

优化Kubernetes集群DNS性能
CoreDNS是Kubernetes集群中负责DNS解析的组件,能够支持解析集群内部自定义服务域名和集群外部域名。CoreDNS具备丰富的插件集,在集群层面支持自建DNS、自定义hosts、CNAME、rewrite等需求。Kubernetes集群中默认部署形态在DNS QPS较高场景下,可能会出现解析压力,导致部分查询失败。本文介绍如何优化集群DNS性能。
背景信息
有关CoreDNS的更多信息,请参见CoreDNS。
1、合理调整集群CoreDNS副本数
调整CoreDNS副本数与集群节点数到合适比率有助于提升集群服务发现的性能,该比值推荐为1:8,即一个CoreDNS Pod支撑8个集群节点。
- 当集群节点无需大规模扩缩容时,执行以下命令调整目标副本数到目标值。
kubectl scale --replicas={target} deployment/coredns -n kube-system说明 将目标副本数{target}设置成目标值。 - 集群节点需要大规模扩缩容时,推荐部署以下YAML模板,使用集群水平伸缩器cluster-proportional-autoscaler动态调整副本数量。不建议使用针对QPS、CPU或MEM指标的水平伸缩器,实测效果较差。
apiVersion: apps/v1 kind: Deployment metadata: name: dns-autoscaler namespace: kube-system labels: k8s-app: dns-autoscaler spec: selector: matchLabels: k8s-app: dns-autoscaler template: metadata: labels: k8s-app: dns-autoscaler spec: serviceAccountName: admin containers: - name: autoscaler image: registry.cn-hangzhou.aliyuncs.com/ringtail/cluster-proportional-autoscaler-amd64:v1.3.0 resources: requests: cpu: "200m" memory: "150Mi" command: - /cluster-proportional-autoscaler - --namespace=kube-system - --configmap=dns-autoscaler - --target=Deployment/coredns - --default-params={"linear":{"coresPerReplica":64,"nodesPerReplica":8,"min":2,"max":100,"preventSinglePointFailure":true}} - --logtostderr=true - --v=2说明 上述使用线程伸缩策略中,CoreDNS副本数的计算公式为replicas = max (ceil (cores × 1/coresPerReplica), ceil (nodes × 1/nodesPerReplica) ),且CoreDNS副本数受到max,min限制。线程伸缩策略参数如下。
{ "coresPerReplica": 64, "nodesPerReplica": 8, "min": 2, "max": 100, "preventSinglePointFailure": true }
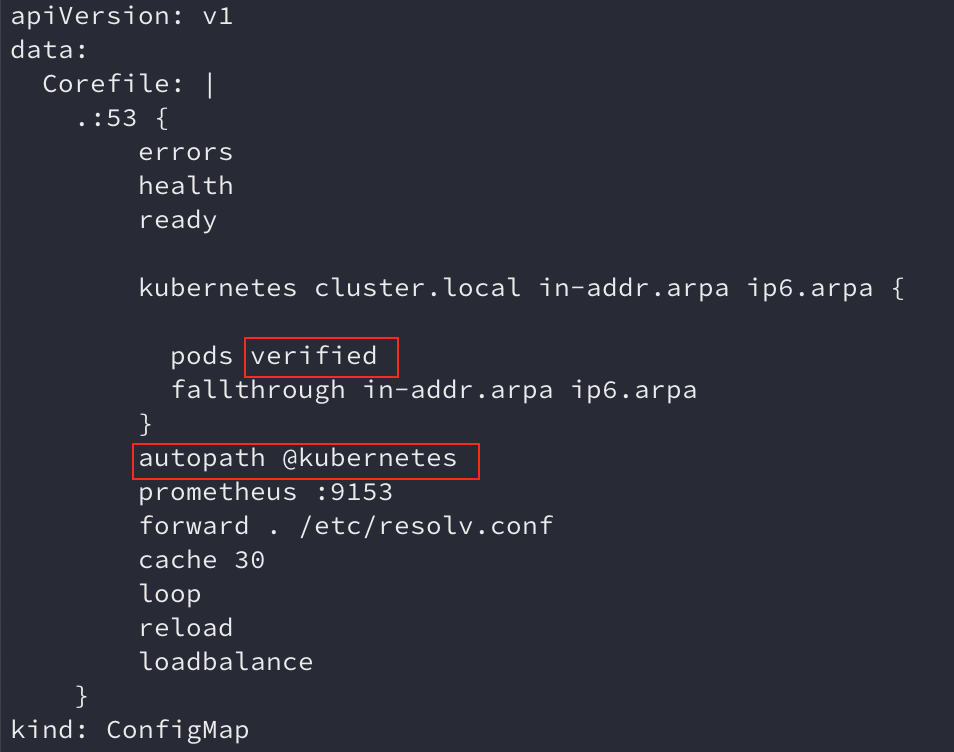
2、使用Autopath插件
- Default : 有人说 Default 的方式,是使用宿主机的方式,这种说法并不准确。这种方式,其实是,让 kubelet 来决定使用何种 DNS 策略。而 kubelet 默认的方式,就是使用宿主机的 /etc/resolv.conf(可能这就是有人说使用宿主机的DNS策略的方式吧),但是,kubelet 是可以灵活来配置使用什么文件来进行DNS策略的,我们完全可以使用 kubelet 的参数:–resolv-conf=/etc/resolv.conf来决定你的DNS解析文件地址。
-
ClusterFirst:这种方式,表示 POD 内的 DNS 使用集群中配置的 DNS 服务,简单来说,就是使用 Kubernetes 中 kubedns 或 coredns 服务进行域名解析。如果解析不成功,才会使用宿主机的 DNS 配置进行解析。目前,在ClusterFirst模式下,2次(1次IPv4,1次IPv6)集群外部域名查询产生8次(4次IPv4,4次IPv6)查询请求。例如,解析www.aliyun.com域名,会先分别携带三个集群主域名后缀,产生六次无效查询请求,这样会导致集群DNS QPS放大三倍,影响性能。
