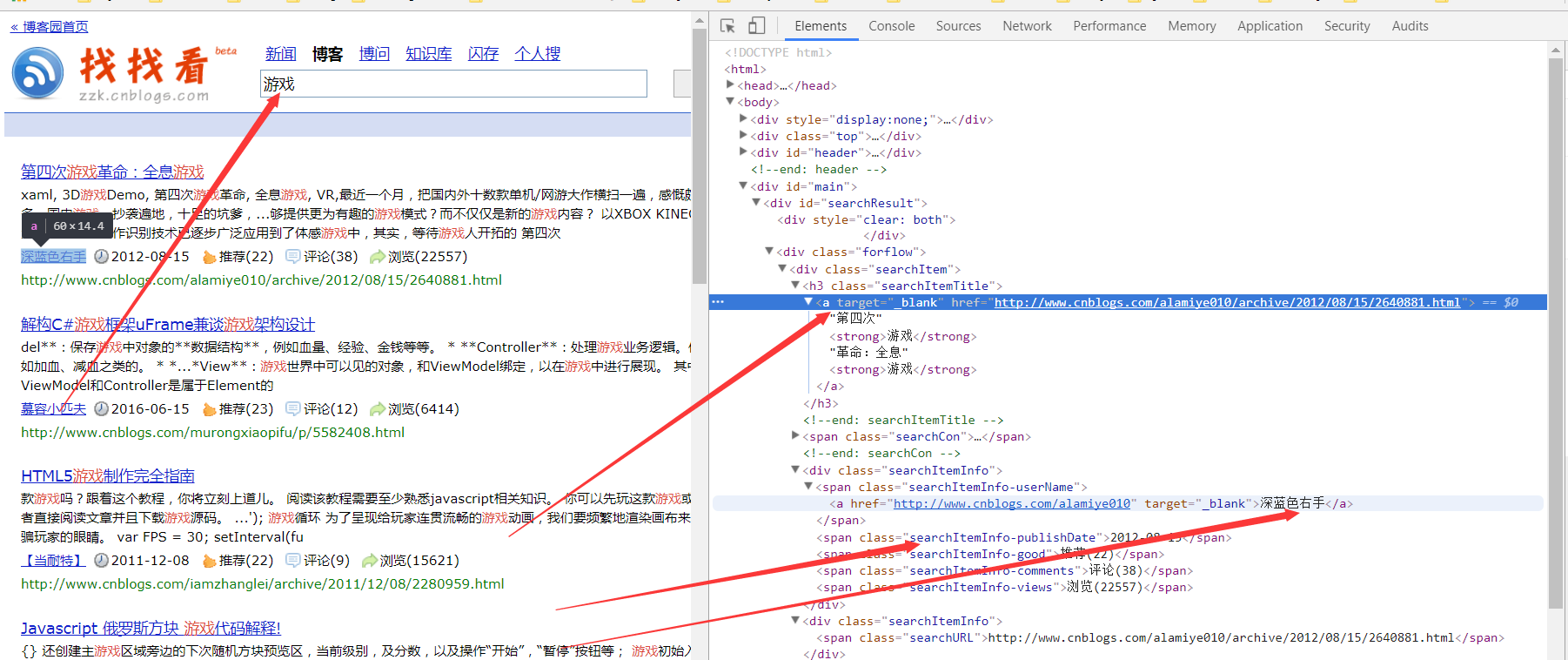
结构已经比较清晰
注意的是:
 这里的URL地址栏明文显示的结构,中文是显示出现了,但是实际URL内容是经过编码了,复制地址栏内容,粘贴过来,我们发现http://zzk.cnblogs.com/s/blogpost?Keywords=%E6%B8%B8%E6%88%8F,游戏其实被编码成了%E6%B8%B8%E6%88%8F,我们这里:
这里的URL地址栏明文显示的结构,中文是显示出现了,但是实际URL内容是经过编码了,复制地址栏内容,粘贴过来,我们发现http://zzk.cnblogs.com/s/blogpost?Keywords=%E6%B8%B8%E6%88%8F,游戏其实被编码成了%E6%B8%B8%E6%88%8F,我们这里:
var url = 'http://zzk.cnblogs.com/s/blogpost?Keywords=' + key + '&pageindex=' + page;如果key是中文,是会抓取不到任何数据,用JS函数url = encodeURI(url);转换一下就好。
翻页部分:
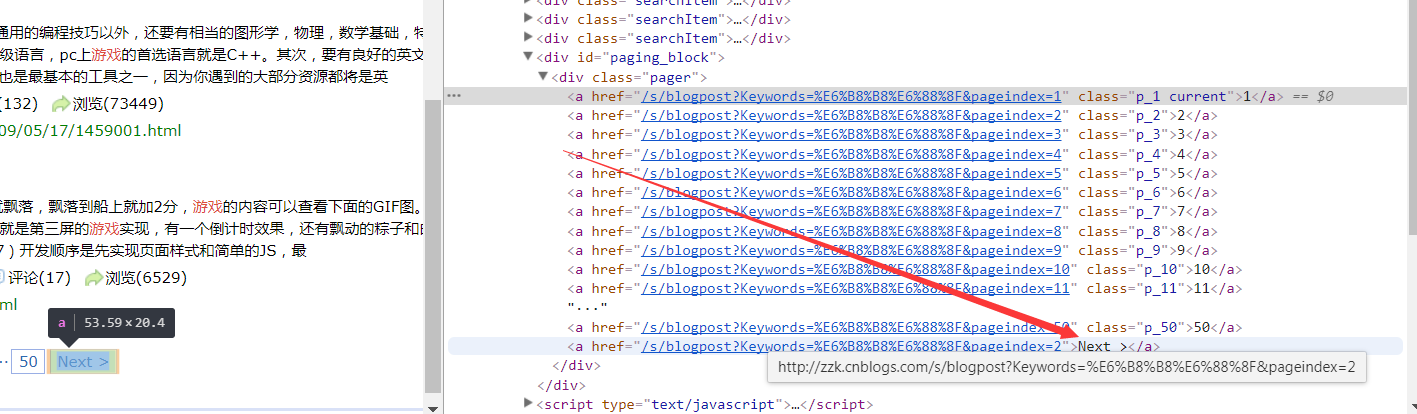
用"pageindex="出现的位置加上本身长度即得到页数
page = nextUrl.slice(nextUrl.indexOf('pageindex=') + 10);
indexof是返回子串在母串的第一个位置,没有则-1,区分大小写,slice也是从start取到end,注意下标1就是1开始,不是0
参考方法:http://www.w3school.com.cn/jsref/jsref_indexOf.asp
http://www.w3school.com.cn/jsref/jsref_slice_array.asp
代码:
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'spider_data'
});
db.connect();
function fetchData(key, page) {
var url = 'http://zzk.cnblogs.com/s/blogpost?Keywords=' + key + '&pageindex=' + page;
//用JS的全局对象函数,作为URI编码,不然中文,空格等抓取不到
url = encodeURI(url);