2020-06-04T20:46:35.643+08:00 [INFO] 172.20.0.100:54153 - 63230 "AAAA IN www.aliyun.com.kube-system.svc.cluster.local. udp 62 false 512" NXDOMAIN qr,aa,rd 155 0.000282418s 2020-06-04T20:46:35.644+08:00 [INFO] 172.20.0.100:54153 - 62219 "A IN www.aliyun.com.kube-system.svc.cluster.local. udp 62 false 512" NXDOMAIN qr,aa,rd 155 0.000387552s 2020-06-04T20:46:35.644+08:00 [INFO] 172.20.0.100:33409 - 11389 "AAAA IN www.aliyun.com.svc.cluster.local. udp 50 false 512" NXDOMAIN qr,aa,rd 143 0.000264026s 2020-06-04T20:46:35.644+08:00 [INFO] 172.20.0.100:33409 - 10963 "A IN www.aliyun.com.svc.cluster.local. udp 50 false 512" NXDOMAIN qr,aa,rd 143 0.000334383s 2020-06-04T20:46:35.645+08:00 [INFO] 172.20.0.100:57153 - 2741 "AAAA IN www.aliyun.com.cluster.local. udp 46 false 512" NXDOMAIN qr,aa,rd 139 0.000200375s 2020-06-04T20:46:35.645+08:00 [INFO] 172.20.0.100:57153 - 2435 "A IN www.aliyun.com.cluster.local. udp 46 false 512" NXDOMAIN qr,aa,rd 139 0.000329507s 2020-06-04T20:46:35.646+08:00 [INFO] 172.20.0.100:48284 - 31225 "A IN www.aliyun.com. udp 32 false 512" NOERROR qr,aa,rd,ra 476 0.00070823s 2020-06-04T20:46:35.646+08:00 [INFO] 172.20.0.100:48284 - 31851 "AAAA IN www.aliyun.com. udp 32 false 512" NOERROR qr,aa,rd,ra 498 0.000925332s
- ClusterFirstWithHostNetwork:在某些场景下,我们的 POD 是用 HOST 模式启动的(HOST模式,是共享宿主机网络的),一旦用 HOST 模式,表示这个 POD 中的所有容器,都要使用宿主机的 /etc/resolv.conf 配置进行DNS查询,但如果你想使用了 HOST 模式,还继续使用 Kubernetes 的DNS服务,那就将 dnsPolicy 设置为 ClusterFirstWithHostNet。
- None:忽略集群DNS策略,需要用户提供dnsConfig字段来指定DNS配置信息。
Autopath会在第一次域名查询失败时切割域名后缀,尝试找到正确的域名,做到2次(1次IPv4,1次IPv6)域名查询获取到正确的解析结果。
- 创建1.16版本的集群时已开启Autopath功能。低版本集群未开启该功能。
- Autopath插件会降低CoreDNS Pod的CPU使用率,但是会增加内存(实测1000节点,10000规模Pod占用不超过100 Mi)。
使用Autopath
3、使用节点级NodeLocal DNSCache
NodeLocal DNSCache以DaemonSet形式部署,会在Kubernetes集群的每个节点上运行一个专门处理DNS查询请求的Pod,该Pod会将集群内部域名查询请求发往CoreDNS,将集群外部请求直接发往外部域名解析服务器。同时能够缓存所有请求。可以被看作是节点级别的高效DNS缓存,能够大幅提高集群整体DNS查询的QP

 浙公网安备 33010602011771号
浙公网安备 33010602011771号