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//解析HTML代码
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('~~~~~~~~~~~~~~~~~~~~~~~ 输出开始 ~~~~~~~~~~~~~~~~~~~~~~~');
console.log(info);
console.log('~~~~~~~~~~~~~~~~~~~~~~~ 输出结束 ~~~~~~~~~~~~~~~~~~~~~~~');
//保存数据
db.query('insert into blog set ?', info, function(err, result) {
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
//下一页
var nextA = $('.pager a').last(),
nextUrl = '';
if ($(nextA).text().indexOf('Next') != -1) {
nextUrl = nextA.attr('href');
page = nextUrl.slice(nextUrl.indexOf('pageindex=') + 10);//"pageindex="出现的位置加上本身长度得到页数
setTimeout(function() {
fetchData(key, page);
}, 2000);
} else {
db.end();
console.log('结束,爬取完所有数据');
}
});
}
fetchData('游戏开发', 1);
结果:


我们可以随意换关键词,清空这个数据表。
改进:
速度太多,可能会被封IP,我们在后续可以用async 模块控制,async是一个流程控制工具包,提供了直接而强大的异步功能,进而在爬取页面时控制并发数。
用eventproxy 带来一种事件式编程的变化,如果你是要抓取多个源的数据,由于你根本不知道这些异步操作到底谁先完成,那么每次当抓取成功的时候,就需要判断一下count === n。当值为真时,使用另一个函数继续完成操作。而 eventproxy 就起到了这个计数器的作用,它来帮你管理到底这些异步操作是否完成,完成之后,它会自动调用你提供的处理函数,并将抓取到的数据当参数传过来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号